




 本文提出了一种分层语义对比方法,通过结合预先训练的视频解析模型和自动编码器的重建框架,提升了视频异常检测(VAD)在处理场景相关异常的能力。方法利用场景和对象级对比学习,有效区分正常模式和异常,且通过运动增强处理罕见的正常活动,实现在多个数据集上的有效性能。
本文提出了一种分层语义对比方法,通过结合预先训练的视频解析模型和自动编码器的重建框架,提升了视频异常检测(VAD)在处理场景相关异常的能力。方法利用场景和对象级对比学习,有效区分正常模式和异常,且通过运动增强处理罕见的正常活动,实现在多个数据集上的有效性能。
提高场景感知能力是视频异常检测 (VAD) 的一个关键挑战。在这项工作中,我们提出了一种分层语义对比(HSC)方法,用于从普通视频中学习场景感知VAD模型。我们首先利用预先训练的视频解析模型,将前景对象和背景场景特征与高级语义相结合。然后,在基于自动编码器的重建框架的基础上,我们引入了场景级和对象级对比学习,以强制编码的潜在特征在相同的语义类中是紧凑的,同时在不同的类中是可分离的。这种分层语义对比策略有助于处理正常模式的多样性,并提高其辨别能力。此外,为了解决罕见的正常活动,我们设计了一种基于骨架的运动增强,以增加样本并进一步完善模型。在三个公共数据集和场景相关混合数据集上进行了大量实验,验证了所提方法的有效性。
工作贡献
我们工作的主要目标是处理与场景相关的异常。场景相关异常背后的直觉是,如果从未在在正常视频中的一个场景中观察到某种类型的物体或活动,那么它应该被视为异常。这意味着我们可以先确定场景类型,然后检查某个对象或活动是否在该场景的正常模式发生。基于这一观察结果,我们提出了一种分层语义对比方法来学习场景感知VAD模型。利用预先训练的视频解析网络,我们将对象和背景场景的外观和活动分组到语义类别中。然后,基于自动编码器的重建框架,我们设计了场景级和对象级对比学习,以强制编码的潜在特征根据其语义类别聚集在一起,如图 1 所示。当输入测试视频时,我们检索加权的正常特征进行重建,并将高误差的片段检测为异常。

图 1.分层语义对比模型的图示。编码的场景-外观/运动特征根据其语义类别聚类。
-
