 ScholarCopilot:告别引用幻觉的学术写作框架
ScholarCopilot:告别引用幻觉的学术写作框架




ScholarCopilot团队 投稿
量子位 | 公众号 QbitAI
学术写作通常需要花费大量精力查询文献引用,而以ChatGPT、GPT-4等为代表的通用大语言模型(LLM)虽然能够生成流畅文本,但经常出现“引用幻觉”(Citation Hallucination),即模型凭空捏造文献引用。这种现象严重影响了学术论文的可信度与专业性。
现在,加拿大滑铁卢大学与卡内基梅隆大学的华人研究团队,提出了一种名为 ScholarCopilot 的智能学术写作大模型框架,专门针对学术场景,致力于精准地生成带有准确引用的学术文本。

ScholarCopilot与传统方法的区别
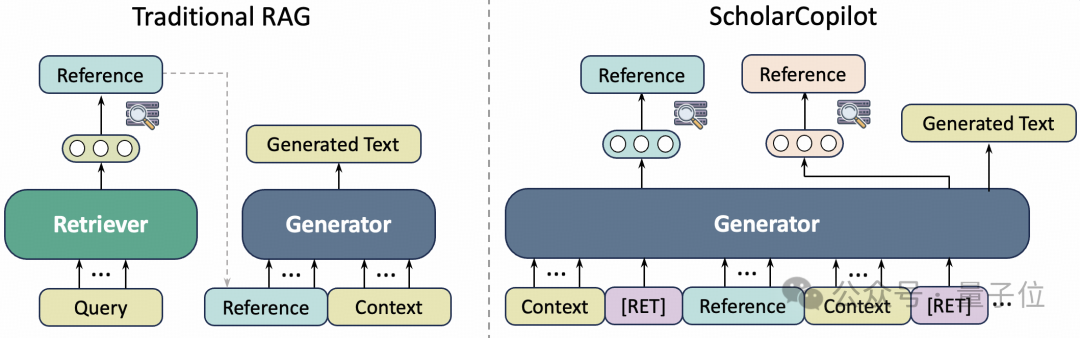
传统的检索增强生成(Retrieval-Augmented Generation, RAG)方法采用“先检索、再生成”的静态流程,这种方式存在以下问题:
检索与生成过程相互独立,容易导致意图不匹配;
无法根据上下文需求动态调整引用策略,影响引用准确性。
针对这些局限性,ScholarCopilot提出了一种“边生成、边检索”的动态机制:
在生成文本时,模型动态地判断何时需要引用文献,并生成一个特殊的检索信号([RET]);
随后实时检索学术数据库中的相关文献,将检索到的内容融入后续生成过程;
通过联合优化生成任务和检索任务,提升引用的准确度与相关性。
简单来说,ScholarCopilot的写作方式更接近人类真实的写作习惯:平时正常撰写论文内容,当需要引用文献时再主动检索相关文献的BibTeX信息插入引用,随后继续撰写下文。同时,模型在撰写后续内容时,也会参考已插入的引用文献,确保生成的文本与引用内容紧密相关。
ScholarCopilot的性能表现
研究团队以阿里云近期发布的Qwen-2.5-7B模型为基础,使用了50万篇arXiv论文进行训练,并在多个维度上进行了性能评估:
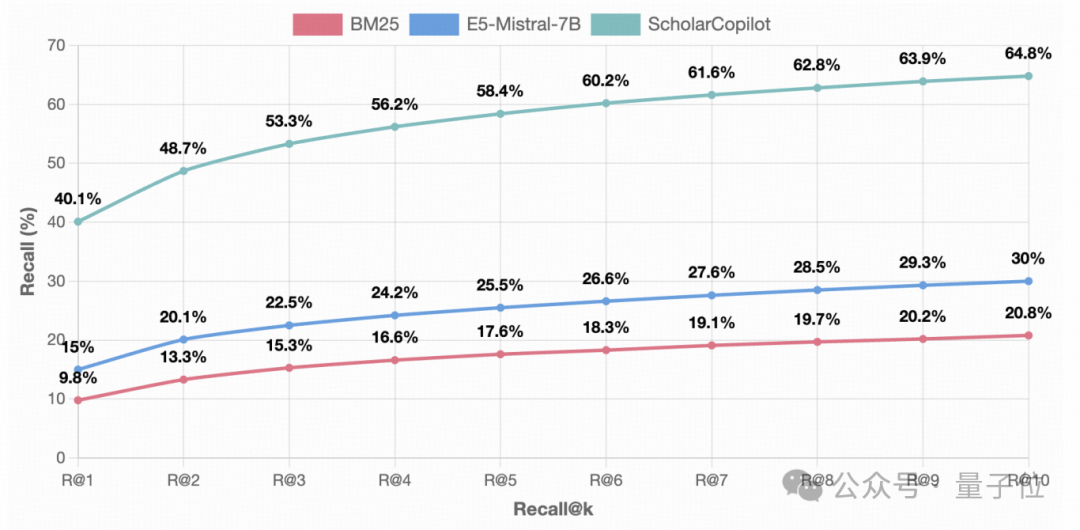
引用检索准确性(Top-1 accuracy)达到40.1%,显著超过现有的检索模型:
E5-Mistral-7B-Instruct(15.0%)
BM25(9.8%)
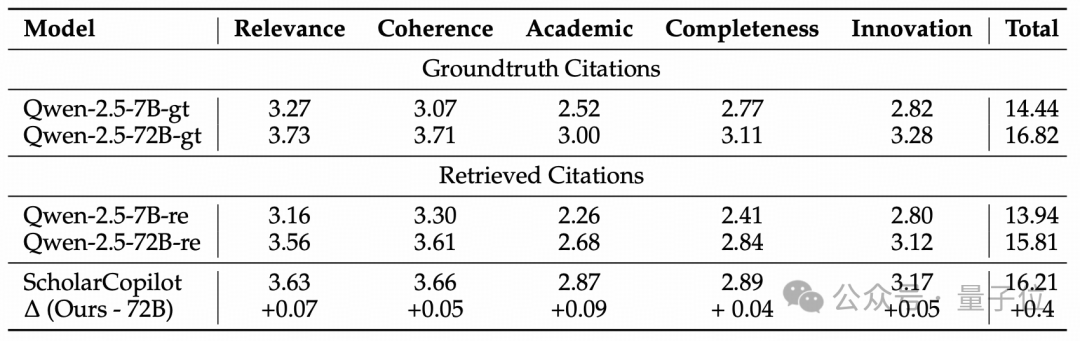
论文生成质量方面(包括相关性、连贯性、学术严谨性、完整性和创新性),综合得分为16.2(满分25),高于参数量更大的Qwen-2.5-72B-Instruct模型(15.8)和Qwen-2.5-7B-Instruct模型(13.9)。
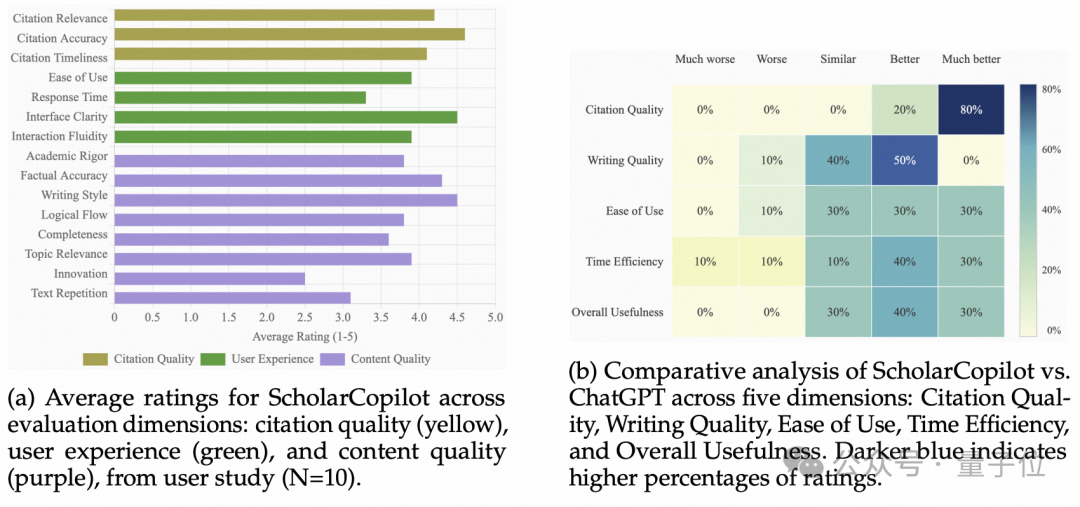
在一项由10位拥有平均4.2年学术写作经验的学生(5名博士、4名硕士、1名本科生)参与的真人评测中:
ScholarCopilot在引用质量上的用户偏好率达到100%;
整体实用性偏好率超过70%。
ScholarCopilot的不足与未来方向
尽管取得了显著进步,ScholarCopilot仍存在一些局限性。通过上述用户调研,受访者提出了以下几点改进建议:
- 内容生成更全面:
模型在生成内容的丰富性与信息全面性方面仍需进一步提升;
- 创新性不足:
目前模型在生成创新性想法和研究问题方面表现一般,还有较大改进空间。
此外,受访者还建议未来版本可考虑:
与主流学术写作平台(如Overleaf)进行更紧密的整合;
支持分章节独立生成和任意光标位置的文本预测功能。
研究团队表示,这些反馈意见为后续开发提供了明确的改进方向。
后续展望
ScholarCopilot研究团队希望通过不断优化模型性能、扩展检索数据库和改进用户交互体验,让研究人员在学术写作中能更专注于研究本身,而非繁琐的文献检索与引用管理。
当前相关论文、代码与模型已经公开发布,感兴趣的读者可自行了解详细信息,进一步体验与评估该模型的实际表现:
论文链接:https://arxiv.org/pdf/2504.00824
项目网站:https://tiger-ai-lab.github.io/ScholarCopilot/
演示视频:https://www.youtube.com/watch?v=QlY7S52sWDA



















 26
26

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









