



梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
谷歌首款AI推理特化版TPU芯片来了,专为深度思考模型打造。

代号Ironwood,也就是TPU v7,FP8峰值算力4614TFlops,性能是2017年第二代TPU的3600倍,与2023年的第五代TPU比也有10倍。
(为什么不对比第六代,咱也不知道,咱也不敢问。)
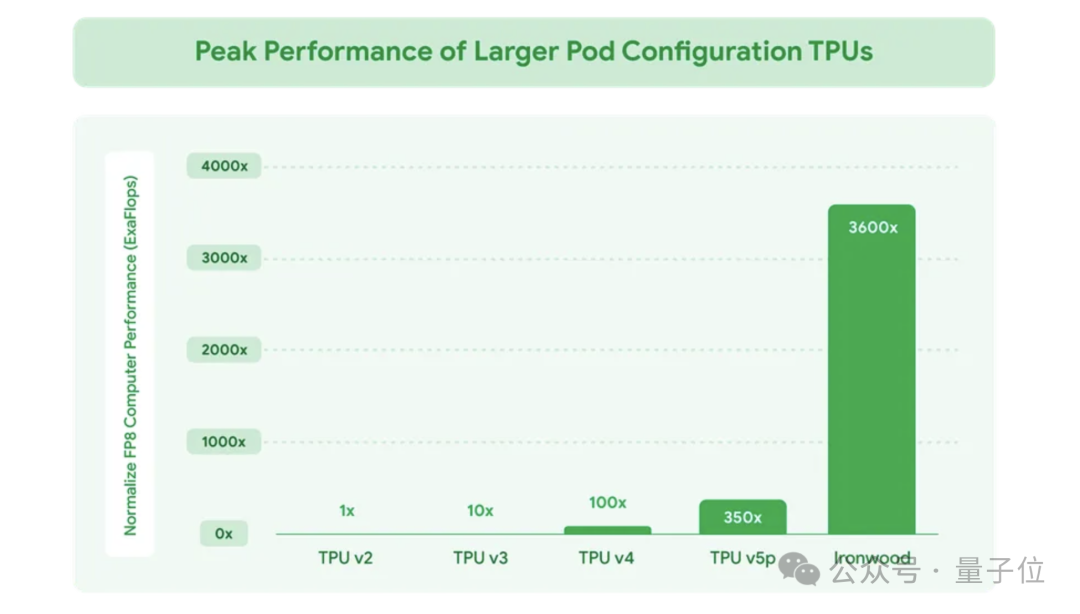
第七代TPU还突出高扩展性,最高配集群可拥有9216个液冷芯片,峰值算力42.5 ExaFlops,也就是每秒运算42500000000000000000次。
是目前全球最强超级计算机EL Capitan的24倍。
谷歌称,AI正从响应式(提供实时信息供人类解读)转变为能够主动生成洞察和解读的转变。