构建场景感知重建框架,由场景感知特征编码器和以对象为中心的特征解码器组成,用于异常检测。场景感知编码器将背景场景考虑在内,而以对象为中心的解码器则用于减少背景噪声。
-
我们提出了分层语义对比学习,将潜在空间中的编码特征进行正则化,使正常特征在相同的语义类中更加紧凑,并且在不同类之间是可分离的。因此,它有助于将异常与正常模式区分开来。
-
我们设计了一种基于骨架的增强方法,基于我们的场景感知 VAD 框架生成正常和异常样本。 增强的样本使我们能够额外训练一个二元分类器,这有助于进一步提高性能。
-
在三个公共数据集上的实验表明,在与场景无关的 VAD 上取得了有希望的结果。此外,该方法在自建数据集上也显示出较强的场景相关异常检测能力。
3. 所提出的方法
下图概述了所提出的方法。当输入一个视频片段(即一组连续的帧)时,我们首先对其进行解析,以获得高级语义特征,包括物体的外观和运动,以及背景场景。然后,将每个对象的外观或运动特征与场景特征合并。将获取的场景外观和场景运动特征输入到场景感知编码器和以对象为中心的解码器中,进行特征编码和重构。所有编码的潜在特征都存储在外部存储器库中,在此基础上我们进行场景和对象级语义对比学习。分层对比学习迫使不同的潜在正态特征在相同的语义类内是紧凑的,并且在不同的类之间是可分离的,从而提高了正态模式的辨别能力。在推理过程中,对存储在内存中的正常特征进行检索和加权,以重建测试片段中对象的特征,并将误差较大的特征检测为异常。
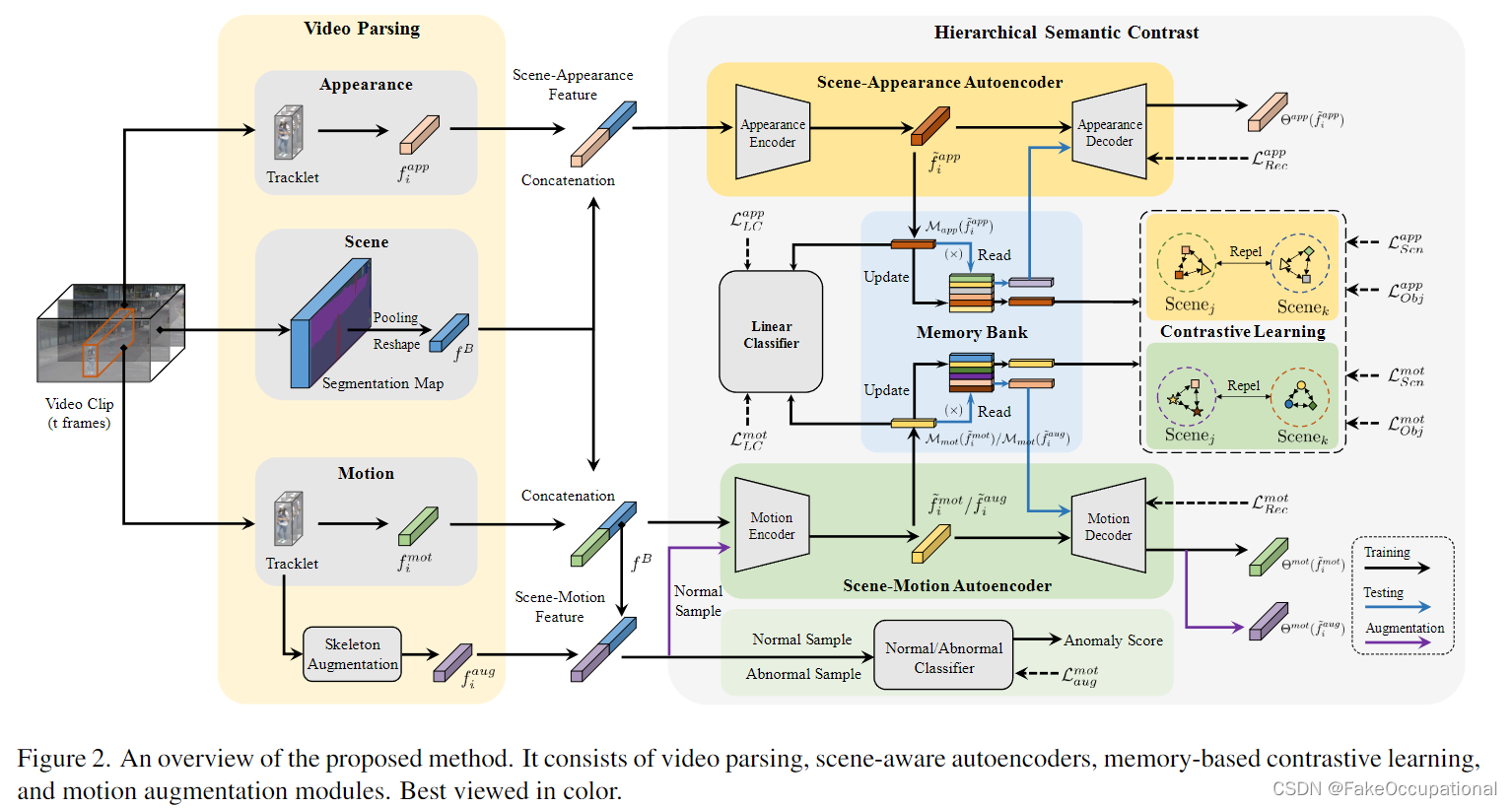
3.1. 视频解析
预训练的视频解析网络广泛用于许多 VAD 方法以提取不同的视觉线索。在这项工作中,我们利用几个预先训练的网络来提取高级特征,同时引入语义标签。
给定一个由T个连续帧组成的视频片段C,我们首先采用预训练的YOLOv3 和FairMOT来检测和跟踪物体,以产生多个物体轨迹及其语义类标签,如行人、自行车等。然后,我们为每个对象轨迹提取外观和运动特征,并为剩余背景提取场景特征。
外观特征提取
外观信息在检测外观异常方面起着重要作用。因此,对于视频片段中的对象轨迹OiO_iOi,我们采用ViT[8]为轨迹的每一帧提取一个外观特征,并将所有帧的特征平均,以生成一个外观特征fiapp∈R1024f_i^{app} ∈ R^{1024}fiapp∈R1024。
