



梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
字节最新深度思考模型,在数学、代码等多项推理任务中超过DeepSeek-R1了?而且参数规模更小。
同样是MoE架构,字节新模型Seed-Thinking-v1.5有200B总参数和20B激活参数。
对比DeepSeek-R1的671B总参数和37B激活参数,可以算得上轻量级了。
目前,完整的技术报告已公开发布,其中揭示了诸多秘诀。
字节Seed团队聚焦大规模强化学习,并从三个角度提升了推理表现:数据、RL算法和RL基础设施。

可验证与不可验证问题
从数据开始说起,字节团队把RL训练数据分为两个部分,具有明确答案的可验证问题和没有明确答案的不可验证问题,采用不同的奖励建模方法。
这其中,模型的推理能力主要来自可验证问题,并可以推广到不可验证问题。
可验证问题包括问题与答案配对的STEM问题、附带单元测试的代码问题,以及适合自动验证的逻辑推理问题(24点、迷宫、数独等)。
不可验证问题主要包括根据人类偏好评估的非推理任务,如创意写作、翻译、知识QA、角色扮演等。
对于不可验证问题,字节团队丢弃了样本分数方差低、难度低的数据。此类数据可能过于简单或已在数据集中大量表示。离线实验表明,过度优化此类样本会导致模型的探索空间过早崩溃并降低性能。
此外,团队还打造了全新数学推理评测集BeyondAIME。
当前的推理模型通常使用AIME作为评估数学推理能力的首选基准,但该基准每年只发布30个问题,有限的规模可能会导致高方差的评估结果,难以有效区分最先进的推理模型。
字节与数学专家合作,根据既定的比赛形式开发原创问题。通过结构修改和情景重新配置来系统地调整现有的比赛问题,确保不会发生直接重复。此外还确保答案不是容易猜的数值(例如问题陈述中明确提到的数字),以减少模型在没有适当推理的情况下猜出正确答案的机会。
RL算法
强化学习虽然强大,但训练起来也很不稳定,经常崩溃。
字节在技术报告中提到”有时,两次运行之间的分数差异可能高达10分”。
针对这个问题,团队提出了VAPO和DAPO两个RL框架,分别从基于价值和无价值的RL范式出发来稳定训练。
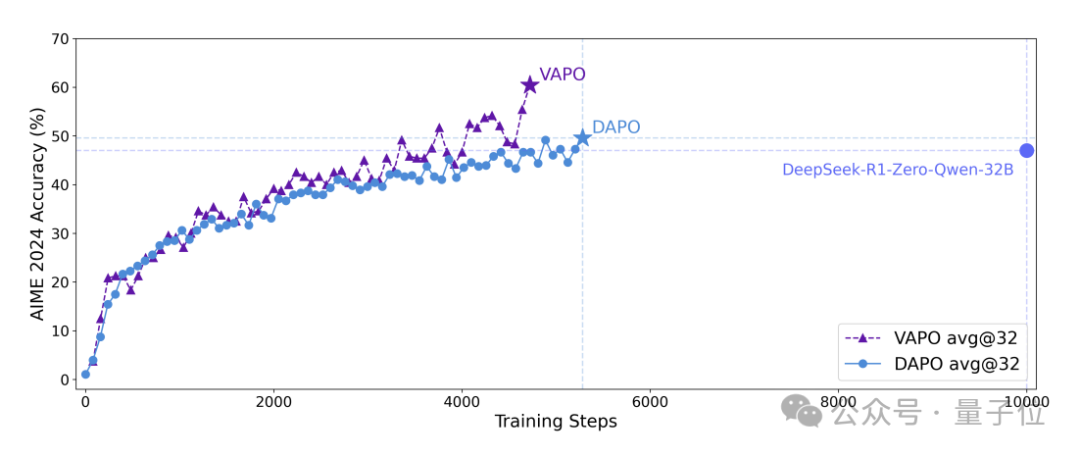
VAPO和DAPO两篇论文都已单独发布。


此外,在Seed-Thining-v1.5中,还借鉴了之前学术界工作中的很多关键技术:
价值预训练(Value-Pretraining),保证价值网络和策略网络一致
解耦的GAE(Decoupled-GAE),让两个网络更独立高效
长度自适应GAE(Length-adaptive GAE),更好处理不同长度序列
解耦PPO损失(Clip-Higher),为低概率token的增长创造,了更多空间鼓励模型探索新方案
Token级损失(Token-level Loss),平衡每个token对训练过程的影响。
正例增强(Postive Example LM Loss),提高RL训练过程中正样本的利用效率,从而提高模型整体性能