在推理时代,Agent将主动检索和生成数据,以协作的方式提供洞察和答案,而不仅仅是数据。

而实现这一点,正需要同时满足巨大的计算和通信需求的芯片,以及软硬协同的设计。
谷歌AI芯片的软硬协同
深度思考的推理模型,以DeepSeek-R1和谷歌的Gemini Thinking为代表,目前都是采用MoE(混合专家)架构。
虽然激活参数量相对少,但总参数量巨大,这就需要大规模并行处理和高效的内存访问,计算需求远远超出了任何单个芯片的容量。
(o1普遍猜测也是MoE,但是OpenAI他不open啊,所以没有定论。)
谷歌TPU v7的设计思路,是在执行大规模张量操作的同时最大限度地减少芯片上的数据移动和延迟。
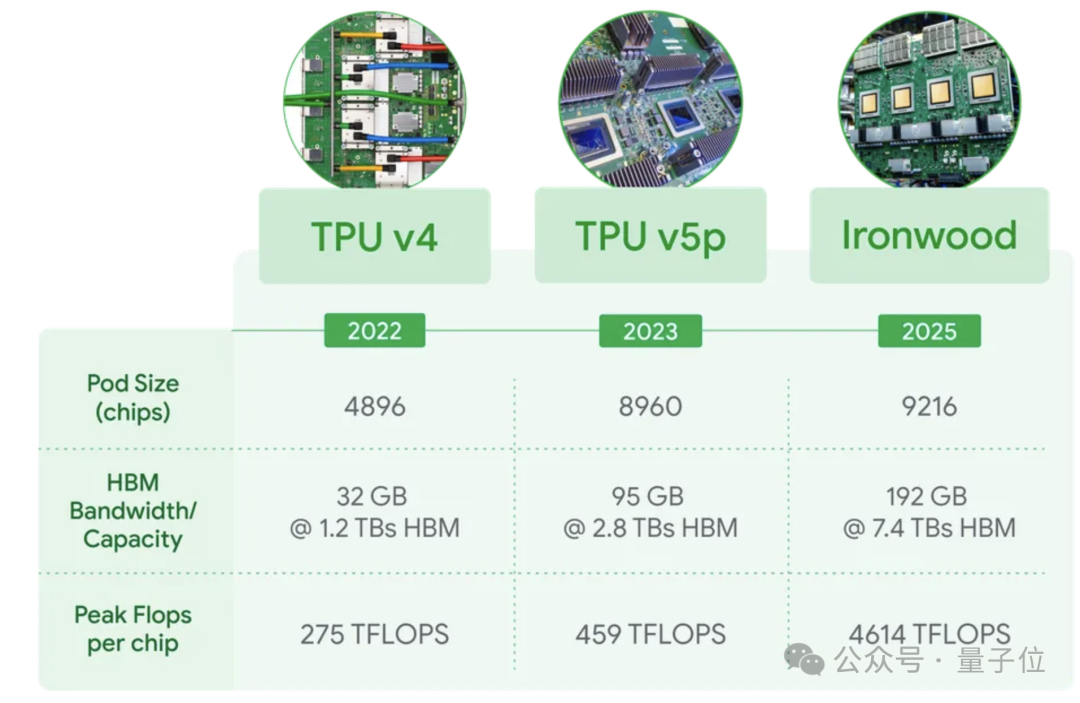
