



HR-Align团队 投稿
量子位 | 公众号 QbitAI
“让机器人看懂世界、听懂指令、动手干活”正从科幻走向现实。
基于大规模人类视频数据进行视觉预训练,是开发真实场景可泛化机器人操作算法的有效途径。
核心在于人类操作与机器人动作序列高度相似,因此从人类视频习得的动态表征可迁移至机器人任务;然而 “从人到机器人” 的迁移面临关键阻碍,即人 - 机器人数据域间差异(Human-Robot Domain Discrepancy)。尽管二者执行任务时动作看似相似,但其形态存在根本差异。
这种差异导致了一个重要问题:即便在海量人类数据上预训练了模型,这些模型一旦直接用于机器人任务时,其表现却往往大打折扣,甚至失败。
来自香港科技大学(广州)的团队提出了一个核心问题:
如何减少人-机器人之间的数据域差异影响,使得从人类预训练中获得的视觉模型,能够更有效地帮助机器人完成实际任务?
在这一问题之下,他们提出人类视频预训练迁移新范式,利用匹配的人类-机器人操作视频,设计语义对齐方法弥合了这种跨域鸿沟。
其中第一作者周佳明,香港科技大学广州二年级博士生,研究方向为人类视频动作模仿以及可泛化的机器人操作;通讯作者是梁俊卫,是香港科技大学广州助理教授。
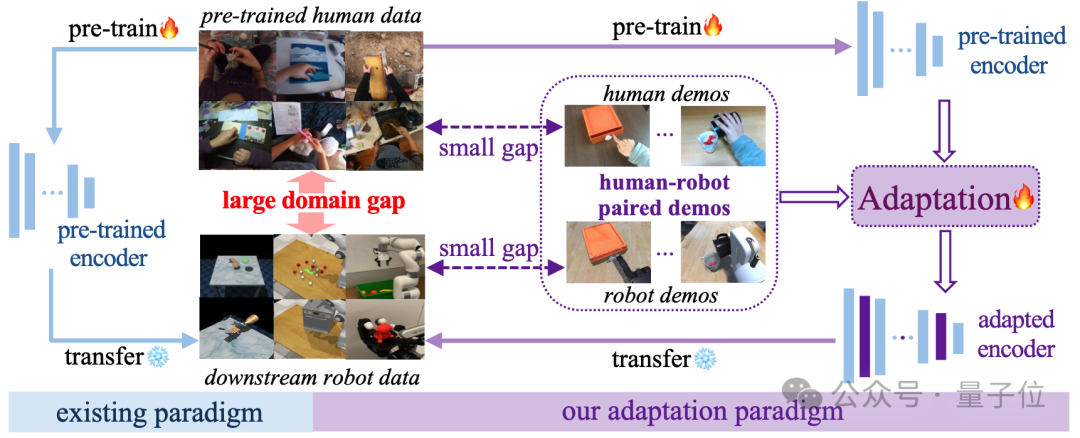
传统做法(如图左)直接用在Ego4D等人类数据集上训练的模型去处理机器人任务,这种直接迁移的方法自然会受到人类-机器人数据域差异的干扰。
本研究提出的新范式(如图右)通过利用语义对齐的人类-机器人视频对,在现有的人类视频预训练模型中插入Adapter微调模块,通过对比损失将机器人数据上调整的模型的语义和预训练模型中良好建模的人类动态语义进行对齐,从而减少域差异的干扰。
HR-Align跨越人机语义鸿沟的桥梁
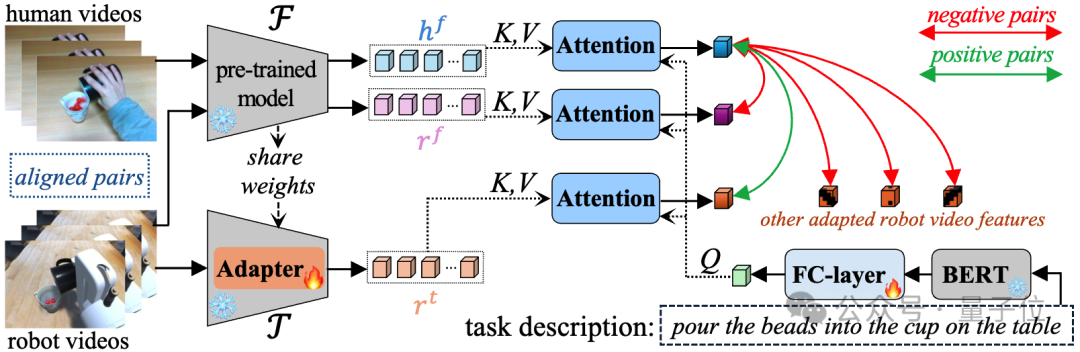
根据提出的预训练适配新范式,该工作设计了HR-Align(Human-Robot Semantic Alignment)方法。其核心思想非常简洁:
如果能够获取“同一个任务”的人类操作视频和机器人操作视频,并用它们之间的对应关系来引导模型微调,那就有可能建立起一个人-机器人之间的语义对齐机制。
1. 从“独立预训练”到“配对视频语义对齐”
传统的视觉预训练方法是在纯人类视频上进行训练,然后将模型“冻结”,直接应用于机器人任务。这种方式忽略了人和机器人领域间的差异。HR-Align打破了这种“直接迁移”的壁垒,主张在预训练和下游任务之间,引入一个“适配阶段”。
在这个阶段中,研究者使用了一个具有语义配对的人机数据集,这个数据集中每一个人类动作视频,都有一个对应的机器人操作视频。这种人-机器人视频对提供了一个天然的“语义桥梁”。