运动特征提取
运动信息在 VAD 中同样重要。考虑到与人类相关的异常在非交通监控中占主导地位,我们选择将动作信息提取为运动特征,而不是使用光流。更具体地说,对于对象轨迹OiO_iOi,我们使用预训练的HRNet [54]来提取每一帧的骨架特征。所有帧的特征被进一步输入到 PoseConv3D [10] 中,以生成一个运动特征fimot∈R512f_i^{mot} ∈ R^{512}fimot∈R512,以及一个动作类标签,如行走、跳跃、踢腿等。
场景特征提取
为了追求场景感知,我们还为视频片段背景提取了一个场景特征。对于每个视频片段,我们使用 DeepLabV3+ [6] 生成分割图,同时屏蔽前景对象类别。然后,我们对所有分割图进行最大池化、重塑、平均化和归一化,以获得一个场景特征 fB∈RDBf^B∈ R^{D_B}fB∈RDB,其中DB{D_B}DB取决于视频帧的大小。为了在细粒度上区分不同的场景,我们利用DBSCAN [11]对场景类进行聚类和生成伪标签。
3.2. 语义特征重构
在这项工作中,我们采用了广泛使用的重构框架进行异常检测。对于每个外观或运动特征,我们设计了一个由场景感知编码器和以对象为中心的解码器组成的自动编码器,用于特征重建。
场景感知特征编码器
为了将前景对象与背景场景相关联,我们将每个外观/运动特征与其相应的场景特征合并在一起。获得的场景外观或场景运动特征被馈送到场景感知特征编码器中。从形式上讲,它由以下形式表示
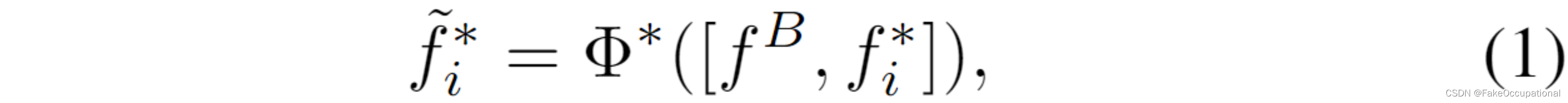
其中 fi∗ ~∈RDE\tilde { \ f_i^* \ } ∈R^{D_E} fi∗ ~∈RDE是视频片段C中对象OiO_iOi的编码潜在特征,“∗”表示app或mot,DED_EDE表示特征维度。此外,[·,·] 表示串联,Φ∗(⋅)Φ^*(·)Φ∗(⋅) 是特征编码器,它由两层 MLP 和l2l_2l2 normalization 实现。
以对象为中心的特征解码器
基于重建的框架假设异常不能用正常模式很好地表示。为了减少重建中的背景偏差[31],我们选择重建每个前景对象的特征,而不是合并的场景感知特征。 也就是说,给定一个潜在特征f~i∗\tilde f_i^*f~i∗,我们强制解码器重建一个接近外观/运动特征的特征fi∗f_i^*fi∗,即
