



DiffILO团队 投稿
量子位 | 公众号 QbitAI
无监督学习训练整数规划求解器的新范式来了。
中国科学技术大学王杰教授团队(MIRA Lab)提出了一种全新的整数规划求解方法——DiffILO(Differentiable Integer Linear Programming Optimization),相关论文已被人工智能顶级国际会议ICLR 2025接收为Spotlight。
结果显示:与现有主流的监督学习方法对比,DiffILO不仅显著加快训练速度,还能生成更高质量的可行解。

引言:用机器学习解ILP,为何如此困难?
整数线性规划(ILP) 是组合优化中最基础也是最关键的一类问题,广泛应用于工业调度、物流运输、网络规划、芯片布图等现实场景。然而 ILP 的求解非常困难 —— 变量离散、可行域复杂、搜索空间指数爆炸,本质上属于 NP 难问题。
近年来,机器学习逐渐被引入这一过程,尝试通过数据驱动的方式加速求解器。但当前主流做法大多依赖监督学习:先用传统求解器(如Gurobi)生成一批解作为标签,然后训练模型去“模仿”这些解。这种做法存在两大瓶颈:
高昂的训练成本:每个样本都需调用求解器生成标签;
训练目标与测试目标不一致:只优化预测误差,无法保障最终解的可行性与质量。
有没有可能完全摆脱标签依赖,直接让模型“自己”学会求解ILP问题?
答案是:可以!该论文提出了DiffILO方法,可以用梯度下降来“解整数规划”!
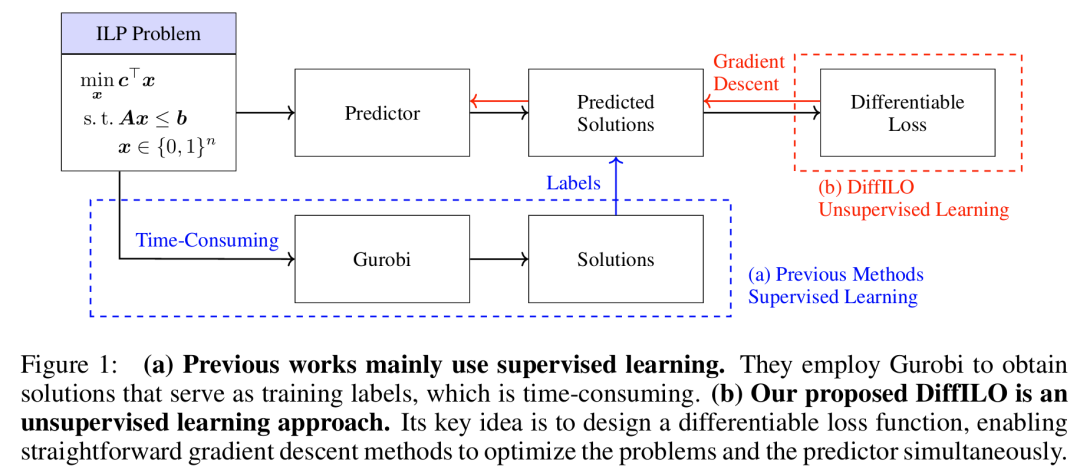
核心方法:DiffILO是如何做到的?
DiffILO,全称 Differentiable Integer Linear Programming Optimization,是一种无监督、端到端、可微分的ILP求解新范式。它的核心创新是将离散、带约束的整数规划问题,转化为连续、可微、无约束的问题,并借助深度学习模型来直接预测高质量解。
方法流程如下图所示:
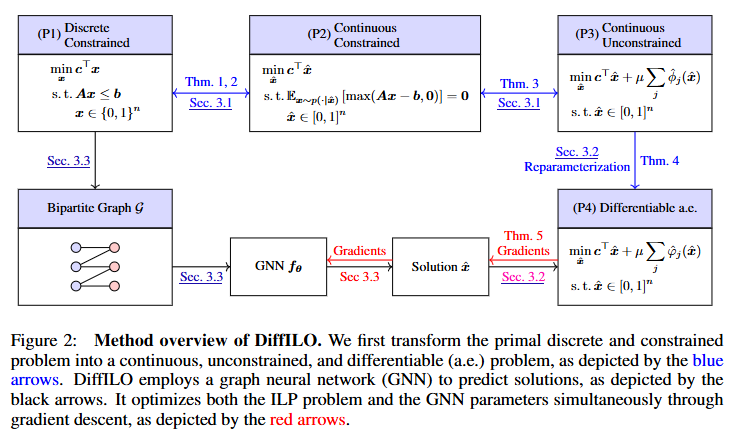
方法大致可以分为三个步骤:
Step 1:从离散到连续——概率建模与约束期望化
ILP问题的形式通常如下:
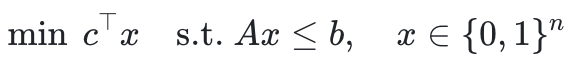
DiffILO的第一步是将每个0-1变量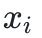 视为伯努利分布下的随机变量,即
视为伯努利分布下的随机变量,即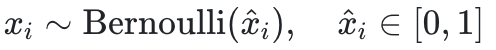 。
。
其中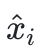 是需要优化的概率值。
是需要优化的概率值。
传统ILP的“硬约束”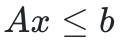 被转化为“期望约束违背为零”:
被转化为“期望约束违背为零”:
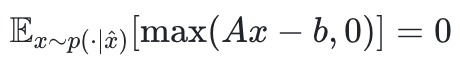
这种期望建模方式有两个好处:
仍能保留原问题的最优解结构;
易于被惩罚函数进一步转化为无约束形式。
Step 2:从约束到目标——惩罚函数与可微重参数化
