






本篇的写作来源依旧是如下这篇优质稿的学习呀!
零基础入门深度学习(6) - 长短时记忆网络(LSTM)_零基础入门深度学习 长短时记忆网络lstm-优快云博客
放个传送门在这里O(∩_∩)O: 小白学习machine learning的第一天-优快云博客
小白学习machine learning的第二天-优快云博客
小白学习machine learning的第三天-优快云博客
小白学习machine learning的第四天-优快云博客
小白学习machine learning的第五天-优快云博客
小白学习machine learning的第六天-优快云博客
欢迎回来!!!咋们已经在deep learning这条路上走了这么深了呢,今天为大家带来的是长短时神经网络的学习!
一、啥是LSTM长短时记忆网络?
(1)首先,LSTM是为了解决梯度爆炸和梯度消失问题而出现的一种网络形式。
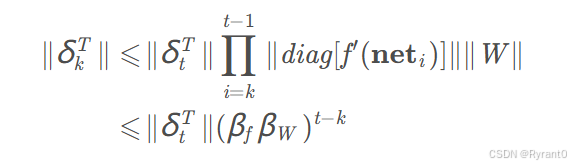
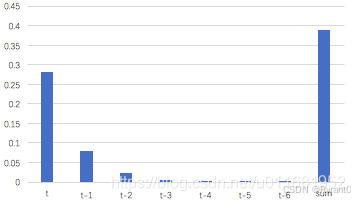
由这个式子我们不难看出,当t − k很大时(也就是误差传递很多个时刻时),整个式子的值就会变得极小(当βfβw乘积小于1)或者极大(当βfβw乘积大于1)。
也就会如下图所示在t - 3时刻后出现得到的梯度不会对最终的梯度值有任何贡献的情况。
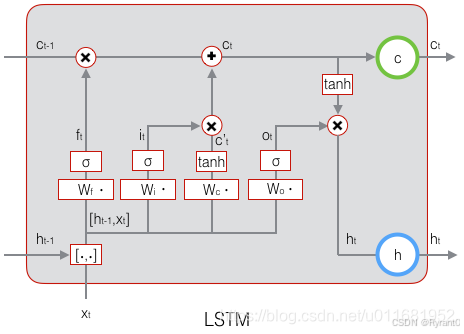
(2)而实际上,LSTM就是将普通的隐藏层多加上了一个状态,使其能够保存长时间的状态而不仅仅是短时的状态。如下图所示:
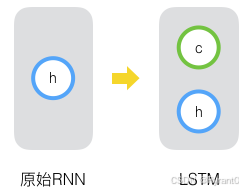
我们把新增的状态c称为单元状态。
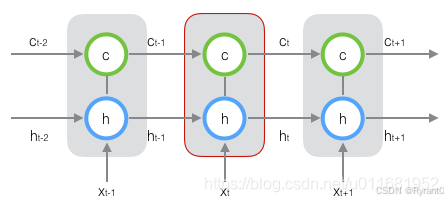
如上图所示,
LSTM的输入有三个:当前时刻网络的输入值xt、上一时刻LSTM的输出值h t − 1 、以及上一时刻的单元状态c t − 1 ;
LSTM的输出有两个h t:当前时刻LSTM输出值c t 、和当前时刻的单元状态。
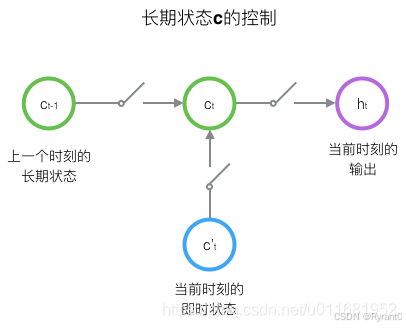
那么,LSTM是怎么控制长期状态c的捏?
第一个开关,负责控制继续保存长期状态c;
第二个开关,负责控制把即时状态输入到长期状态c;
第三个开关,负责控制是否把长期状态c作为当前的LSTM的输出;
二、LSTM的前向传播怎么做呢?
那么,我们该怎么实现开关呢?
