



论文:
Rethinking Data Selection at Scale: Random Selection is Almost All You Need
背景:
现在,一些SFT技术,主要目标是在较大的数据池中选择一个较小但具有代表性的子集数据,以便使用该子集进行微调可以实现与使用整个数据集相当甚至更好的结果。然而,大多数现有的数据选择技术都是为小型数据池设计的,无法满足现实世界中SFT场景的需求。如这个论文:Selecting influential data for targeted instruction tuning。
结论:
- 目前,各种在小规模数据上筛选数据的各种策略,并不比在大规模的数据集上随机的效果好太多
- 多样重要性大于质量
- 最后,我们发现了过滤按令牌长度的数据为改进结果提供了一种稳定有效的方法
数据选择的方式:
外部打分方式:Extenral-scoring methods
利用GPT4o进行打分
自打分方式:Self-scoring methods,利用需要微调的大模型自身作为数据打分器(主要省钱)
LESS
IFD
SelectIT DiverseEvol
ZIP
后面主要研究基于自打分方式
动机:
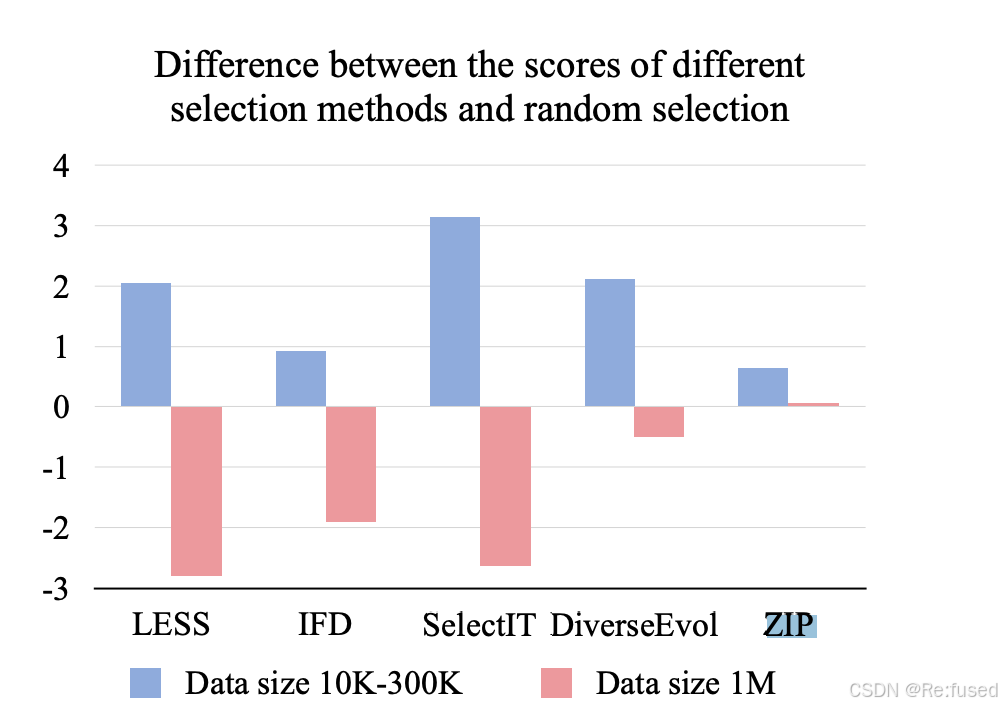
y轴表示差异分数,通过减去随机值来计算的。
随着数据规模增加,数据选择的策略,并没有比随机的效果好
数据集:
经典的数据集alpaca,规模比较小52k,本文选择两个百万级别的数据集:
Openhermes2.5
WildChat-1M
实验结果:
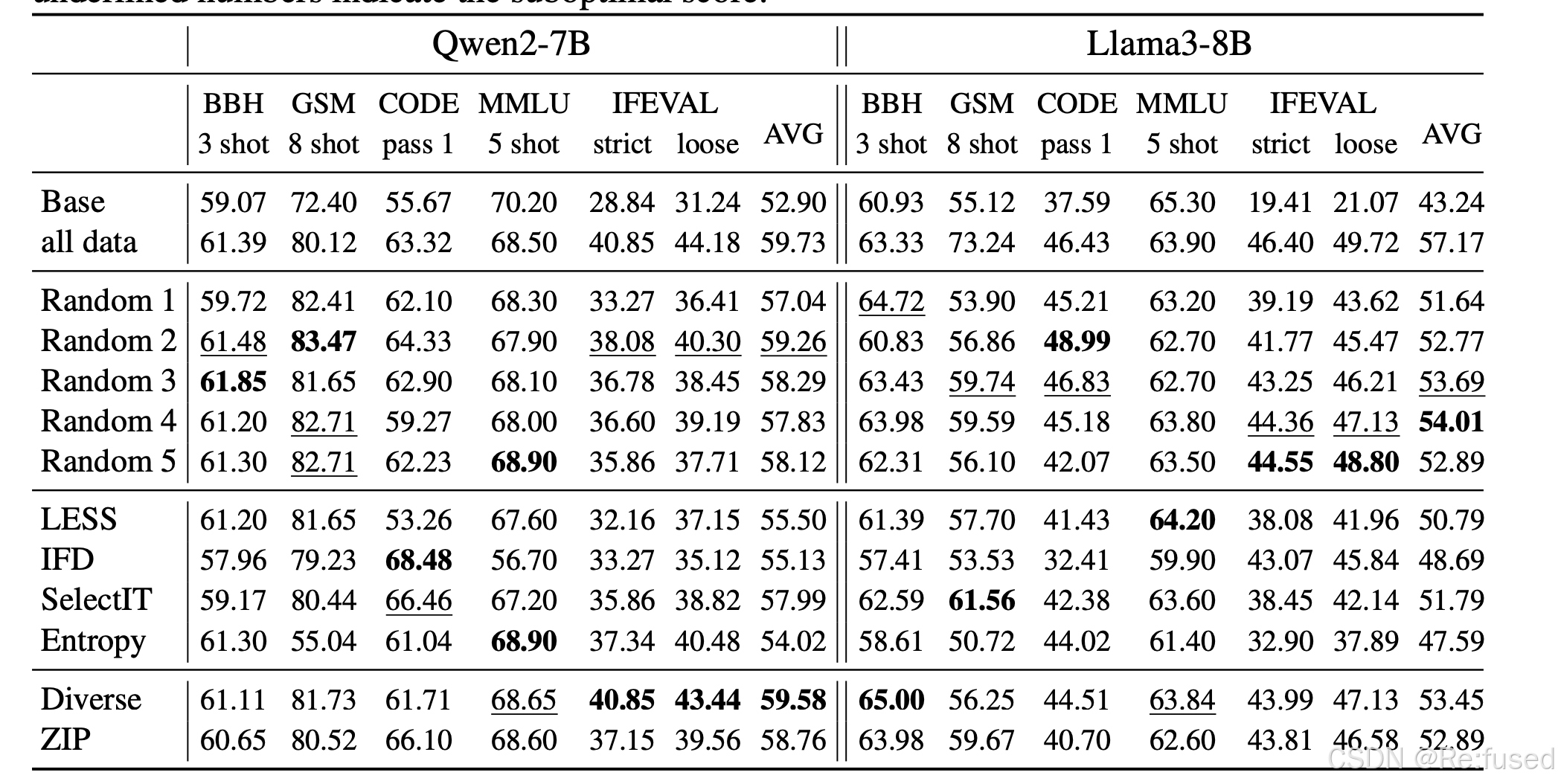
Openhermes2.5 dataset
WildChat dataset
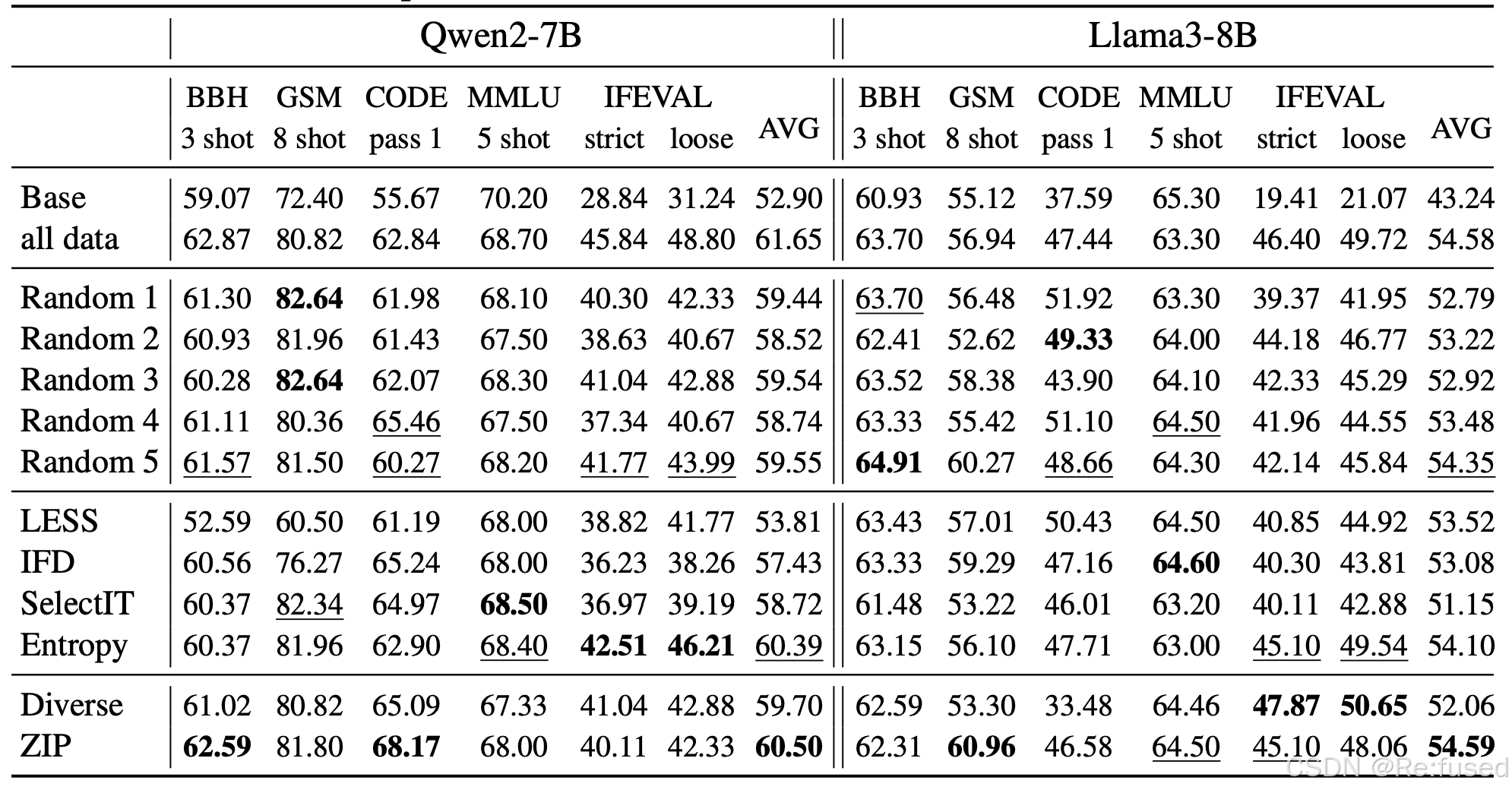
当处理一个广泛的SFT数据集时,随机选择训练数据比花费大量的时间和资源来选择训练数据更有效精心选择看似最优的训练数据
QUALITY VS DIVERSITY
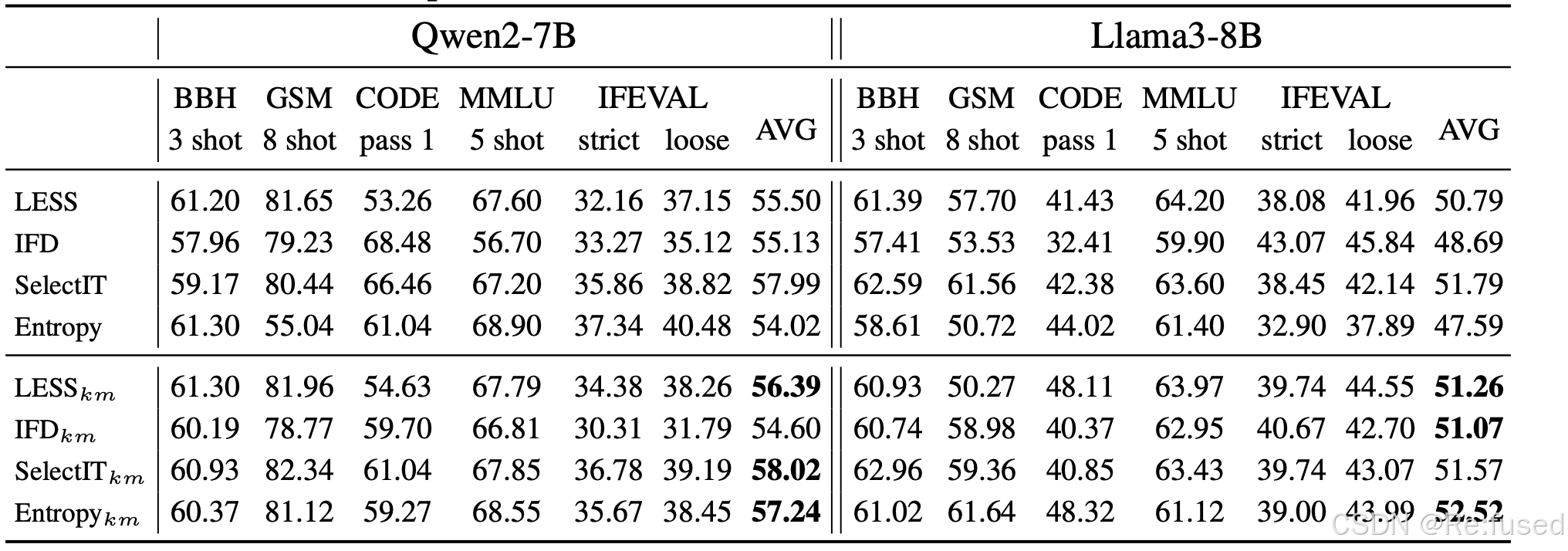
采用k-means方式,融合k-means和自评分的方式,选择每个簇里面得分最大的结果