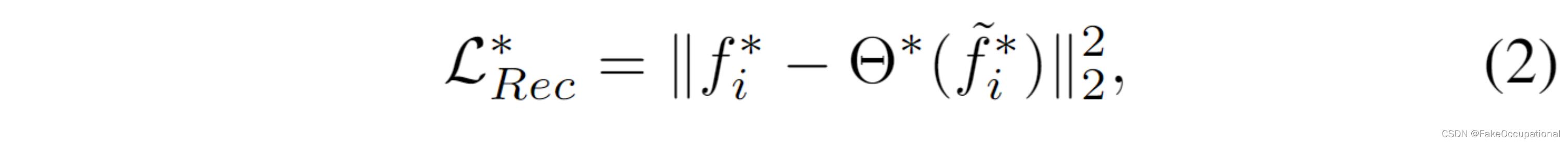
其中 ∥·∥ 是 lnorm。Θ也是由两层MLP实现的特征解码器。
3.3. 层次语义对比
由于正常模式的多样性以及深度网络的大容量,从正常数据中学习的模型也可以很好地重建异常[18,44]。为了解决这个问题,我们提出了一种分层语义对比(HSC)策略,将潜在空间中的编码正常特征进行正则化,从而可以更紧凑地表示不同的正常模式,从而更能区分异常。HSC 通过利用视频解析中引入的语义标签,在场景和对象级别进行对比学习。
场景级对比学习
场景级对比学习旨在吸引同一场景类中的潜在特征,排斥不同场景的特征。为此,我们采用InfoNCE损失[7,66]进行学习,并由外部存储器库辅助。场景级对比度损失由下式定义:
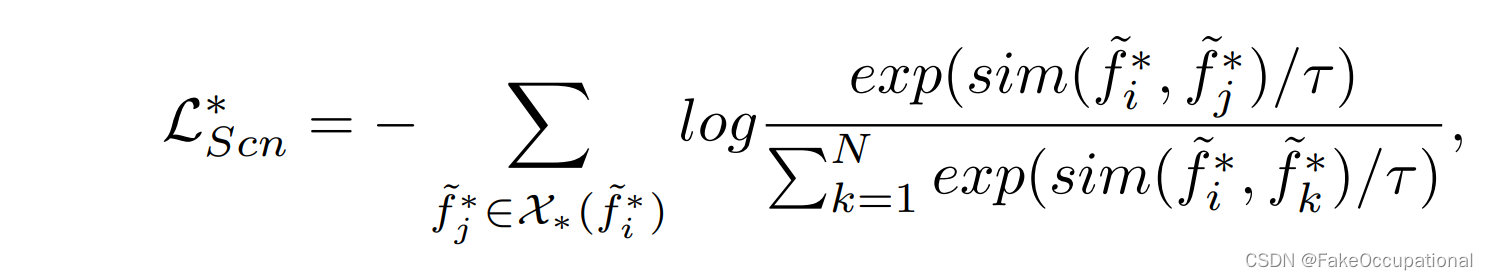
其中 N 是所有编码潜在特征的数量,X(f~)X(\tilde f )X(f~) 表示与f~\tilde ff~共享同一伪场景标签的特征集,τ 是温度超参数,sim(·, ·) 表示余弦相似度。
此外,我们还构建了一个线性分类(LC)头,通过使用交叉熵损失将每个潜在特征分类到其伪场景类中:
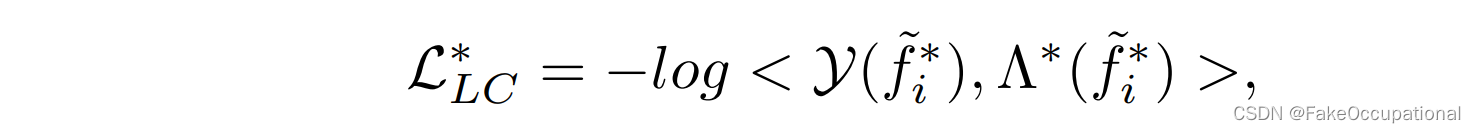
式中<·、·>表示点积,Λ(·)为线性分类器,Y表f~i∗\tilde f_i^*f~i∗的伪场景标签。
对象级对比学习
在每个场景类中,对象级对比学习将同一外观/运动类别的潜在特征拉到一起,并推开来自不同外观/运动类别的潜在特征。因此,对象级对比损失的定义如下:
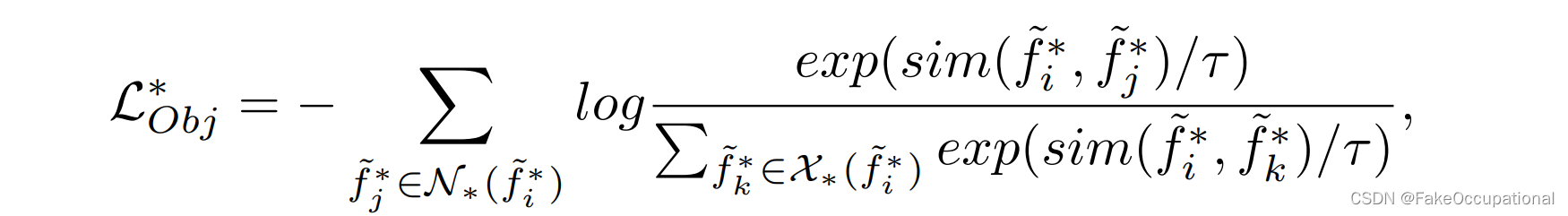
其中N(f~)N(\tilde f )N(f~) 表示与f~\tilde ff~共享相同外观/运动类和相同场景类的潜在特征集。请注意,在此损失中,仅考虑同一场景类中的要素,而忽略所有其他要素。
内存库
