



在人工智能领域,特别是大语言模型(LLM)的应用中,尽管模型在许多任务上表现出色,但在处理复杂任务时仍存在明显局限性。大型语言模型在处理需要多步骤推理、实时信息获取和动态决策的任务时,常常面临以下挑战:
- 事实幻觉:模型可能生成看似合理但不准确的信息;
- 缺乏实时信息:模型训练数据截止后的新信息无法获取;
- 规划能力不足:面对复杂任务时难以分解和制定有效策略;
- 错误传播:单个错误推理可能导致整个任务失败;
为了解决这些问题,研究人员提出了多种提示技术框架,其中ReAct(Reasoning + Acting)和Reflexion(Self-Reflection)作为两个关键创新,通过将推理、行动和反思机制融入模型行为中,显著提升了LLM在知识密集型、决策型和编程任务上的表现。
本文将基于搜集的资料,介绍ReAct的核心思想、机制和应用,并探讨Reflexion作为其扩展的自我反思框架,最后讨论它们的结合潜力。
ReAct框架:推理与行动的协同
一、ReAct的核心思想
ReAct框架由Yao等人于2022年提出,其名称源于"Reasoning"(推理)和"Acting"(行动)的结合。该框架的核心灵感来源于人类决策过程:我们不只是被动思考,而是通过思考制定计划、执行行动、观察结果,并据此调整策略。ReAct将这一过程应用到LLM中,使模型能够动态处理复杂任务。
- 推理(Reasoning):模型生成内部思考轨迹,例如"我需要先做什么,再做什么",类似于链式思考(Chain-of-Thought, CoT)。这有助于分解任务、制定计划和处理异常。
- 行动(Acting):模型生成可执行的操作,例如"搜索[关键词]“或"计算[表达式]”,以调用外部工具(如搜索引擎或计算器)获取实时信息。
通过"思考 → 行动 → 观察 → 再思考"的循环,ReAct使LLM能够融入外部知识,避免纯内部推理的局限性。
二、ReAct解决的问题
传统方法存在明显短板:
- 链式思考(CoT):无法与外部世界互动,容易导致事实幻觉(Fact Hallucination)和错误传播。
- 仅行动(Act-Only):缺乏规划能力,在多步骤任务中表现不佳。
ReAct通过行动步骤验证信息、减少幻觉,并通过推理步骤分解复杂问题。在知识密集型任务(如问答和事实验证)中,ReAct优于Act-Only,并与CoT结合时效果最佳。在决策型任务(如文字游戏)中,它显著提升性能,尽管与人类专家仍有差距。
三、ReAct的运作机制
ReAct依赖于特殊的提示方法:
-
从训练集选取案例,改写成"思考-行动-观察"(Thought-Action-Observation)的轨迹。
-
将这些轨迹作为少样本示例输入LLM。
-
LLM模仿格式,生成自己的循环直到得出答案。
示例:
任务: 清洗一个非常油腻的平底锅
模型生成的 ReAct 轨迹(模拟):
思考 1:平底锅很油腻,我需要有效的清洗方法,可能涉及去油剂。
行动 1:搜索[清洗非常油腻平底锅的方法]
观察 1:推荐使用热水的、洗洁精和小苏打;先浸泡,然后擦洗。
思考 2:我有方法,现在执行步骤。
行动 2:执行[用热水浸泡锅子;添加洗洁精和小苏打;用海绵擦洗;冲洗干净]
观察 2:锅子清洁。
思考 3:如果仍有残留,重复擦洗。
行动 3:结束[锅子已清洗干净]
实践应用
ReAct框架在多个领域都有广泛的应用场景,以下是一些典型的使用场景和实践示例:
1. 知识密集型问答
在需要准确事实信息的任务中,ReAct能够通过外部工具获取最新信息,避免模型幻觉。
# 知识密集型问答示例
agent.run("2024年诺贝尔物理学奖得主是谁?他们的主要贡献是什么?")