k-means能够增强大部分方法,这表明数据的多样性大于质量
WHICH METHOD IS THE BEST?
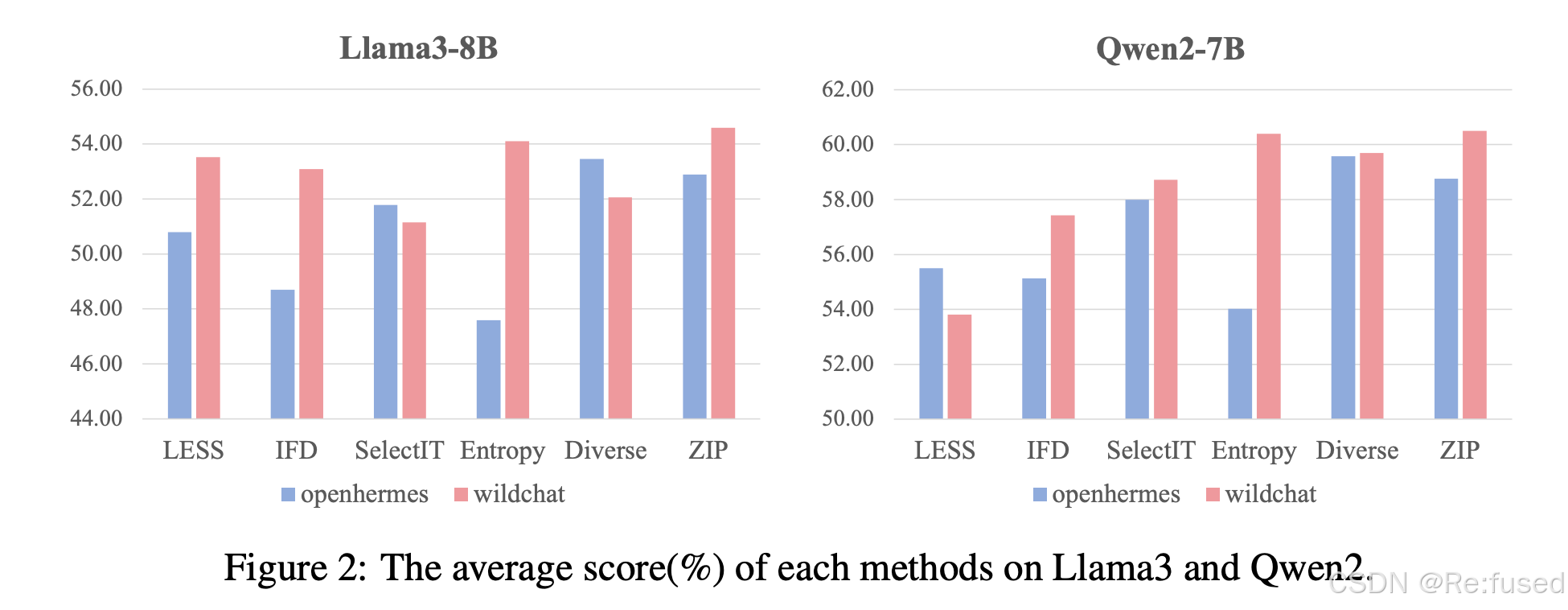
OpenHermes的数据质量高于WildChat, 但是OpenHermes的效果却低于WildChat
WildChat data平均长度1142
OpenHermes data平均长度354
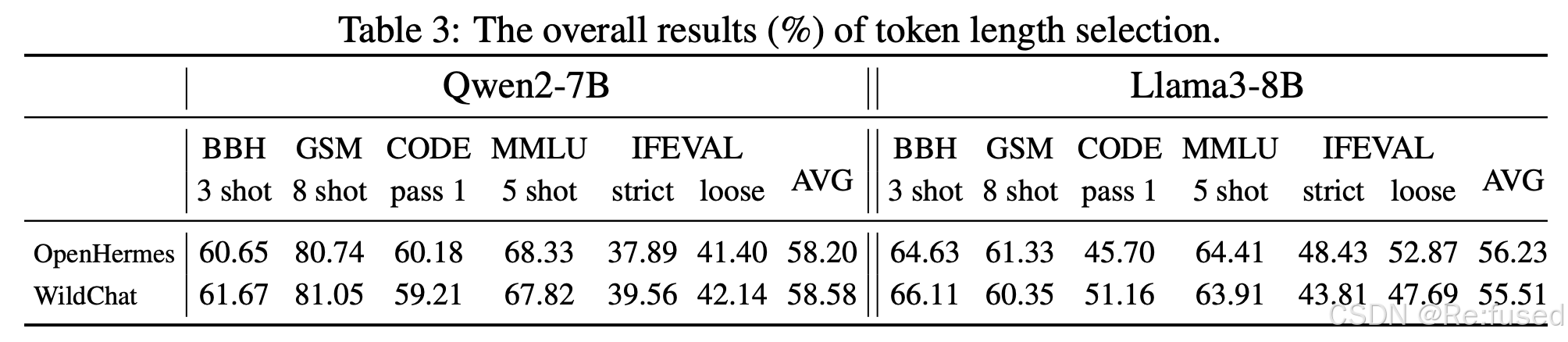
根据令牌长度选择数据可以稳定地获得较高的训练效益,减少了算法的误码率不确定性造成随机性,降低成本。
总结:
在这项研究中,我们观察到许多自监督微调(SFT)数据选择方法依赖于小规模数据集,这些数据集并不满足实际场景的需求。这一发现使我们重新思考,在需要处理大规模IT数据集时,SFT数据选择方法是否仍然有效。我们在两百万规模的数据集上重现了一些现有的自评分数据选择方法,这些方法不需要外部大语言模型(LLM)的支持,结果发现几乎所有现有方法在处理大规模数据集时都没有显著超过随机选择。此外,我们的分析显示,在SFT阶段,数据选择中的数据多样性比数据质量更为重要。此外,将token长度作为质量指标相比其他精心设计的质量指标,更适合用于SFT数据选择。

















 7627
7627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