与利用记忆学习自动编码器的记忆增强AE [18,44]相比,我们主要使用记忆进行对比学习。为此,构建了两个存储库,分别用于存储潜在的场景外观和场景运动特征。每个条目都以如下方式更新,然后进行l2 normalization:
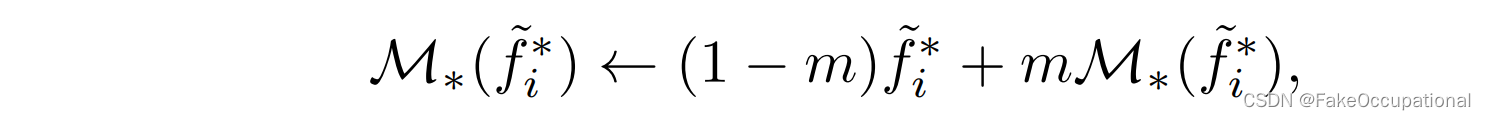
3.4. 运动增强
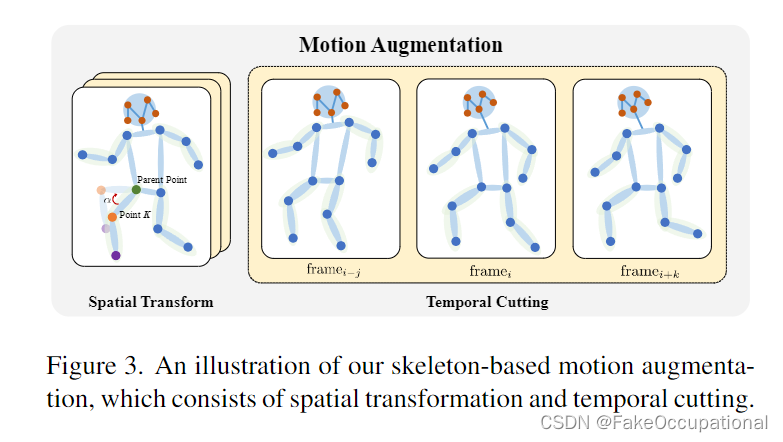
罕见但正常活动的发生是VAD的一个挑战[46]。与场景无关的情况相比,这一挑战在场景相关异常检测中尤为突出。原因是从不同场景收集的正常样本不再一起计算。为了解决这个问题,我们设计了一种基于骨架的增强来产生更多的样本,其中包括空间变换和时间切割,如图3所示。
空间转换。从一个对象帧中提取的骨骼特征包含一组人体解剖学关键点,包括肩部、肘部、手腕等。在这项工作中,我们设计了一种基于旋转的增强方案。对于每个关键点 K(头上的关键点除外),我们设置一个概率 P 来决定关键点是否旋转。如果选择关键点 K 进行旋转。
时间切割。一个动作不仅通过关键点的空间分布来识别,还通过时间分布来识别。在这项工作中,我们简单地采用了时间增强的切割策略。也就是说,给定一个对象轨迹的帧,我们为每个帧设置一个概率 P,以决定它是否被遗漏。
时空增强。为了增加运动样本的多样性,我们将空间变换和时间切割结合在一起作为我们的时空增强。给定一个物体轨迹,我们应用时空增强来产生一组新的骨架特征,然后将它们输入PoseConv3D [10],以获得增强样本的运动特征。
3.5. 训练和测试
Training
完整模型的训练损失包含外观流损失LappL^{app}Lapp和一个运动流损失LmotL^{mot}Lmot。也就是说,总损失的定义如下:
L=Lapp+LmotL =L^{app}+L^{mot}L=Lapp+Lmot
在这里,每个流的损失由两个对比损失组成,以及一个分类损失和一个重建损失(*代表app或者mot)。
L∗=LScn∗+LObj∗+LLC∗+LRec∗L^* = L^*_{Scn}+L^*_{Obj}+L^*_{LC}+L^*_{Rec}L∗=LScn∗+LObj∗+LLC∗+LRec∗