与上一代TPU v6相比,TPU v7的高带宽内存 (HBM) 容量为192GB,是上一代的6倍,同时单芯片内存带宽提升到7.2 TBps,是上一代的4.5倍。
TPU v7系统还具有低延迟、高带宽的ICI(芯片间通信)网络,支持全集群规模的协调同步通信。双向带宽提升至1.2 Tbps,是上一代的1.5倍。
能效方面,TPU v7每瓦性能也是上一代的两倍。
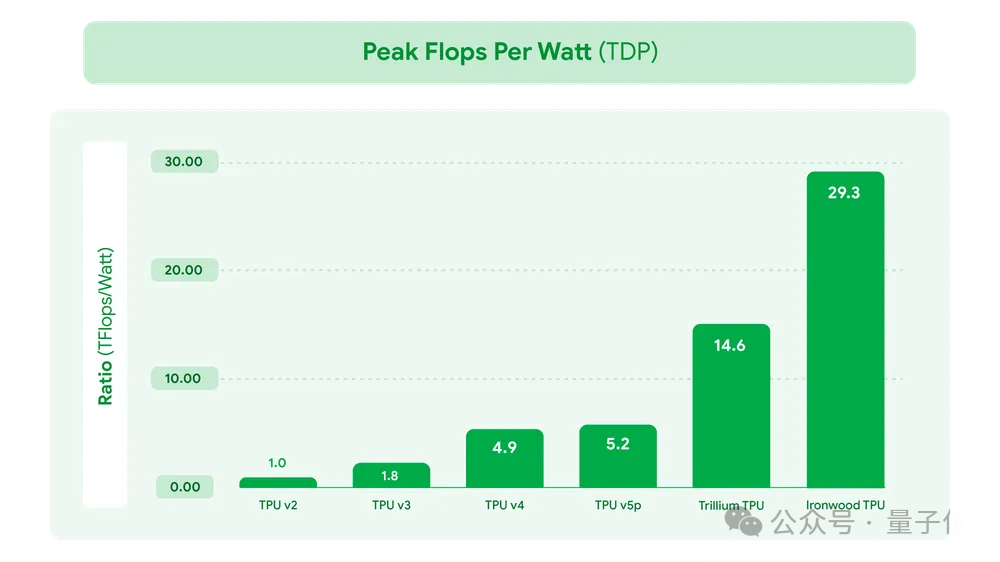
硬件介绍完,接下来看软硬协同部分。
TPU v7配备了增强版SparseCore ,这是一款用于处理高级排序和推荐工作负载中常见的超大嵌入的数据流处理器。
TPU v7还支持Google DeepMind开发的机器学习运行时Pathways,能够跨多个TPU芯片实现高效的分布式计算。
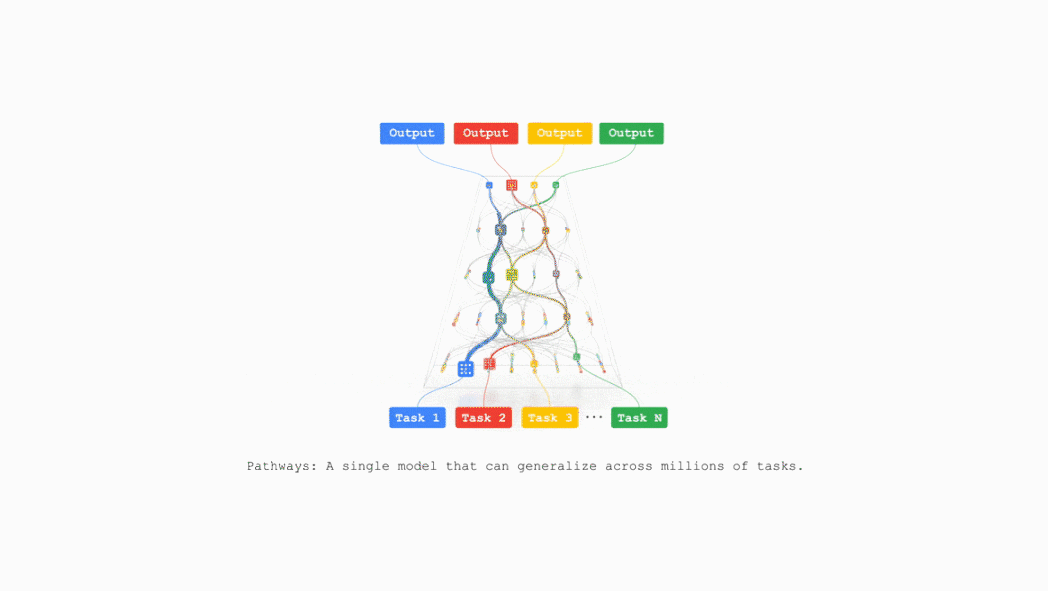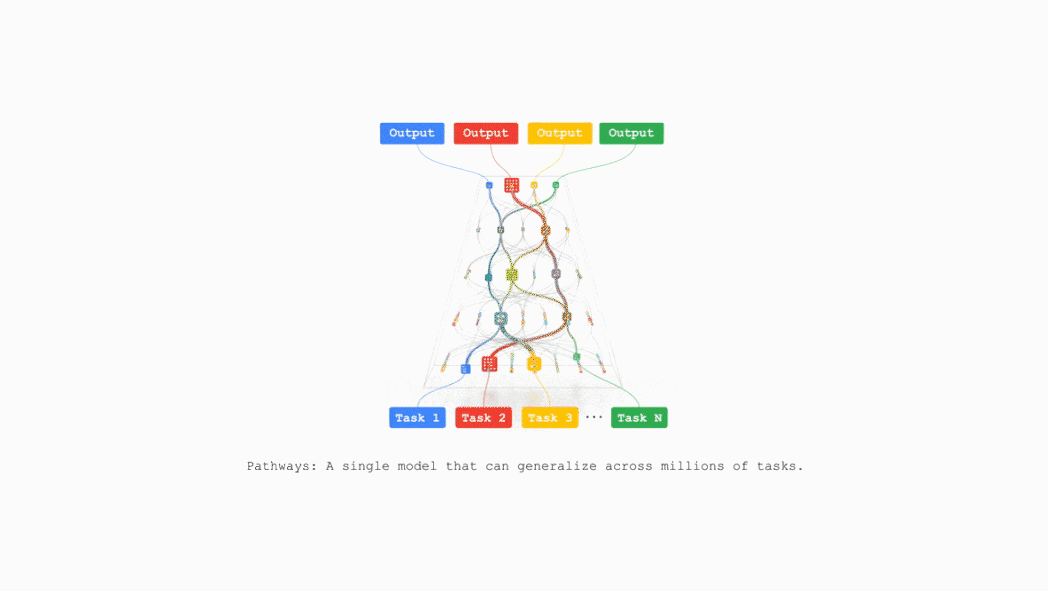