RL基础设施
在Long-CoT生成过程中,字节团队观察到各种提示词之间的响应长度差异较大,在生成过程中出现大量GPU空闲时间。
为了缓解长尾响应生成的滞后问题,提出了SRS(流式Rollout系统),一种资源感知型调度框架,可战略性地部署独立的流式计算单元,将系统约束从内存绑定转换为计算绑定。
为了有效地大规模训练,团队还设计了一个混合分布式训练框架,集成高级并行策略、动态工作负载平衡和内存优化:
并行机制:将TP (张量并行)/EP (专家并行)/CP (上下文并行)与全分片数据并行 (FSDP) 组合在一起,具体来说,将TP/CP 应用于注意力层,将EP应用于 MoE 层。
序列长度平衡:DP等级之间的有效序列长度可能不平衡,导致计算工作量不平衡和训练效率低下。利用KARP算法在一个mini-batch内重新排列输入序列,使它们在micro-batch之间保持平衡。
内存优化:采用逐层重新计算、激活卸载和优化器卸载来支持更大micro-batch的训练,以覆盖FSDP引起的通信开销。
自动并行:为了实现最佳系统性能,开发了AutoTuner 自动调整系统,按照基于配置文件的解决方案 对内存使用情况进行建模。然后估计各种配置的性能和内存使用情况以获得最优配置。
检查点:使用ByteCheckpoint支持从不同的分布式配置中以最小的开销恢复检查点,弹性训练以提高集群效率。

