



论文:
Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach
摘要:
背景:
根据长文本内容回答问题:
输入:长文本100k
策略:直接作为大模型的输入
RAG:长文本进行分片,然后quey选择相关内容,作为大模型的输入
检索增强RAG现在已经成为LLM的外挂,基于query检索相关知识。然而,像Gemini和GPT-4这样的最近发布的LLM已经展现出了直接理解长文本的非凡能力,相关内容直接作为数据,效果更好,但是花费更高。RAG相对而言更省钱。本文主要探索长文本和RAG结合的方式:
LC: long-context
Self-Route:本文提出的策略
数据集:
Long-Bench:包含21数据集,平均长度7k words
∞Bench:平均长度100k token
模型选择:
Gemini1.5-Pro
GPT-4O
GPT-3.5-Turbo
检索模型:dense retriever
Contriever
Dragon
检索策略:
300 words一个块
选择top-k 块个作为检索结果, 默认k为5
为了避免数据泄漏,即大模型预训练的时候见过这些内容,prompt中增加内容,
“based only on the provided passage”
动机:
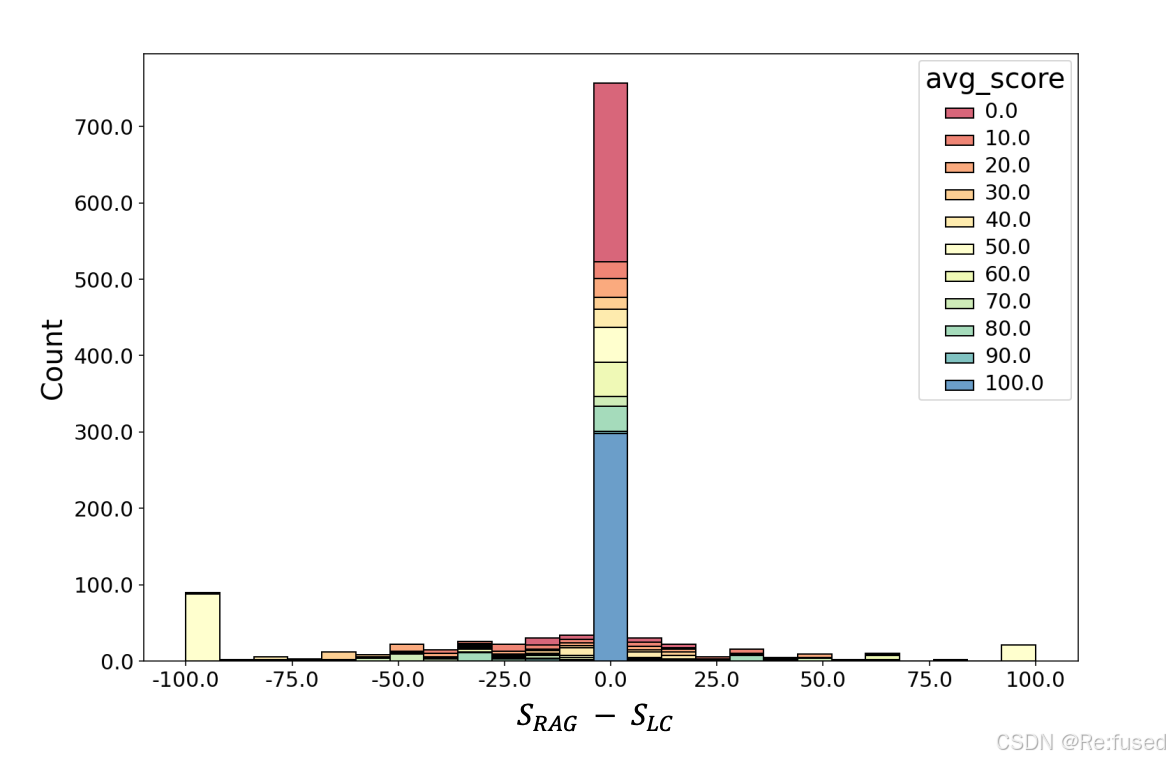
- 63%的预测结果是一致
- 并且相同的结果,既有对的也有错误的结果
结论:就为了一小部分不一样的数据,进行LC大量的计算,代价比较大,因此提出一种融合二者的方式
策略:Self-Route
- 常规的RAG,但是prompt中增加一个内容
Write unanswerable if the query can not be answered based on the provided text
如果可以回答,接受RAG的结果,不可回答,则执行第二步 - 把完整的上下文内容,输入给大模型
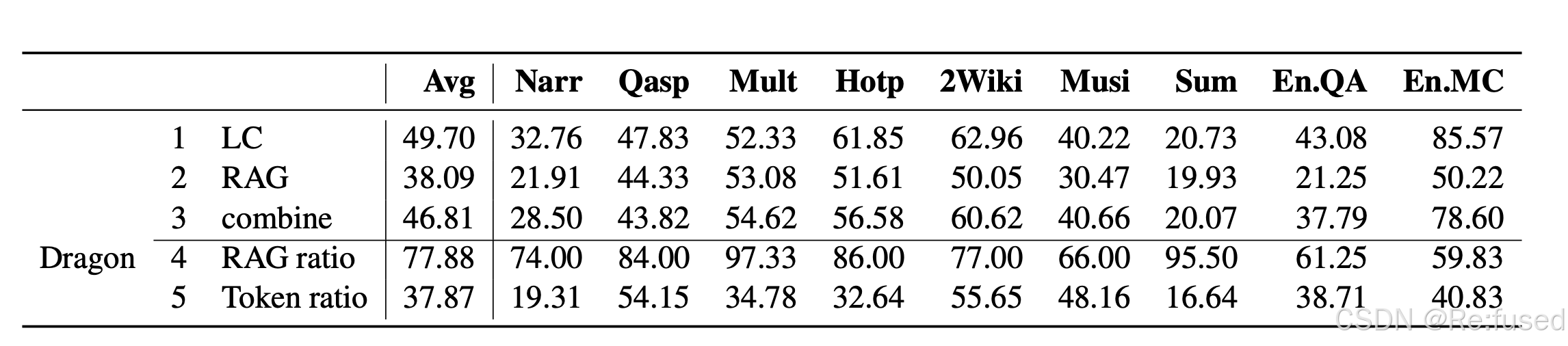