2. 引入对比学习机制,实现语义对齐
HR-Align适配的关键是人-机器人对比对齐损失。在适配过程中,对于已有的人类视频预训练视觉编码器,HR-Align分别从人类视频和机器人视频中提取冻结的语义特征。同时,使用另一分支在编码器中引入轻量级Adapter模块在机器人视频上微调,从而提取机器人视频的适配特征。模型适配的核心约束是,相比机器人视频的冻结特征,机器人视频的适配特征与匹配的人类视频特征应当具有更加相似的语义;
3. 轻量高效,适配通用
与其他需要大规模重新训练、或者为每种机器人环境单独调整模型的方案不同,HR-Align具备如下优势:
参数高效:仅适配小模块,主模型无需大规模更新;
通用性强:同一个适配模型可泛化至多个任务和环境,无需逐一定制;
数据易得:越来越多的平台提供人-机器人视频对,为方法的可落地提供保障。
实验结果
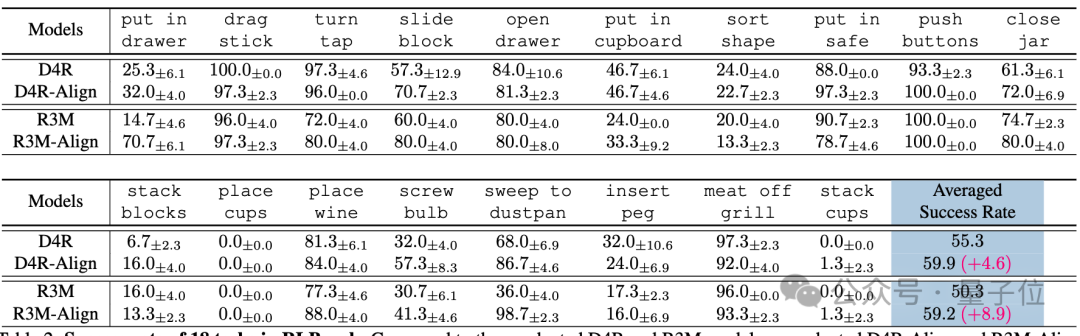
在RLBench的18个仿真任务下,通过HR-Align方法适配的D4R-Align模型相比原来的D4R预训练模型,平均成功率提升了4.6%;而通过HR-Align方法适配的R3M-Align模型相比未调整的R3M模型,平均成功率提升了8.9%;
在五个真实场景的机器人任务上,D4R-Align和R3M-Align模型相比未适配的预训练模型,平均成功率分别提升13%和11%;
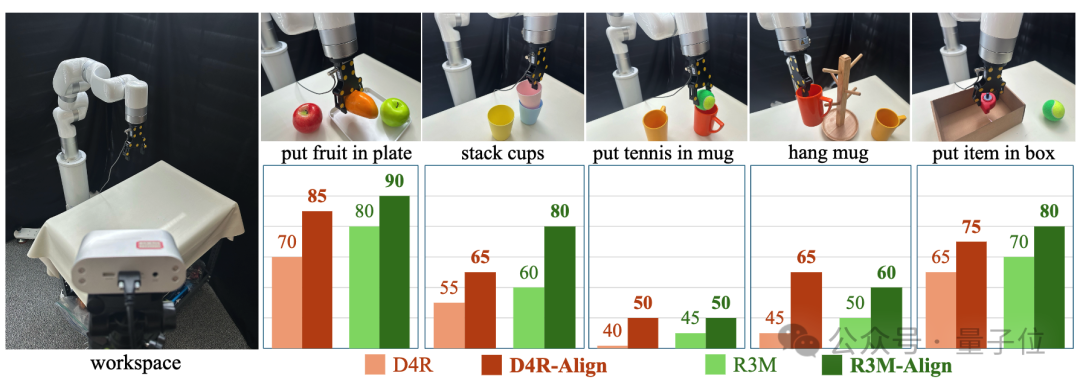
这些显著的提升不仅验证了方法的有效性,也表明该适配策略具有极高的实际应用价值。
核心贡献总结
提出新问题:从大规模人类视频预训练中学习可泛化机器人操作,人体-机器人数据的域差异问题不可忽视。
提出新范式:通过匹配的人-机器人动作视频,实现人类动作与机器人操作的语义对齐,不再盲目依赖预训练模型的泛化能力。
高效适配方法:引入轻量级Adapter模块,仅需极少参数微调,即可将模型适配到机器人任务中。
充分实验验证:在20个仿真任务与5个真实机器人任务中均取得超过7%平均成功率提升,适配模型显著优于未适配版本。
论文链接: https://arxiv.org/pdf/2406.14235
项目主页: https://jiaming-zhou.github.io/projects/HumanRobotAlign/
开源仓库: https://github.com/jiaming-zhou/HumanRobotAlign



















 27
27

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