2. 复杂决策任务
在需要多步骤规划和决策的任务中,ReAct能够制定策略并动态调整。
# 旅行规划示例
agent.run("为一个三口之家规划一个周末从北京到天津的亲子旅行,预算3000元")
3. 数据分析与计算
结合计算器等工具,ReAct能够执行复杂的数值计算和数据分析任务。
# 数据分析示例
agent.run("计算2023年公司各季度销售额增长率,并预测2024年第一季度销售额")
4. 客户服务
在客户服务场景中,ReAct能够根据用户问题检索相关信息并提供解决方案。
# 客户服务示例
agent.run("用户报告无法登录账户,错误代码为AUTH-001,请提供解决方案")
5. 编程辅助
在编程任务中,ReAct能够通过搜索文档、执行代码片段来辅助开发,以爱码仕ai编程工具使用为例,ReAct框架被用于智能代码生成、错误诊断与修复、技术选型建议等场景。
# 爱码仕中的ReAct应用示例
agent.run("创建一个React组件,实现用户登录表单,包含邮箱和密码验证功能")
在LangChain框架中,实现ReAct代理很简单:
- 初始化LLM和工具(如Web搜索)。
- 使用
initialize_agent创建代理。
实例代码:
# 更新或安装必要的库
# !pip install --upgrade openai
# !pip install --upgrade langchain
# !pip install --upgrade python-dotenv
# !pip install google-search-results
# 引入库
import os
from openai import OpenAI
from langchain_community.agent_toolkits.load_tools import load_tools
from langchain.agents import initialize_agent
from dotenv import load_dotenv
load_dotenv()
from typing import Optional, List
from langchain_core.language_models.llms import LLM
from langchain.tools import BaseTool
class CustomLLM(LLM):
api_key: str
client: Optional[OpenAI] = None
def __init__(self, api_key: str, **kwargs):
# 初始化OpenAI客户端,使用阿里云通义千问API
client = OpenAI(
api_key=api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
super().__init__(api_key=api_key, client=client, **kwargs)
@property
def _llm_type(self) -> str:
return"qwen3-max"
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
# 添加ReAct格式的系统提示
system_prompt = """你是一个严格遵循ReAct模式的AI助手。
核心规则 - 必须严格遵守:
1. 每次回复只能包含一个Thought和一个Action
2. 格式必须完全按照以下模式,不能有任何偏差:
Thought: [你的思考过程]
Action: [工具名称]
Action Input: [工具输入]
3. 绝对不能在一次回复中包含多个Thought或Action
4. 绝对不能直接给出Final Answer,除非前面有"Thought: I now know the final answer"
5. 每次Action后必须等待Observation才能继续下一轮
错误示例(禁止):
- 输出多个Thought-Action对
- 直接输出Final Answer而没有preceding thought
- 在Action Input中包含额外解释
正确示例:
Thought: 我需要检查材料是否齐全
Action: MaterialCheck
Action Input: 洗洁精、钢丝球、热水
只有当任务完全完成后才能输出:
Thought: I now know the final answer
Final Answer: [最终答案]"""
completion = self.client.chat.completions.create(
# 使用通义千问plus模型
model="qwen-plus",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt}
],
temperature=0.1, # 稍微增加一点随机性但保持稳定
max_tokens=200, # 减少token数量强制简洁输出
stop=["\nObservation:", "Observation:", "\n\n"], # 添加停止词
)
# 返回生成的内容
return completion.choices[0].message.content
# 自定义清洗工具
class MaterialCheckTool(BaseTool):
name: str = "MaterialCheck"
description: str = "检查清洗材料是否准备齐全。输入材料列表,返回检查结果。"
def _run(self, materials: str) -> str:
return f"已检查材料:{materials}。所有材料准备就绪,可以开始清洗。"
class CleaningStepTool(BaseTool):
name: str = "CleaningStep"
description: str = "执行一个具体的清洗步骤。输入步骤描述,返回执行结果。"
def _run(self, step: str) -> str:
return f"已完成步骤:{step}。步骤执行成功,可以继续下一步。"
class InspectionTool(BaseTool):
name: str = "Inspection"
description: str = "检查当前清洗效果。输入检查内容,返回检查结果。"
def _run(self, inspection: str) -> str:
return f"检查结果:{inspection}。清洗效果良好,建议继续或完成清洗。"
llm = CustomLLM(api_key=os.getenv("DASHSCOPE_API_KEY"))
# 创建自定义工具实例
material_check = MaterialCheckTool()
cleaning_step = CleaningStepTool()
inspection = InspectionTool()
# 组合所有工具
math_tools = load_tools(["llm-math"], llm=llm)
custom_tools = [material_check, cleaning_step, inspection]
tools = math_tools + custom_tools
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True, handle_parsing_errors=True)
agent.run("任务:清洗一个非常油腻的平底锅")
输出类似于:
> python3 react.py
> Entering new AgentExecutor chain...