实验结果
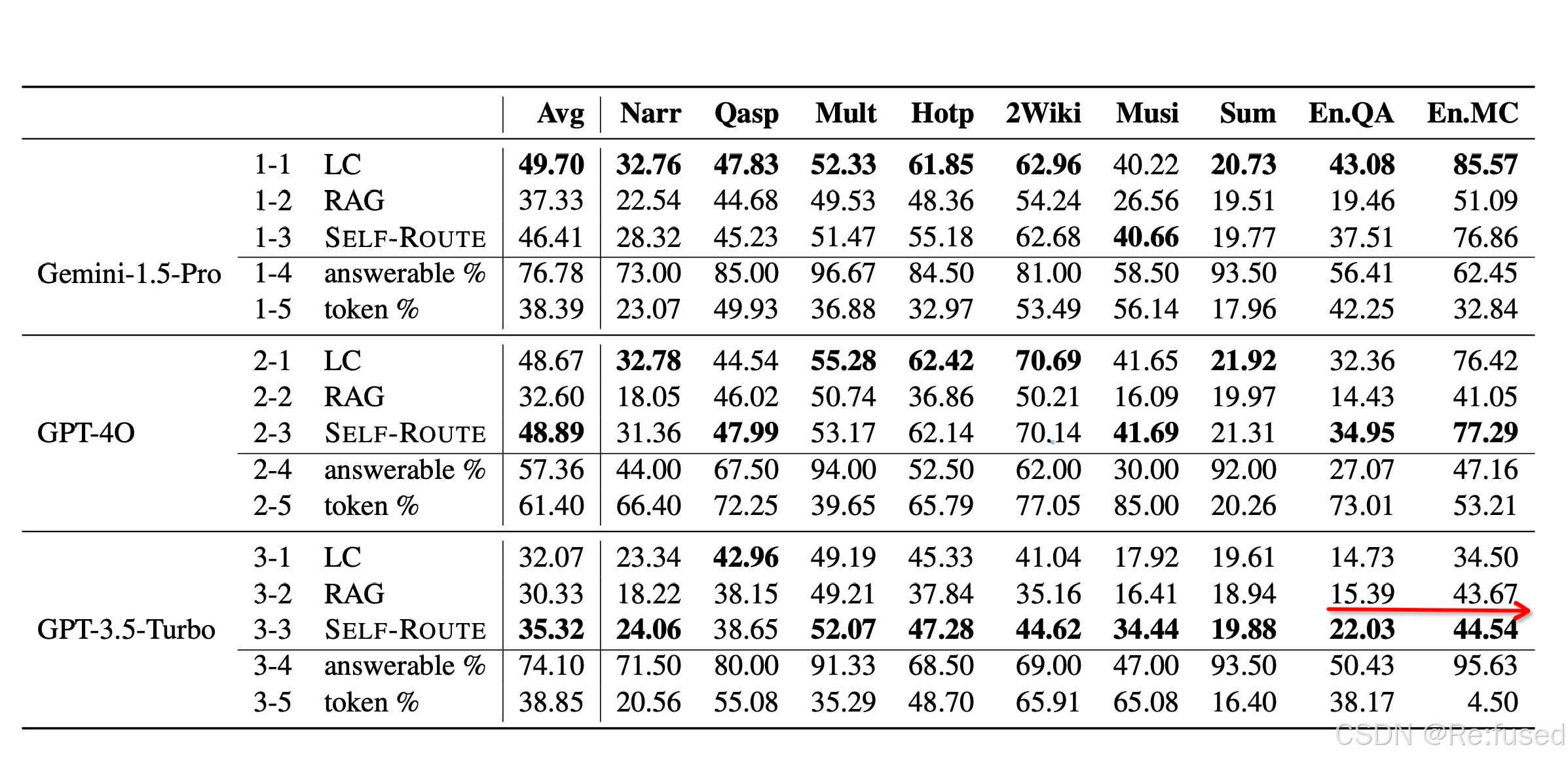
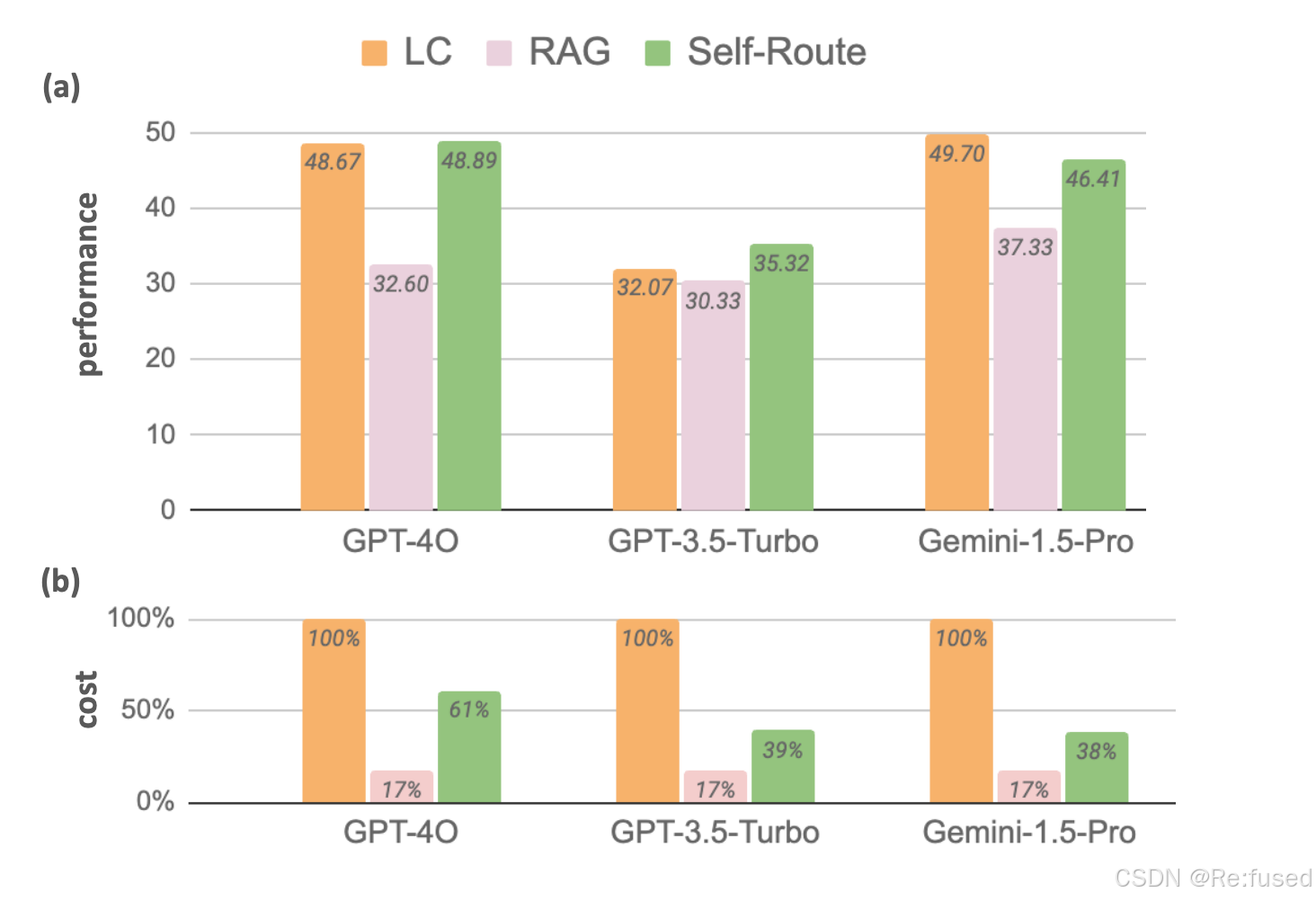
-4是RAG回答的占比,-5是使用的token占比
- LC优于RAG, 除了标红部分,GPT3.5 Token数量最大支持16k, 这两个数据集平均长度147k,
- 整体上SLEF-ROUTE优于RAG 5%
- 使用 SLEF- ROUTE使用RAG超过50%, 即使*-4
分析实验:
-
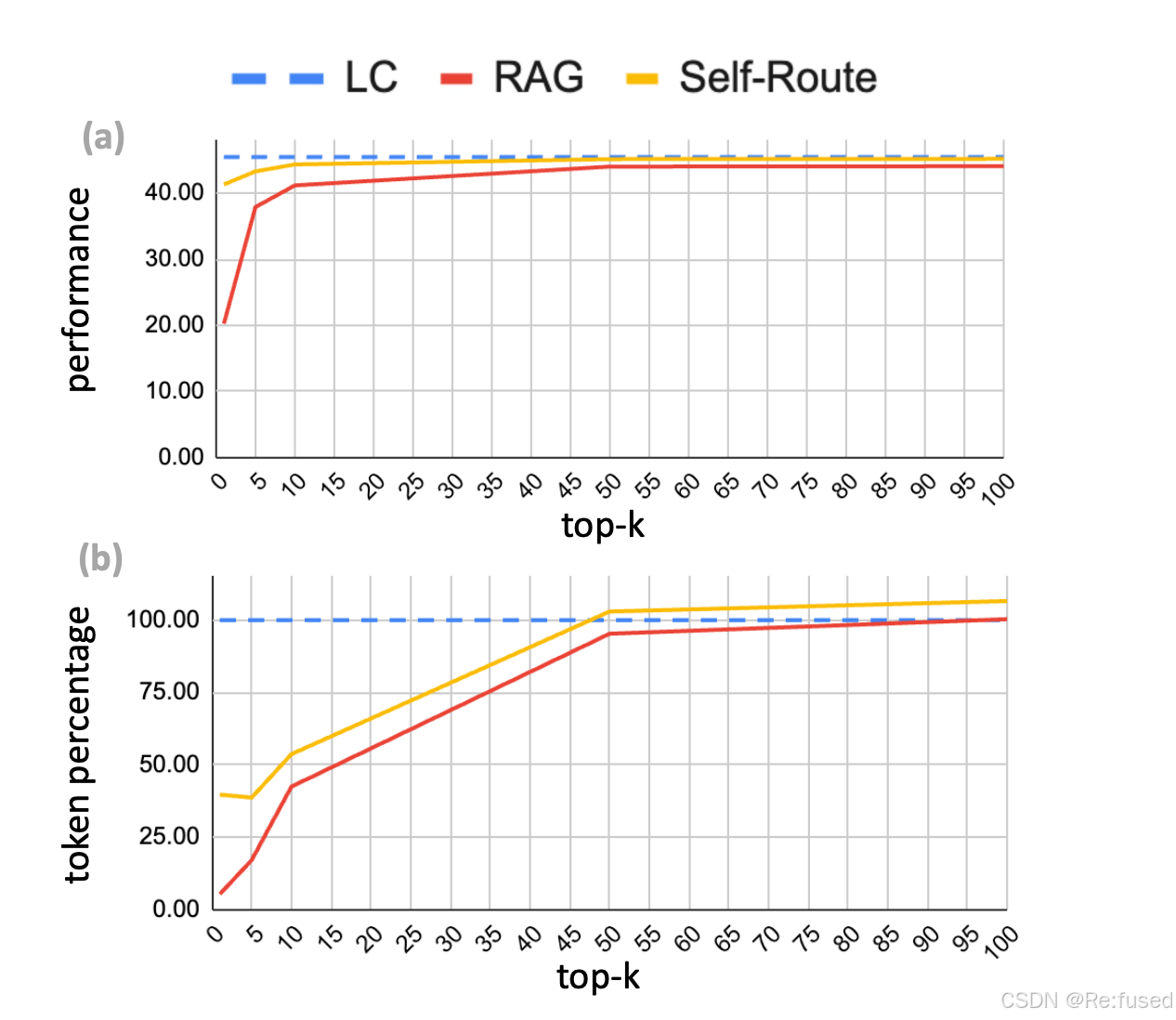
top-k设置分析实验
-
为什么RAG失效?
对RAG-and-Route step predicts “unanswerable”,这部分数据,标注几条数据,作为few-shot, 对数据问题进行分类:
归纳四种问题:
(1)多步问答, “What nationality is the performer of song XXX“
(2)query太普遍, “Whatdoes the group think about XXX”
(3)query又长又复杂
(4)query隐含的不直观, “What caused the shadow behind the
spaceship?”