该方法使用惩罚函数法将上述期望约束合入目标函数:
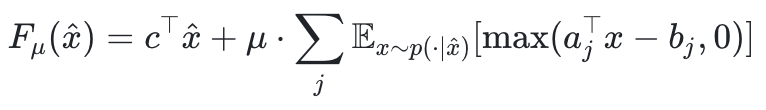
但由于该函数的采样项并不可微,DiffILO采用了Gumbel-Softmax + 重参数技巧,将离散采样近似为一个连续可导的函数:
使用
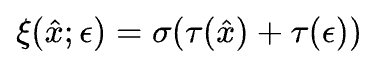 ,实现对伯努利的可微近似;
,实现对伯努利的可微近似;使用
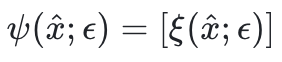 保留组合结构;
保留组合结构;梯度通过
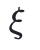 回传,值通过
回传,值通过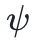 保留,兼顾
保留,兼顾“可微”和“离散”的双重需求。
最终得到一个几乎处处可导的目标函数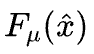 ,可以直接用梯度下降
,可以直接用梯度下降
进行优化。
Step 3:从图中学——GNN建模与端到端训练
每个ILP实例本质上可以被表示为一个二分图:左边是变量,右边是约束,边代表变量出现在对应约束中。
使用一个图神经网络(GNN)来编码这个结构,输入为图G,输出为概率向量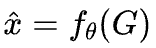 ,再接入一个MLP进行最终预测。
,再接入一个MLP进行最终预测。
训练过程完全无监督,目标是最小化上述可微目标函数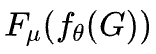 。还引入了三种训练技巧来增强稳定性:
。还引入了三种训练技巧来增强稳定性:
样本归一化:对目标函数做归一处理,适应不同实例规模;
余弦退火:自适应学习率调度;
惩罚系数调控:动态调整μ,平衡解质量与可行性。
实验结果
作者在多个标准 ILP 数据集(如 Set Covering、Independent Set、Combinatorial Auction)上进行了系统评估。结果显示:与现有主流的监督学习方法对比,DiffILO不仅显著加快训练速度,还能生成更高质量的可行解,并且在与Gurobi、SCIP结合使用时,显著提升求解器的整体性能。
作者介绍
本论文作者耿子介是中国科学技术大学MIRA实验室2022级博士生,师从王杰教授。此前,他于2022年毕业于少年班学院,取得数学与应用数学专业学士学位。他的主要研究方向包括机器学习在运筹优化与芯片设计等领域的应用、大语言模型等。他在NeurIPS、ICML、ICLR等人工智能顶级会议上发表论文十余篇,其中五篇论文入选Oral/Spotlight。他曾获2024年度国家奖学金;曾两次获得丘成桐大学生数学竞赛优胜奖;曾在微软亚洲研究院实习,获得“明日之星”称号;曾多次担任顶会审稿人,获评NeurIPS 2023 Top审稿人;参与创办南京真则网络科技有限公司。
论文地址:
openreview.net/pdf?id=FPfCUJTsCn



















 21
21

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