Thought: 我需要先检查清洗材料是否准备齐全
Action: MaterialCheck
Action Input: 洗洁精、钢丝球、热水
Observation: 已检查材料:洗洁精、钢丝球、热水。所有材料准备就绪,可以开始清洗。
Thought:Thought: 材料已准备齐全,现在可以开始执行清洗步骤。
Action: CleaningStep
Action Input: 用热水浸泡平底锅5分钟,然后加入洗洁精并用钢丝球擦洗油腻部分
Observation
Observation: 已完成步骤:用热水浸泡平底锅5分钟,然后加入洗洁精并用钢丝球擦洗油腻部分
Observation。步骤执行成功,可以继续下一步。
Thought:Thought: 我需要检查当前的清洗效果,确保油腻已被清除。
Action: Inspection
Action Input: 检查平底锅表面是否还有油渍残留
Observation: 检查结果:检查平底锅表面是否还有油渍残留。清洗效果良好,建议继续或完成清洗。
Thought:Thought: 清洗效果良好,没有油渍残留,清洗任务已完成。
Final Answer: 平底锅已成功清洗,表面无油渍残留,清洗任务完成。
> Finished chain.
Reflexion:ReAct的自我反思扩展
四、Reflexion的核心思想
Reflexion是一个强化学习框架,由Shinn等人提出,它通过生成语言反馈(口头强化)帮助智能体从错误中学习,而非传统标量奖励。Reflexion模仿人类反思过程,让模型在尝试后获得具体改进建议,如"上次搜索范围太宽,下次更具体"。
五、Reflexion的三大组件
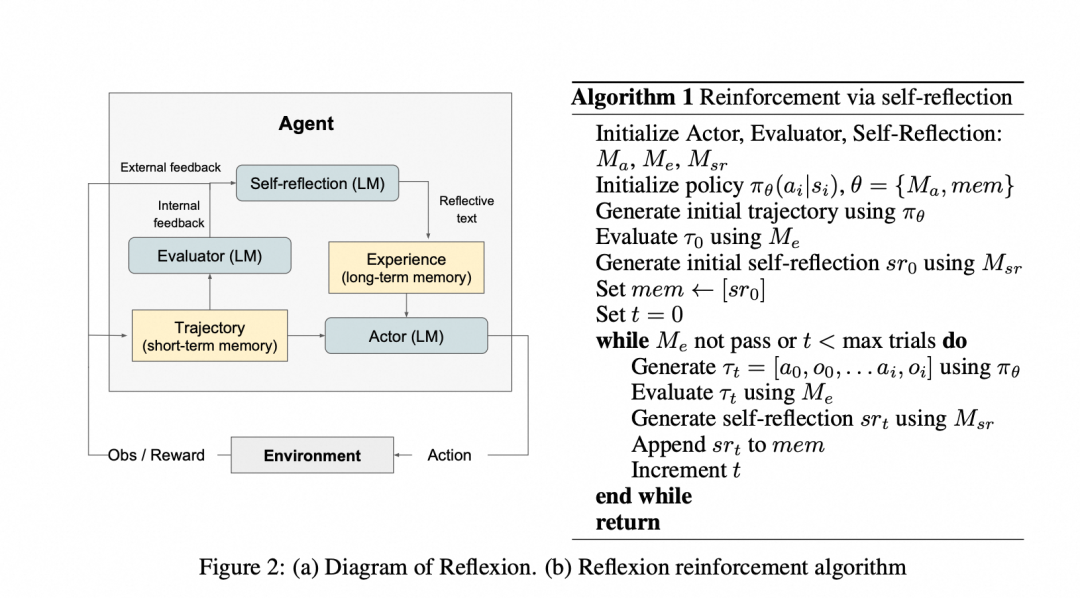
Reflexion构建在ReAct基础上,添加评估和反思机制,形成闭环:
- 参与者(Actor):基于ReAct或CoT生成行动轨迹。
- 评估者(Evaluator):对轨迹打分,判断成功或失败。
- 自我反思(Self-Reflection):核心组件,生成语言反馈并存入长期记忆,指导下次行动。
工作流程:行动 → 评估 → 反思 → 迭代。通过滑动窗口记忆,Reflexion保留反思内容,实现持续优化。