(5)其他
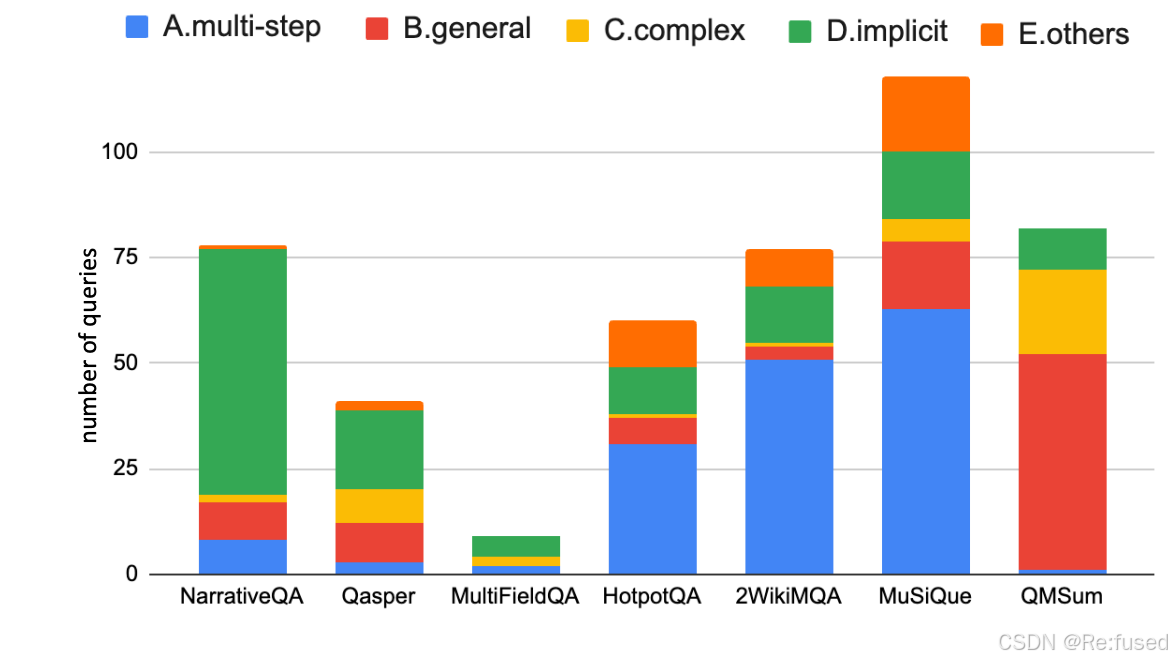
大多数“其他”类别都是“多步骤”的原因
不同的检索方式:

基于Gemimi模型,不通的检索工具(模型),也是同样的结论
在合成数据方面:
“PassKey” dataset where a sentence with a passkey (e.g. “the passkey is 123456”) is hidden withinchunks of irrelevant text, and the model is asked to answer the question “What is the passkey”.
“PassKey”数据集,其中包含PassKey的句子(例如“PassKey是123456”)隐藏在不相关的文本块中,并询问模型来回答“什么是密钥”这个问题。即:大海捞针
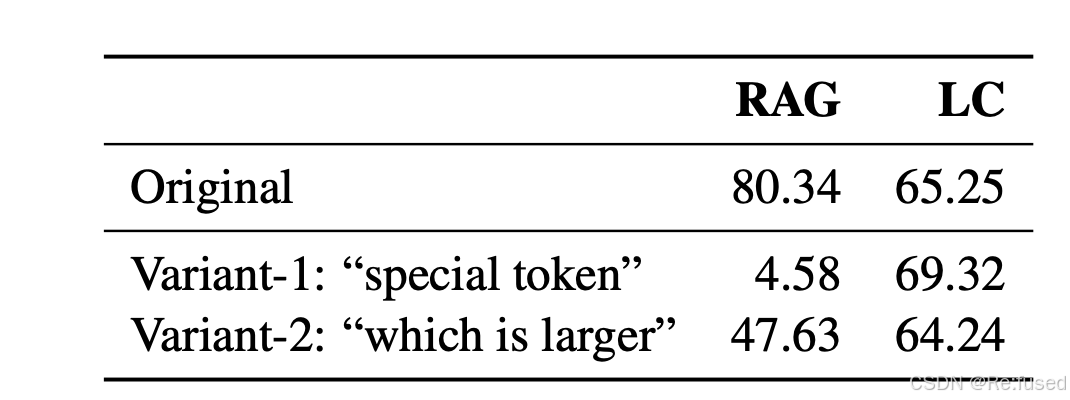