这里我们采用门(gate)来实现,门其实就是一个全连接层。输入向量,然后输出一个0 - 1的值,因为使用的是sigmoid激活函数。
公式如下啦:
W是门的权重向量,b是偏置项,σ是sigmoid函数。
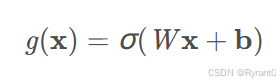
①遗忘门(forget gate):
定义:决定了上一个时刻c有多少状态会继承到下一个状态。
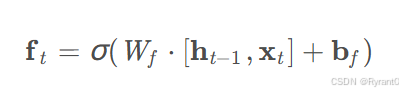
这里,我们对原文进行注释:
[ht−1,xt](h是输出,x是输入)表示把两个向量连接成一个更长的向量,bf是偏置项。如果输入的维度是dx,隐藏层的维度是dh,单元状态的维度是dx(通常dc=dh),则遗忘门的权重矩阵Wf维度是dc×(dh+dx)。事实上,Wf权重矩阵都是两个矩阵拼接而成的:一个是Wfh,它对应着输入项ht−1,其维度为dc×dh;一个是Wfx,它对应着输入项xt,其维度为dc×dx。
公式略微改换形式如下:
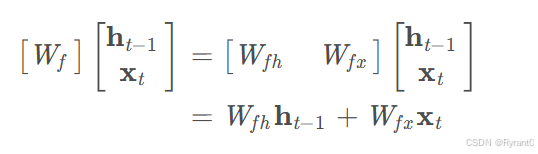
下面是图解喔!
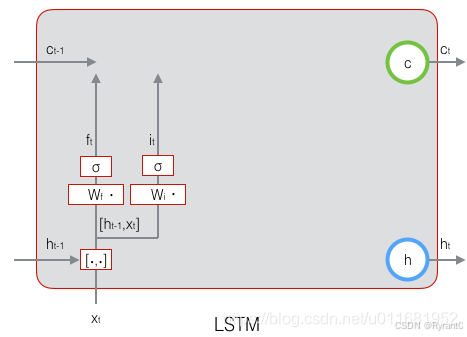
②输入门(input gate):
定义:决定了当前时刻网络的输入xt有多少保存到单元状态ct
![]()
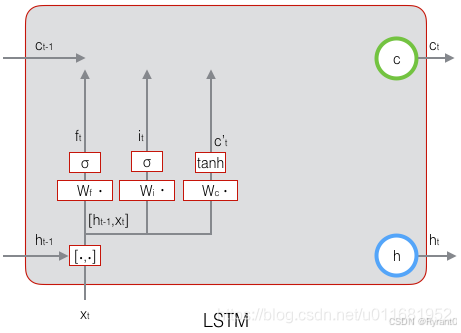
这里,我们考虑~ct作为当前输入的单元状态,它取决于上一次的输出ht - 1和当前的输入xt。
公式如下呀!
![]()
当前时刻的单元状态ct:
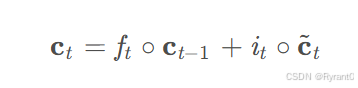
这条公式就是上一次的单元状态ct−1按元素乘以遗忘门ft,再用当前输入的单元状态c~t按元素乘以输入门it,再将两个积加和。
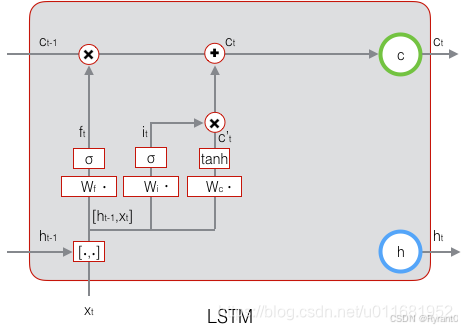
上面两条式子千万不要弄混了呀~~
其实是当前的记忆c~t和长期的记忆ct−1组合在一起,形成了新的单元状态ct!
③输出门(output gate):
如下面两个公式呀:
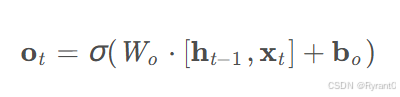
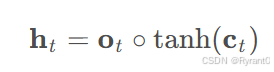
如两个公式所示,这里我们依旧是通过一个由输入和上一层输出决定的ot和状态ct来计算得出输出ht,看图我们能更清晰的得到直观感受!