在训练的第一阶段,我们使用损失L在原始数据集上训练我们的模型,而无需运动增强。一旦模型被训练,我们就会考虑增强样本进行细化。由于运动增强中生成的样本不能保证是正常的,因此我们应用经过训练的模型,根据方程(11)中定义的重建误差来区分正常和异常样本。然后,我们利用正常和异常样本,使用交叉熵损失LaugmotL_{aug}^{mot}Laugmot在运动流上额外训练二元分类器。
Test
在推理期间,我们应用视频解析模型来获取每个测试视频片段的高级特征。然后,将每个测试特征f~t∗\tilde f^*_tf~t∗输入到外观/运动流中进行编码和重建。让我们将编码的潜在特征表示为f~t∗\tilde f^*_tf~t∗ 。与直接重构潜在特征的训练不同,我们计算它与存储在内存 M∗M_*M∗ 中的每个条目之间的相似度:
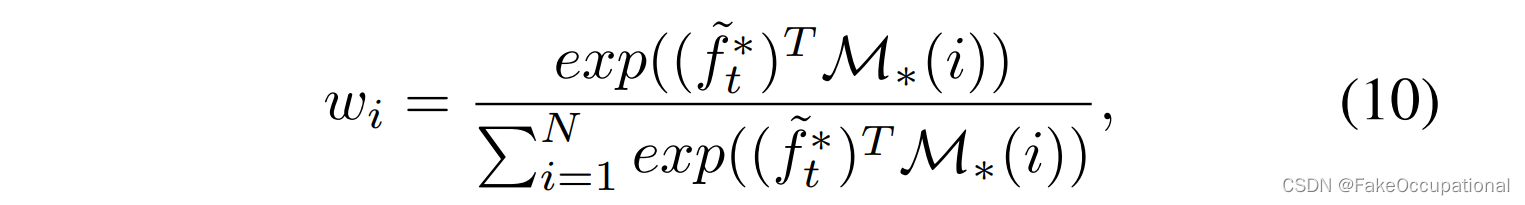
并获取所有存储的正常特征的加权平均值以进行重建。因此,一个流的重构误差由下式定义
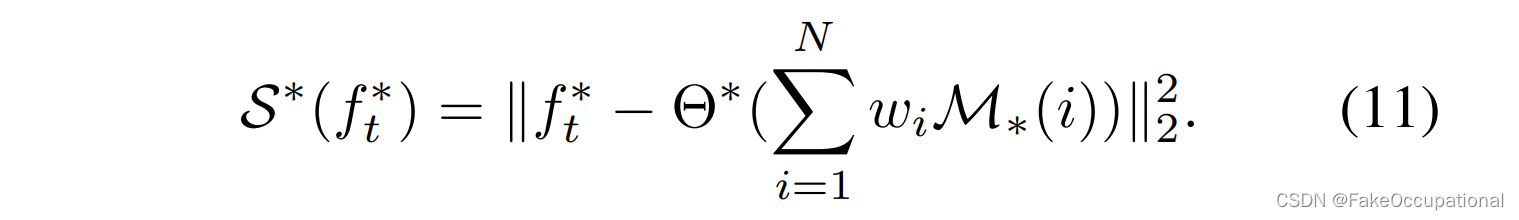
对象的最终异常分数定义为两个流的平均重建误差,即
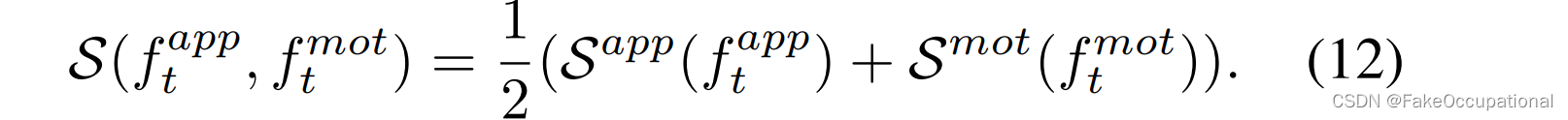
当考虑运动增强时,运动流的异常分数将替换为二元分类器输出的异常概率。此外,剪辑的异常分数由该剪辑中对象的最高最终异常分数决定。最后,我们应用高斯滤波器对所有视频剪辑进行时间平滑处理。
4. 实验
4.1. 数据集和评估指标
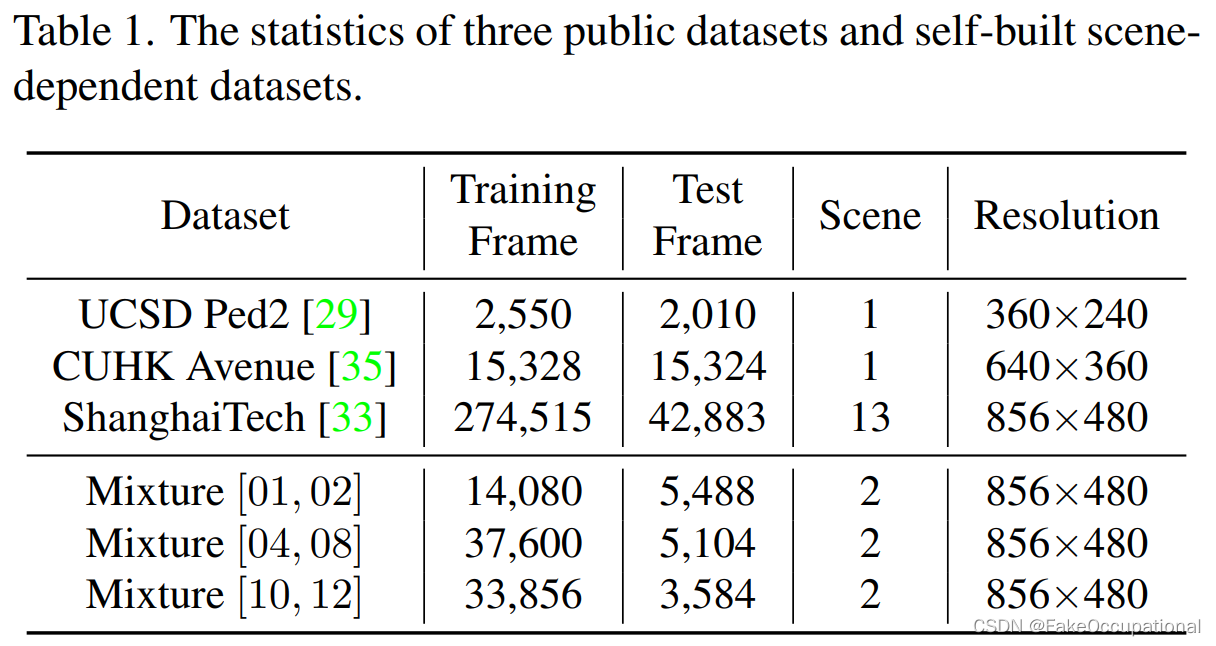
我们在三个公共数据集上评估了所提出的方法:UCSD Ped2 [29]、Avenue [35] 和上海科技大学 [33]。UCSD Ped2 [29]是一个从人行道上收集的单场景数据集,包括骑自行车的人、溜冰者、人行道上的小推车等异常情况。Avenue [35]也是一个单场景数据集。它被拍摄到中大校园大道,包含跑步、骑自行车等异常情况。它还包含一些罕见的正常模式[35]。上海科技大学[33]是一个具有挑战性的多场景数据集,包含13个具有不同光照条件和摄像机角度的校园场景。这些数据集的统计数据汇总于表1中。