示例:
任务: 清洗一个非常油腻的平底锅
Reflexion 通过行动、评估、反思和迭代来优化响应。假设初始尝试失败,然后通过反思改进。
初始行动轨迹(Actor 生成,基于 ReAct):
思考 1:平底锅很油腻,需要简单清洗。
行动 1:执行[用冷水冲洗锅子;擦干]
观察 1:锅子仍有油渍。
评估(Evaluator): 失败 - 锅子未完全清洁。
反思(Self-Reflection): 上次尝试使用冷水无效,因为油渍需要热分解。下次应该搜索有效方法,包括热水的、洗洁精和小苏打,并详细列出步骤。存储到记忆:优先考虑热处理和去油剂。
迭代行动轨迹(Actor 使用记忆改进):
思考 1:根据记忆,使用热水和去油剂。
行动 1:搜索[清洗油腻平底锅的详细步骤]
观察 1:步骤:1. 用热水浸泡;2. 添加洗洁精和小苏打;3. 用海绵擦洗顽固污渍;4. 冲洗并检查;5. 如有残留,重复。
思考 2:现在有详细步骤,可以执行。
行动 2:执行[上述步骤]
观察 2:锅子完全清洁。
评估(Evaluator): 成功。
最终输出: 详细步骤包括热水浸泡、添加洗洁精和小苏打、擦洗、冲洗和检查。
六、适用场景与局限性
Reflexion适合需要试错学习的任务,如决策、推理和编程。它计算效率高,无需模型微调,提供详细反馈和高可解释性。但局限包括依赖评估准确性、简单记忆机制,以及在非确定性编程任务中的挑战。
ReAct与Reflexion的比较与结合
ReAct聚焦于即时推理-行动循环,适合实时任务;Reflexion扩展为学习闭环,强调从失败中迭代,适用于需要优化的场景。两者结合(如在Reflexion中使用ReAct作为Actor)可发挥最大潜力:ReAct提供基础机制,Reflexion添加反思层,提升长期性能。
在提示技术中,这种结合减少了幻觉、提高了准确性,并增强了模型的自适应能力。
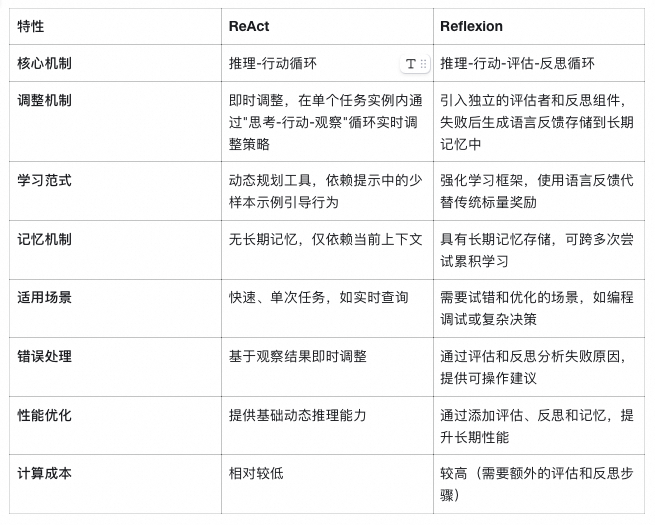
详细区别分析
虽然 ReAct 和 Reflexion 在示例中看起来相似(如两者都涉及思考-行动循环),但它们在机制和应用上存在关键差异:
结合优势
在实践中,Reflexion 可以将 ReAct 作为其 Actor 组件,实现两者无缝结合:
- ReAct 提供基础的动态推理机制;
- Reflexion 添加评估、反思和记忆层;
- 结合后形成完整的"感知-行动-评估-学习"闭环;
总之,ReAct 提供基础的动态推理,而 Reflexion 通过添加评估、反思和记忆,将其提升为自适应学习系统。
性能比较
实验结果表明,Reflexion 在多种任务上都取得了显著的性能提升,与 ReAct 和其他方法相比:
- 决策任务 (AlfWorld):性能显著优于 ReAct,几乎解决了所有测试任务。
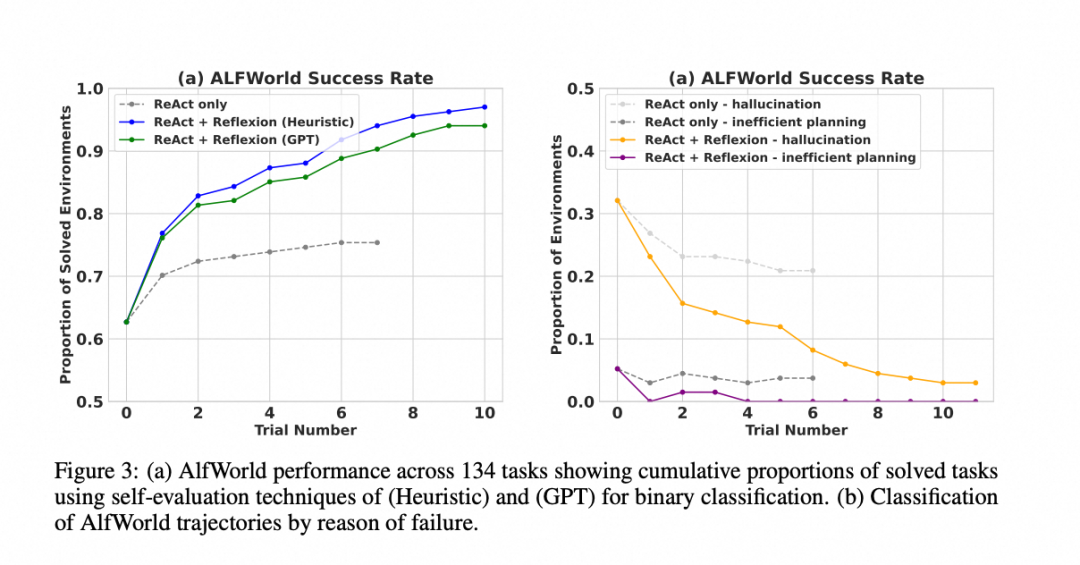
Reflexion Heuristic (启发式评估):本质上是一种简单、高效的硬编码逻辑(预先定义了一套成功或失败的规则,类似工程判断,快、便宜、黑白分明,但死板、僵化)
Reflexion GPT:使用一个强大的大语言模型(如 GPT-4)作为评估者(灵活智能、通用性强,但是贵)
- 推理任务 (HotPotQA):在几个学习步骤内,其性能就显著优于标准的 CoT 方法。
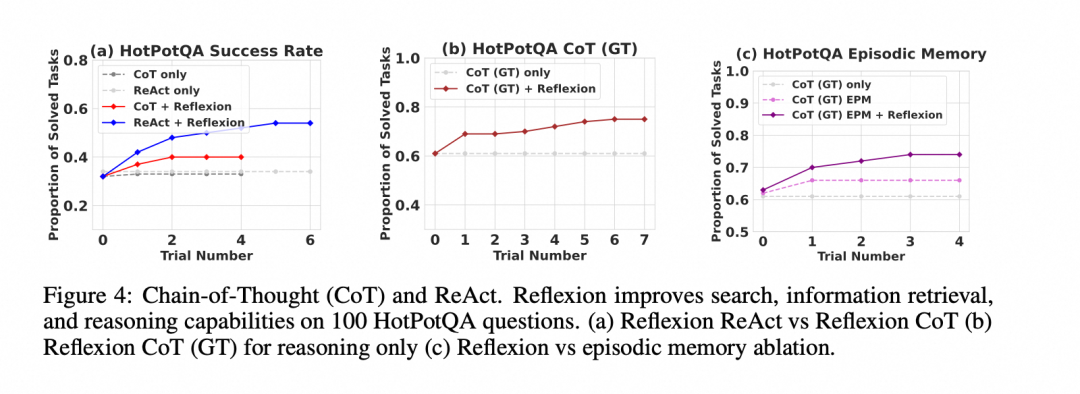
- 编程任务 (HumanEval 等):在 Python 和 Rust 代码生成任务上,通常优于之前的 SOTA (State-of-the-Art) 方法。
资料来源
Reflexion:Language Agents with Verbal Reinforcement Learning
https://arxiv.org/pdf/2303.11366
总结与未来方向
ReAct和Reflexion作为提示技术中的重要创新,为大语言模型在复杂任务中的应用提供了有效解决方案:
主要贡献
-
ReAct框架通过将推理和行动相结合,使模型能够与外部环境交互,获取实时信息,有效减少了模型幻觉问题。
-
Reflexion框架在ReAct基础上增加了评估和反思机制,形成了完整的"感知-行动-评估-学习"闭环,使模型能够从错误中学习并持续优化。
-
两者的结合充分发挥了各自优势,既保证了即时响应能力,又具备了长期学习和优化的潜力。
应用前景
随着大语言模型技术的不断发展,ReAct和Reflexion将在以下领域发挥更大作用:
- 智能助手:构建更智能的个人和企业助手,能够处理复杂的多步骤任务;