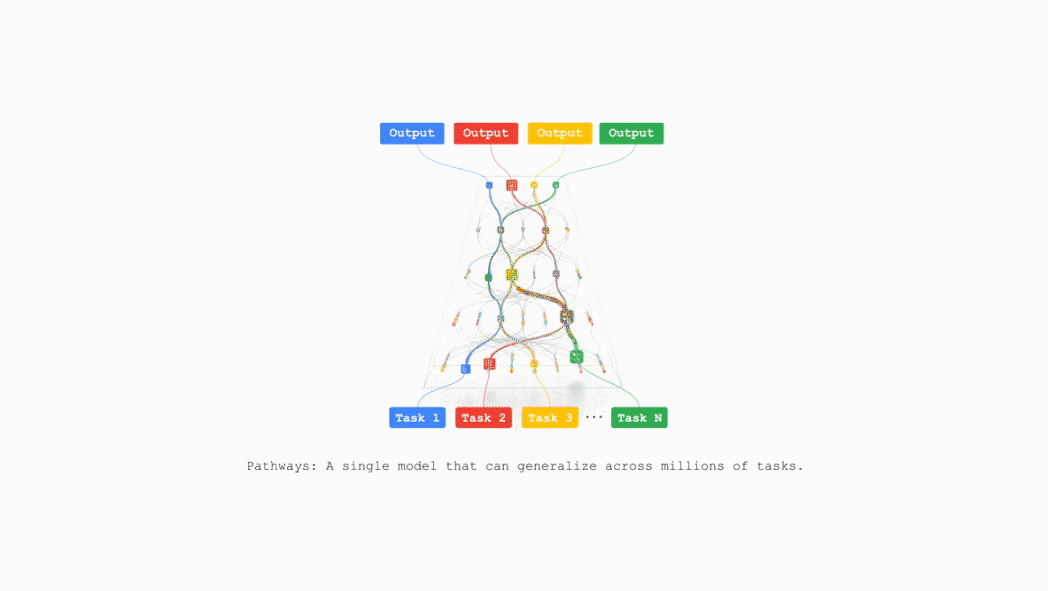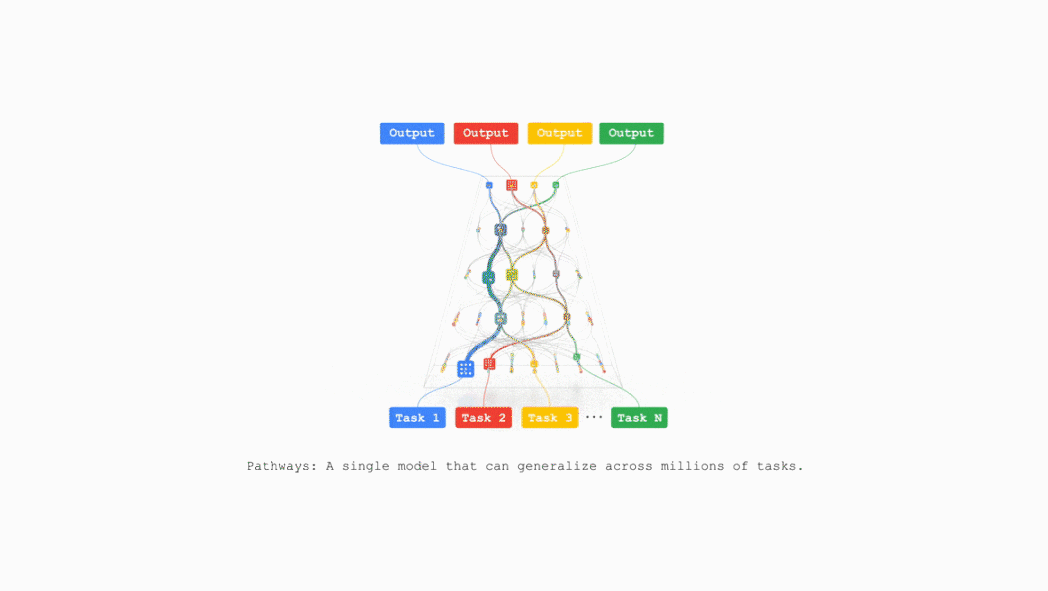
谷歌计划在不久的将来把TPU v7整合到谷歌云AI超算,支持支持包括推荐算法、Gemini模型以及AlphaFold在内的业务。
网友:英伟达压力山大了
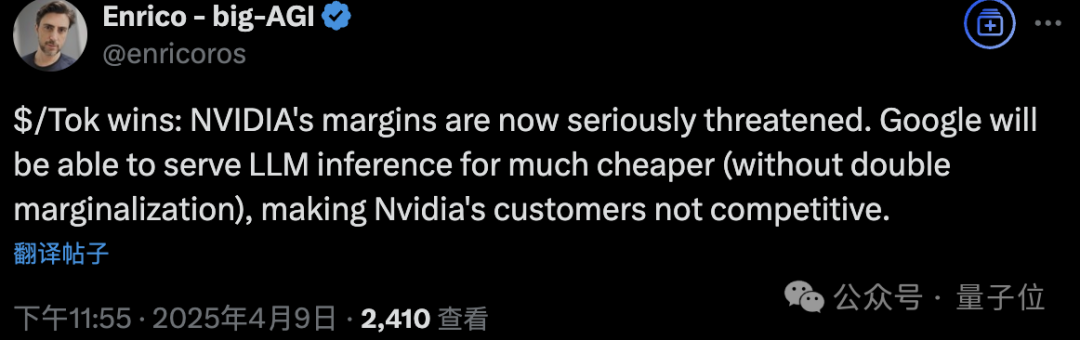
看过谷歌最新TPU发布,评论区网友纷纷at英伟达。
有人称如果谷歌能以更低的价格提供AI模型推理服务,英伟达的利润将受到严重威胁。
还有人直接at各路AI机器人,询问这款芯片对比英伟达B200如何。
简单对比一下,TPU v7的FP8算力4614 TFlops,比B200标称的4.5 PFlops(=4500 TFlops)略高。内存带宽7.2TBps,比英伟达B200的8TBps稍低一点,是基本可以对标的两款产品。
实际上除了谷歌之外,还有两个云计算大厂也在搞自己的推理芯片。
亚马逊的Trainium、Inferentia和Graviton芯片大家已经比较熟悉了,微软的MAIA 100芯片也可以通过Azure云访问。

AI芯片的竞争,越来越激烈了。
参考链接:
[1]https://blog.google/products/google-cloud/ironwood-tpu-age-of-inference/
[2]https://x.com/sundarpichai/status/1910019271180394954



















 11
11

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