补充这2个激活函数:
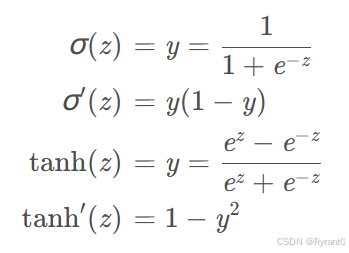
三、LSTM的训练咋搞啊?
这里,我们来看看作者所给出的训练办法,我们仍旧采用反向传播算法来进行训练:

可以看到,方法答题步骤是相似的,我们来看看细节吧!
(1)首先,我们来看看有什么是需要学习的:
- 遗忘门的权重矩阵Wf和偏置项bf
- 输入门的权重矩阵Wi和偏置项bi
- 输出门的权重矩阵Wo和偏置项bo
- 计算单元状态的权重矩阵Wc和偏置项bc
需要注意的是,每一个门的权重矩阵W的值应当由两个,因为输入向量和上一次的输出向量所乘的权重并不相同呀!
原文补充了一点线性代数的公式,即乘以矩阵可看作是乘上对角线上的值
(2)误差项的计算
这里,我们给出误差项的计算公式:
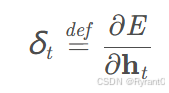
与之前网络不同的是,我们这里假设误差项是损失函数对输出值的导数,而不是对加权输入net(ti)的导数,因为加权输入net(ti)有4个,而我们需要向上传递一个误差项而不是四个。
4个误差项如下:
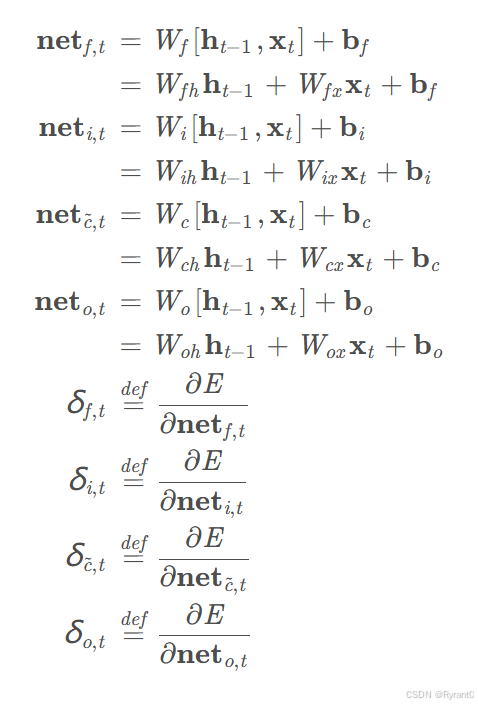
(3)误差项沿时间的反向传播
借鉴于原文的数学计算(感兴趣可以参考原文哦!),我们给出计算误差项在各个时间的计算公式呀:
原始计算公式(t - 1时刻):
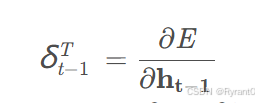
最终结果公式:
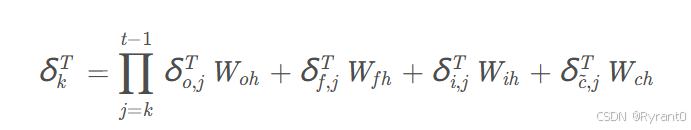
(4)误差项传递到上一层
原始计算公式:
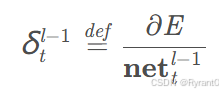
数学计算后的结果公式:
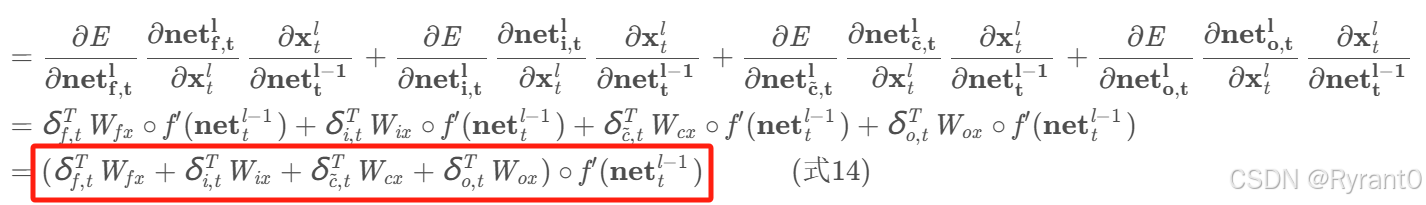
(5)权重梯度的计算
其实有了误差项的各种计算公式,梯度已经算出来了呀!