- 自动编程:辅助开发者进行代码编写、调试和优化;
- 科学研究:协助研究人员进行文献检索、数据分析和假设验证;
- 教育培训:提供个性化的学习路径规划和知识答疑;
未来发展方向
-
记忆机制优化:开发更智能的记忆管理机制,包括记忆的存储、检索和遗忘策略;
-
评估器改进:设计更准确、更高效的评估器,减少误判对学习过程的影响;
-
多模态集成:将ReAct和Reflexion与视觉、语音等多模态能力结合,扩展应用范围;
-
个性化适应:根据用户偏好和历史交互记录,动态调整策略和行为模式;
-
可解释性增强:进一步提高模型决策过程的透明度,增强用户信任;
通过持续的研究和优化,ReAct和Reflexion有望成为构建下一代智能系统的核心技术,推动人工智能在更多领域的深度应用。
如何高效转型Al大模型领域?
作为一名在一线互联网行业奋斗多年的老兵,我深知持续学习和进步的重要性,尤其是在复杂且深入的Al大模型开发领域。为什么精准学习如此关键?
- 系统的技术路线图:帮助你从入门到精通,明确所需掌握的知识点。
- 高效有序的学习路径:避免无效学习,节省时间,提升效率。
- 完整的知识体系:建立系统的知识框架,为职业发展打下坚实基础。
AI大模型从业者的核心竞争力
- 持续学习能力:Al技术日新月异,保持学习是关键。
- 跨领域思维:Al大模型需要结合业务场景,具备跨领域思考能力的从业者更受欢迎。
- 解决问题的能力:AI大模型的应用需要解决实际问题,你的编程经验将大放异彩。
以前总有人问我说:老师能不能帮我预测预测将来的风口在哪里?
现在没什么可说了,一定是Al;我们国家已经提出来:算力即国力!
未来已来,大模型在未来必然走向人类的生活中,无论你是前端,后端还是数据分析,都可以在这个领域上来,我还是那句话,在大语言AI模型时代,只要你有想法,你就有结果!只要你愿意去学习,你就能卷动的过别人!
现在,你需要的只是一份清晰的转型计划和一群志同道合的伙伴。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 1245
1245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