Variant-1:“What is the special token hidden inside the texts”
Variant-2:包含两个two passkeys,“Which passkeyis larger? First or second?”,
结论:论证了数据评估高度受人工制品的影响,数据集构建,显示了合成数据测试的局限性
排除大模型内部知识:
主要就是排除大模型之前学习过这些内容,对实验造成影响,使大模型仅仅利用提供的知识。
采用两种方式:
- 证明:“based only on the provided passage” 这一句话是有效的
- 把大模型接触的常识性的知识去除掉,重新评估
采用的方式, prompt中加入这一句话,“based only on the provided passage”
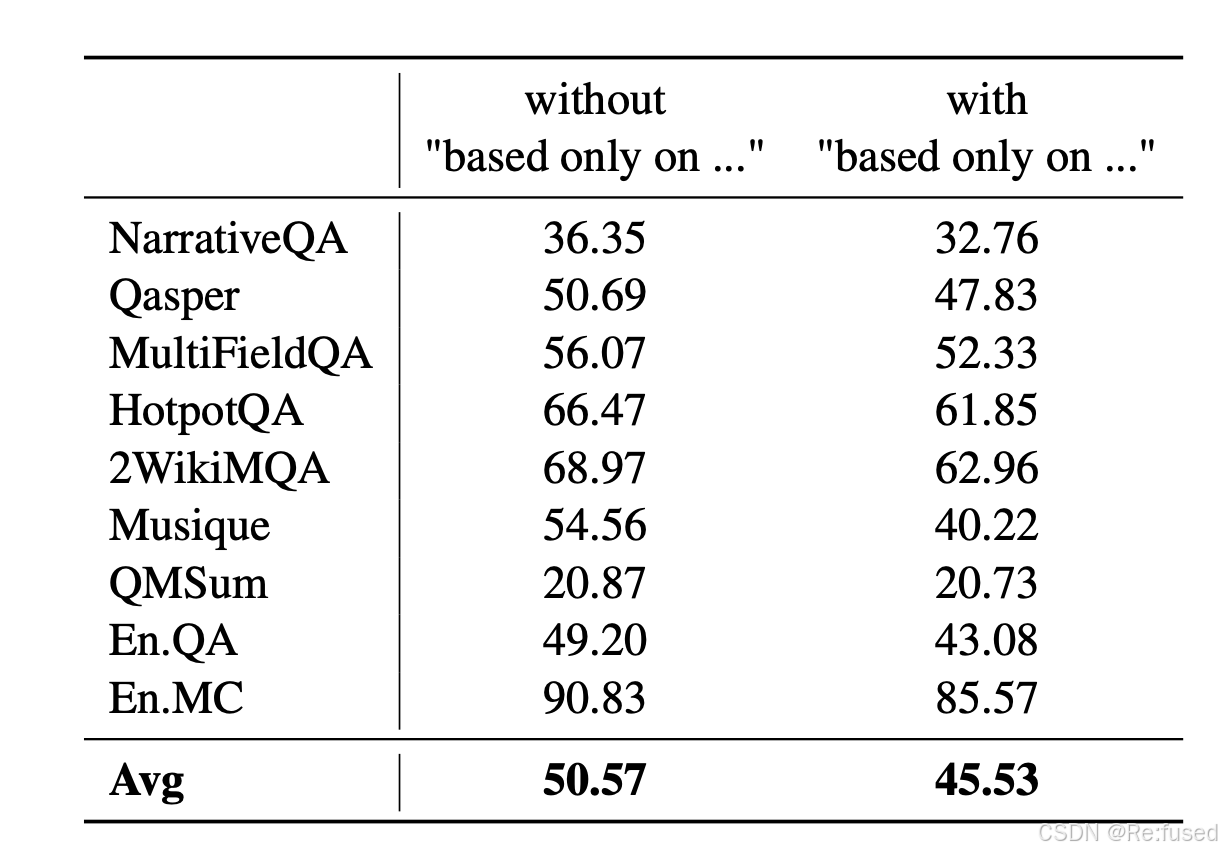