但是,这三个数据集包含的场景相关异常很少。据我们所知,没有可用的公共场景相关异常数据集。为了研究我们的方法在场景相关异常检测方面的性能,我们另外创建了三个基于上海科技大学的混合数据集。混合集 [01, 02] 由从场景 01 和 02 拍摄的视频组成。我们将包含骑行者事件的场景 01 的部分测试视频选入混合训练集,并将其从测试集中删除。这意味着骑车人在场景 01 中是正常的,但在场景 02 中仍然是异常的。同样,我们得到一个混合集合 [04, 08] 和一个集合 [10, 12],其中某些事件在一个场景中是正常的,但在另一个场景中是异常的。更多详细信息在我们的补充材料中提供。
对于性能评估,我们采用帧级接收机工作特征(ROC)的曲线下面积(AUC)作为评估指标,遵循通常的做法[2,4,12,17,18,38,45,62]。它连接所有帧,然后计算分数,也称为微平均AUC[17]。
4.2. 实现细节
我们在 Pytorch 中实现了所提出的方法。我们模型中涉及的超参数设置如下。编码潜在特征的维数为 D= 1280。对比学习中的温度因子为 τ = 0.5,记忆更新中的动量系数为 m =0.9. 用于运动增强的概率设置为 P= P= 0.5。此外,我们的模型使用 AdaGrad 优化器进行训练,UCSD Ped2 和 Avenue 的学习率为 0.01,批量大小为 128,上海科技大学为 512。我们的补充材料中提供了其他一些详细信息。
4.3. 消融研究
虽然所提出的方法针对的是场景相关的 VAD,但它也适用于与场景无关的异常。因此,我们主要在Avenue和ShanghaiTech上进行消融研究,部分在混合数据组上进行消融研究。
拟议组成部分的有效性
我们首先验证我们提议的组件的有效性。我们将整个模型分解为场景外观自动编码器 (SA-AE)、场景运动自动编码器 (SM-AE) 和基于记忆的对比学习 (MemCL),以及场景运动增强 (MA) 组件。表2报告了持有不同组件的模型变体的性能。从结果中,我们观察到,当只学习单个流并且两个流的组合性能更好时,SA-AE 的性能优于 SM-AE 或 SM-AE+MA。此外,基于记忆的对比学习使模型的性能大大优于同类模型。运动增强还提高了两个数据集的性能,尤其是在包含罕见正常活动的 Avenue 数据集上。

场景感知 AE 和 HSC 的有效性
