




目录
Abstract
在针对高分辨率移动视觉应用时,ViT不如卷积神经网络(CNNs)。
现有的方法(如Swin、PVT)限制了局部窗口内的softmax attention,或降低键/值张量的分辨率,以降低成本,这牺牲了ViT在全局特征提取方面的核心优势
我们提出用线性注意代替softmax attention,同时用深度卷积提高其局部特征提取能力。
1 Introduction
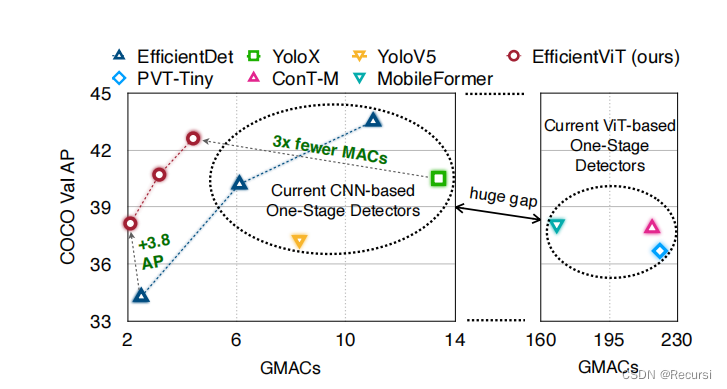
例如,图1(左)比较了COCO数据集上当前基于cnn和基于vit的单阶段检测器
 本文探讨了在高分辨率移动视觉任务中,ViT模型相对于CNN的不足,以及现有优化方法的局限性。研究提出用线性注意力替代softmax注意力,以减少计算成本并保持全局特征提取能力。同时,通过引入深度卷积增强线性注意力,弥补其在局部特征提取上的弱点。实验结果显示,这种方法显著提高了模型在高分辨率输入下的性能,特别是在处理局部特征时。
本文探讨了在高分辨率移动视觉任务中,ViT模型相对于CNN的不足,以及现有优化方法的局限性。研究提出用线性注意力替代softmax注意力,以减少计算成本并保持全局特征提取能力。同时,通过引入深度卷积增强线性注意力,弥补其在局部特征提取上的弱点。实验结果显示,这种方法显著提高了模型在高分辨率输入下的性能,特别是在处理局部特征时。
目录
在针对高分辨率移动视觉应用时,ViT不如卷积神经网络(CNNs)。
现有的方法(如Swin、PVT)限制了局部窗口内的softmax attention,或降低键/值张量的分辨率,以降低成本,这牺牲了ViT在全局特征提取方面的核心优势
我们提出用线性注意代替softmax attention,同时用深度卷积提高其局部特征提取能力。
例如,图1(左)比较了COCO数据集上当前基于cnn和基于vit的单阶段检测器
 7315
6740
1293
7315
6740
1293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