①W的梯度:
![]()
(h上一层输出量相关哦)
将各个时刻的W相加,就得到了W的梯度:
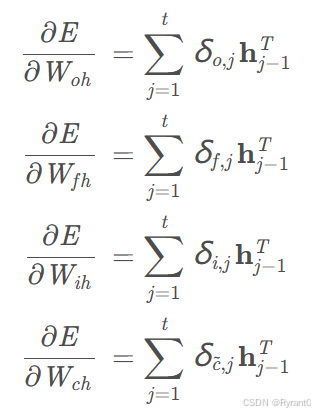
②偏移量(bias)的梯度:
相同的是,各个时刻的B相加,得到B的梯度:
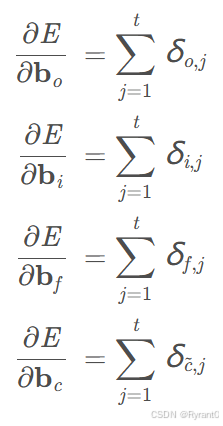
③对于W的梯度:
![]()
(x输入量相关哦)
仍旧是各个时刻的W相加:
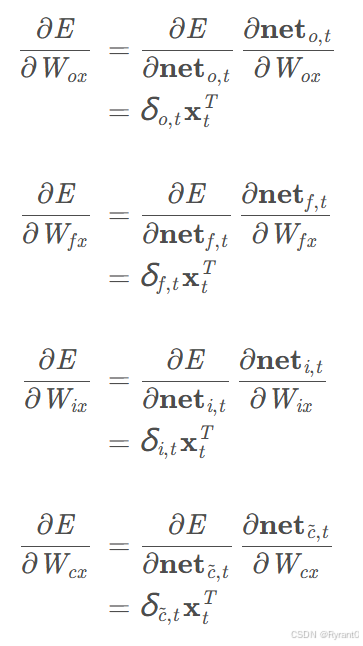
这里奉上原作者在GitHub的源代码: https://github.com/hanbt/learn_dl/blob/master/lstm.py (python2.7)
四、一些LSTM变体——GRU
首先,咋们就来看看图示:
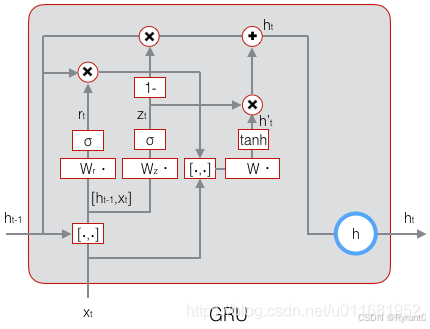
我们来瞅瞅哪里做出了改变:
- 将输入门、遗忘门、输出门变为两个门:更新门(Update Gate)和重置门(Reset
Gate) - 将单元状态与输出合并为一个状态:h 。
这是很明显的简化了,但是如图也能完成LSTM的任务!!!
这里给出图示的公式:
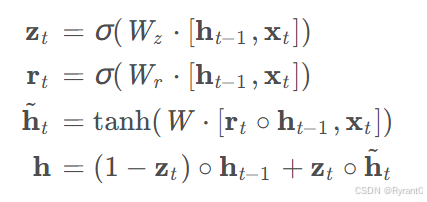
亲爱的读者,到这里就结束啦!现在我们又将一个新的工具——长短时记忆网络装入我们的工具箱中啦!恭喜自己也恭喜你呀!!O(∩_∩)O

















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