我们在这里更深入地研究上述组成部分进行调查。更具体地说,我们检查了自动编码器中场景感知特征编码器 (SA-E) 和以对象为中心的特征解码器 (OC-D) 的有效性,以及分层语义对比 (HSC) 中使用的对比损失。我们在不使用运动增强的情况下对模型进行了一系列实验。结果如表3所示。结果表明,当不应用对比学习时,场景感知特征编码器在与场景无关的Avenue和ShanghaiTech上略微降低了性能,但在场景相关混合集上提高了性能。此外,以对象为中心的解码器提高了所有数据集的性能,因为避免了重建中的背景噪声。在 HSC 中,场景或对象级别的个体对比学习可以持续提高性能,这表明有必要在潜在空间中正则化编码特征。当损失协同工作时,可以实现最佳性能。
测试时内存大小的影响
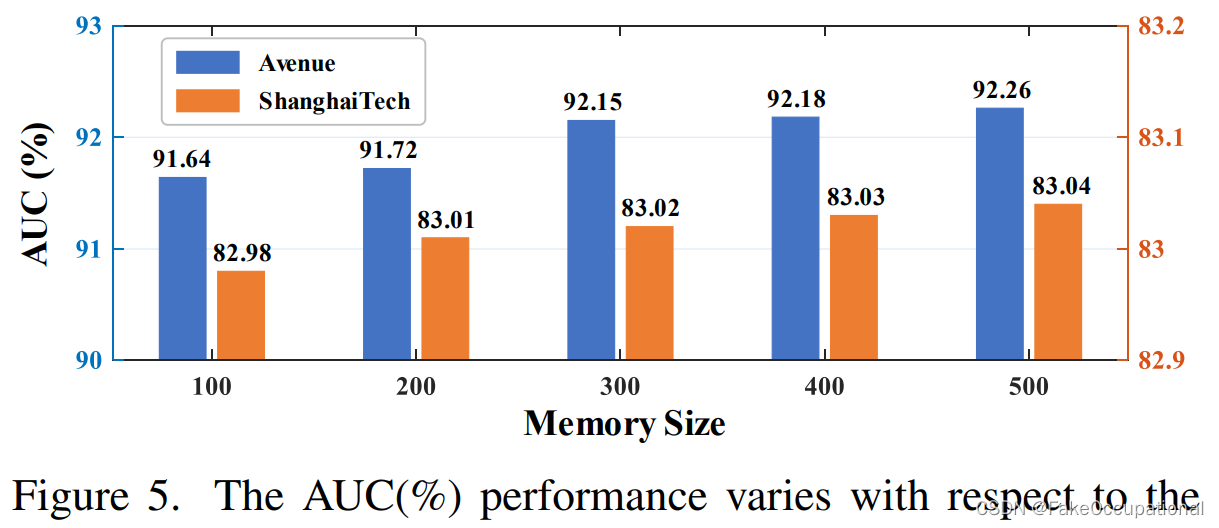
我们工作中的记忆用于训练期间的分层语义对比和测试时的特征重建。为了使我们的模型更紧凑、更高效地进行推理,我们可以通过保留一小部分正常模式来减小内存大小。在这个实验中,我们随机选择一些条目,并在测试时丢弃剩余的条目。 图 5 说明了性能随内存大小的变化而变化。它表明即使只保留 500 个条目,性能也能保持良好,而当只保留 100 个条目时,性能只会稍微下降。
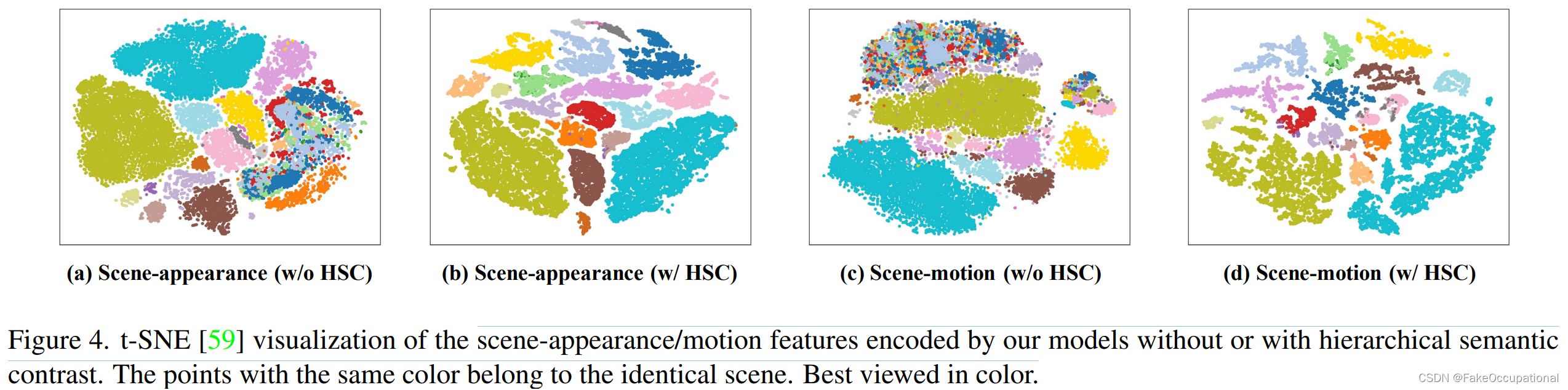
4.4. Visualization
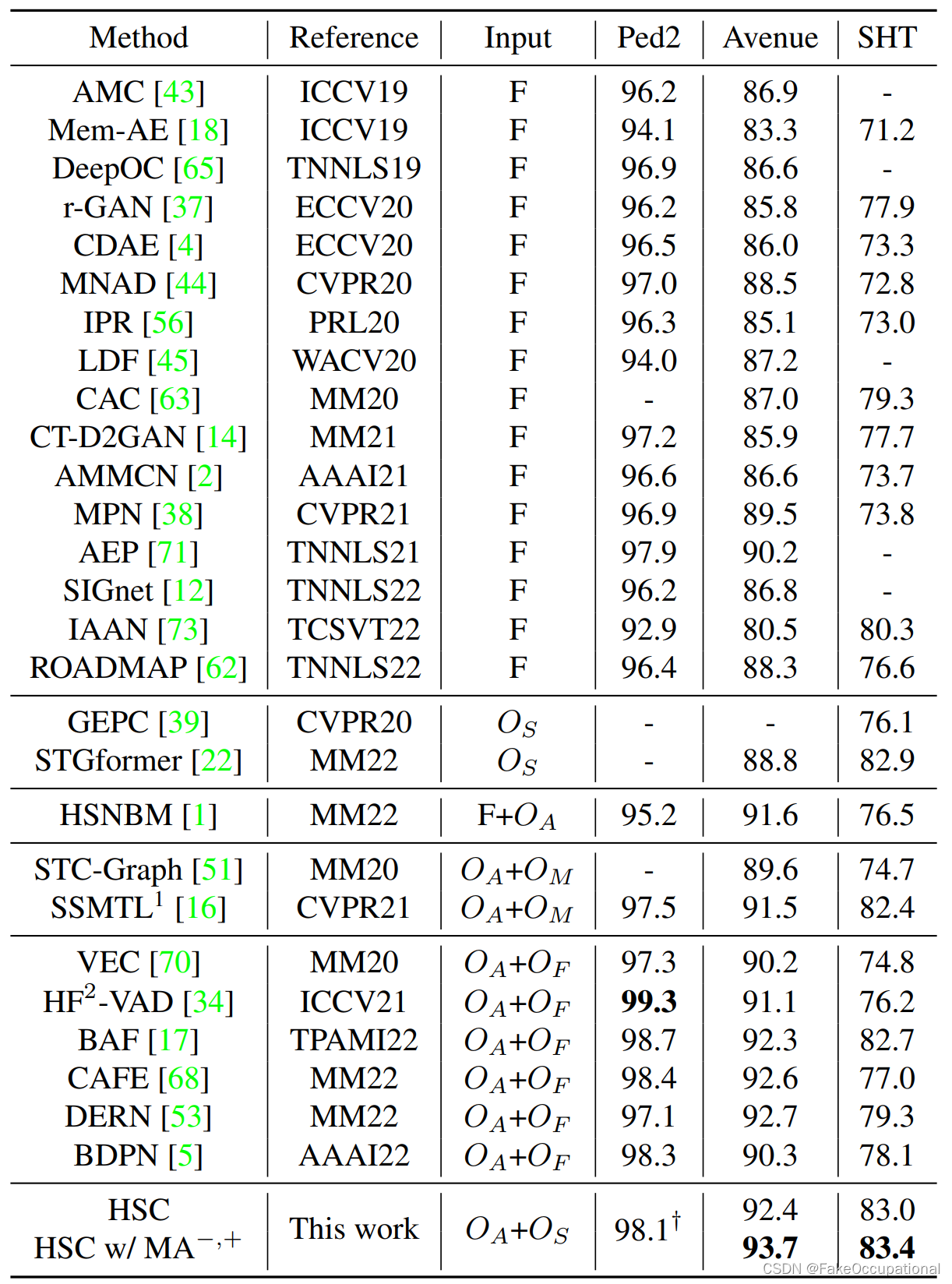
4.5 与最新技术的比较
UCSD Ped2(Ped2)、CUHK Avenue (Avenue)和 ShanghaiTech(SHT)的比较结果如表所示。除了帧级微平均AUC(%)性能外,我们还列出了方法的输入,其中“F”表示帧级输入,“O”表示以对象为中心。
下标“A”为外观,“F”为光流,“S”为骨架,“M”为其他运动信息。此外,在我们的 HSC 模型中,MA表示使用运动增强来生成正常和异常样本。

















 1528
1528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