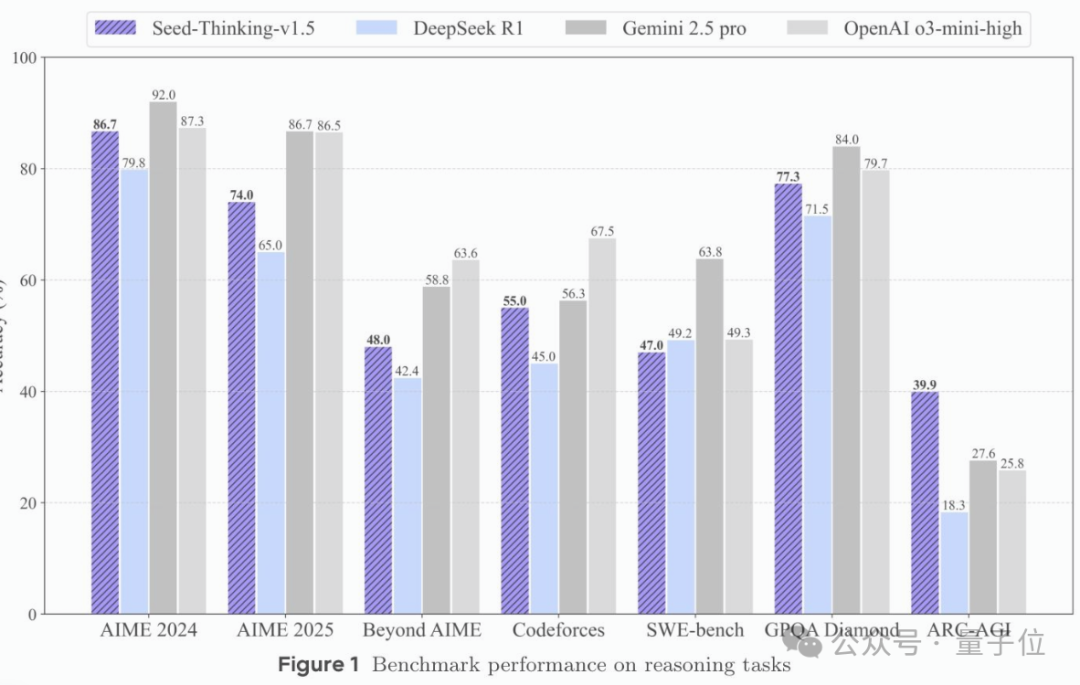
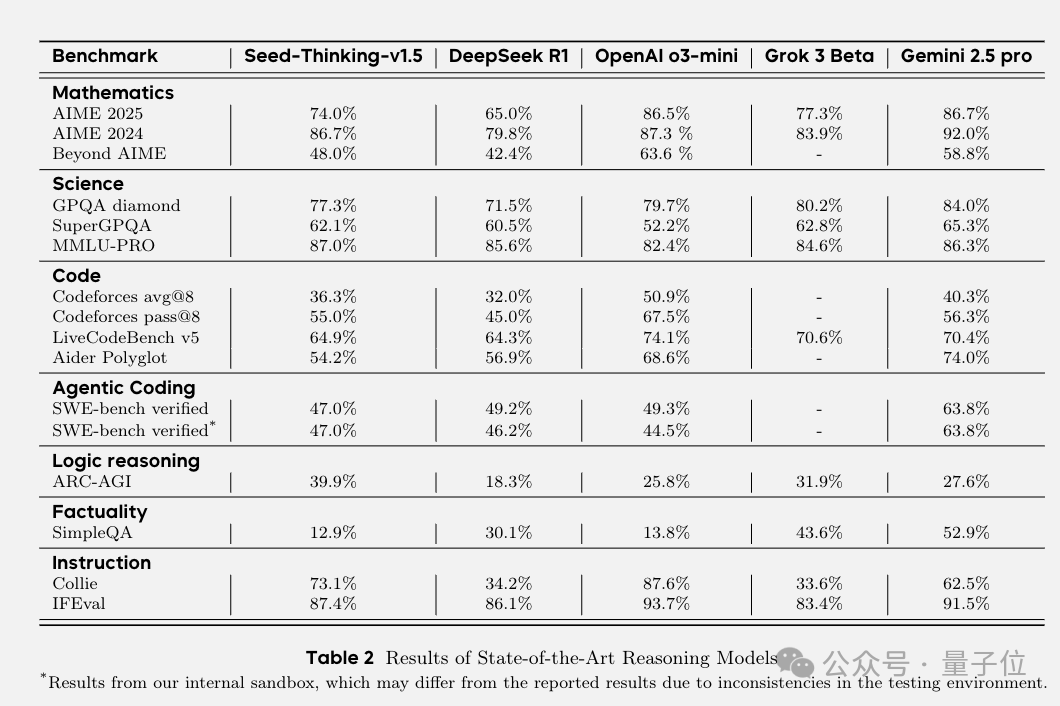
最终,在多项自动评估中,Seed-Thinking-v1.5在AIME 2024基准测试中取得86.7,与OpenAI的o3-mini-high模型的性能相当。但在最近的AIME 2025和BeyondAIME中,Seed-Thinking-v1.5仍然落后于o3级别的性能。
对于GPQA任务,Seed-Thinking-v1.5达到77.3%的准确率,接近o3-mini-high的性能。
在Codeforces等代码生成场景中,Seed-Thinking-v1.5的性能与Gemini 2.5 Pro 的性能相当,但仍落后于o3-mini-high。
Seed-Thinking-v1.5在SimpleQA上的表现不太理想。但团队认为,该基准测试预训练模型规模的相关性更强,而不是考验推理能力。
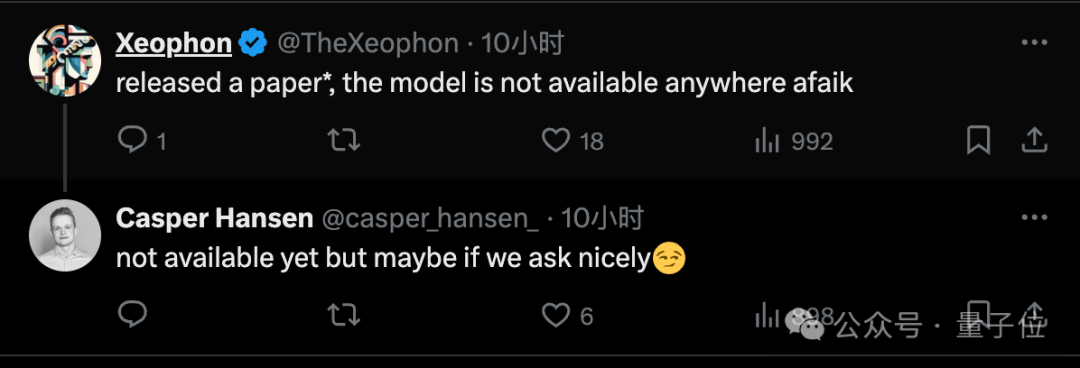
许多人看完这篇技术报告,都很感兴趣,不过找了一圈也没找到模型在哪发布。
从技术报告的口径来看,该模型与目前豆包中的Doubao-1.5 Pro并不是一回事。
但从作者名单看,这是由字节Seed团队负责人吴永辉带队,主要成员都参与的大项目。
那么是否将来会部署到豆包APP,可以期待一波了。

论文地址:
https://github.com/ByteDance-Seed/Seed-Thinking-v1.5/



















 12
12

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