使用这一句话,模型真题效果下降了,证明使用这句话,有效使用大模型忘记这些知识
另外一种方式:把一些常识性的问题,剔除掉
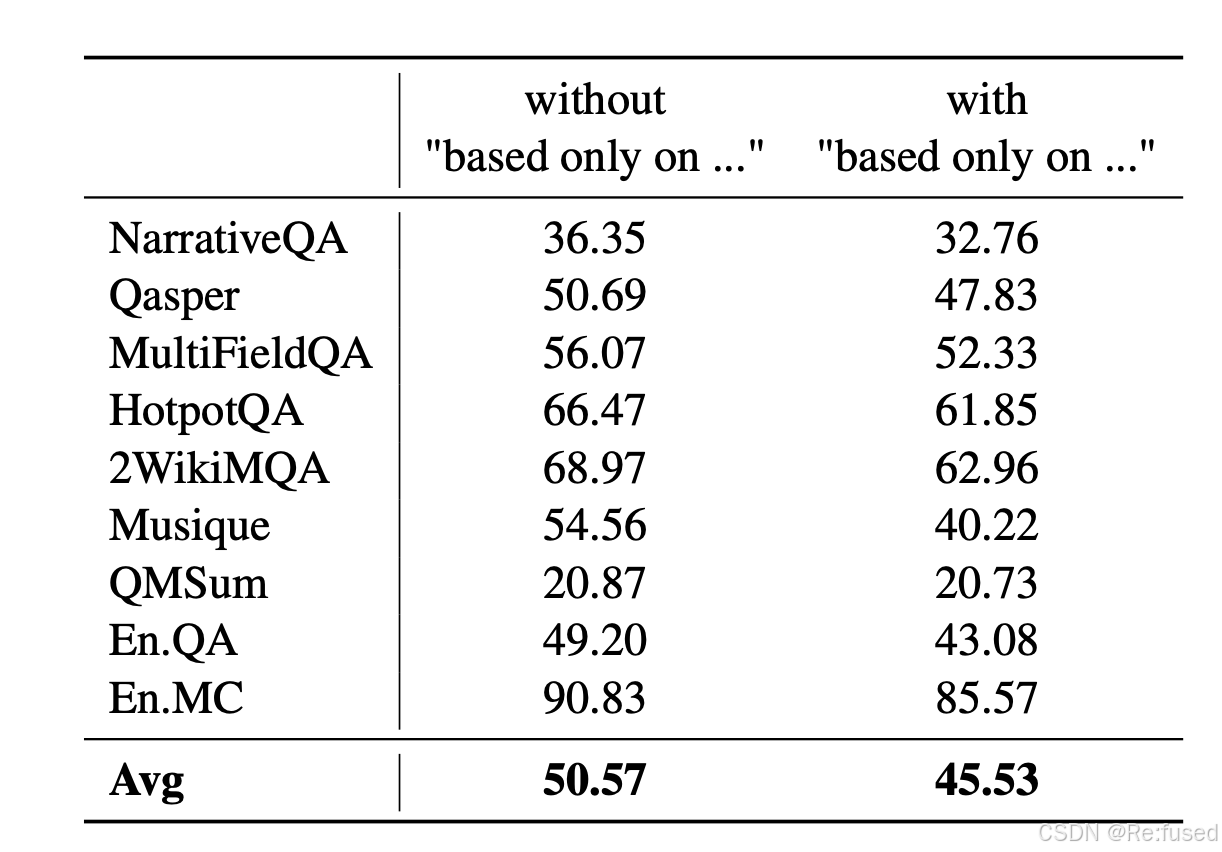
同样证明提出的方式是有效的。
结论:
本文对 RAG 和 LC 进行了全面比较,突出了性能和计算成本之间的权衡。虽然 LC 在长语境理解方面表现出色,但由于其较低的成本和在输入大大超过模型的上下文窗口大小时的优势,RAG 仍然是一种可行的选择。我们提出的方法通过基于模型自我反思的动态路由查询,有效地结合了 RAG 和 LC 的优点,在显著降低成本的情况下实现了与 LC 相当的性能。我们认为,我们的发现为长期上下文 LLM 的实际应用提供了有价值的见解,并为优化 RAG 技术的未来研究铺平了道路。

















 1347
1347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









