




 本文详细介绍了平衡树的基础概念,包括BST的性质、插入、删除和查询操作。接着,深入探讨了伸展树(Splay)和Treap两种常见的平衡树,以及它们在解决区间操作上的优缺点。最后,提到了树套树的概念,即线段树与平衡树的结合,用于处理区间问题。
本文详细介绍了平衡树的基础概念,包括BST的性质、插入、删除和查询操作。接着,深入探讨了伸展树(Splay)和Treap两种常见的平衡树,以及它们在解决区间操作上的优缺点。最后,提到了树套树的概念,即线段树与平衡树的结合,用于处理区间问题。
平衡树学不会的,这辈子都学不会的
一、前置芝士
平衡树本质上看是一种 BST(二叉排序树)
而 BST 其实是一种非常容易理解的良心数据结构
BST 保证了这颗树的中序遍历是单调上升的
举个例子:
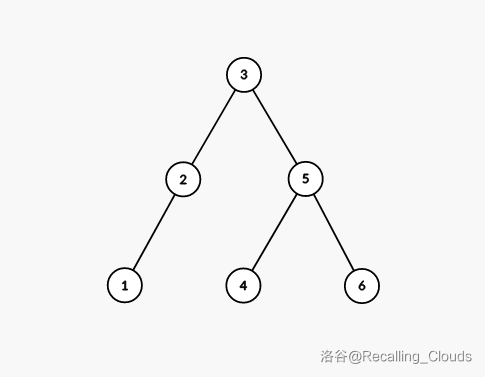
BST 支持插入、删除以及查询等多种操作,我们一一来讲述
- 插入
插入很简单
我们知道二叉排序树有一个性质:对于每一个结点,设它的点权为 v a l val val,那么它的左子树中的每一个点权值必定小于 v a l val val,它的右子树中的每一个点权值必定大于 v a l val val
插入时我们对于当前访问到的点的权值分讨
-
如果这个点的权值等于插入点的权值,直接放在这个点上即可,有的题目会把计数器加 1
-
如果这个点的权值小于插入点的权值,跳右子树
-
如果这个点的权值大于插入点的权值,跳左子树
最后,如果访问到一个空点,那么就把空点变成这个插入点即可
- 查询
为什么先讲查询呢?
其一是因为删除操作较为复杂
其二是因为删除操作将要涉及到一些新的概念,我们先在查询中阐述
首先有一种常见的查询——第 K 大数
我们仍然利用 BST 的性质,每访问到一个点,就对于子树的大小情况进行如下分讨:
-
如果左子树的大小加 1 刚好等于 K,那么访问到的点即为答案
-
如果左子树大小小于等于 K,跳左子树
-
如果左子树大小大于 K + 1,我们把 K 减去左子树的大小,再减去 1,随后跳右子树
为什么要减掉一定的大小呢?
因为第 K 大指的是以当前访问到的点为根的子树的第 K 大
如果访问左子树那没有关系
如果访问右子树,那么这个第 K 大,需要减去左子树的大小,再减去当前访问到的这个点(大小为 1),才能往右子树跳
然后是另外一种形式的查询——前驱和后继
在单调上升的有序数列中,一个数的前驱即为它的前一个数,后继即为它的后一个数
换句话说,一个数的前驱是小于这个数的最大数,后继是大于这个数的最小数
(如果您觉得上述定义有歧义,那么你可以把本文中出现的所有前驱和后继理解为直接前驱和直接后继)
查询就比较简单了,也是对于当前访问到的点的权值分讨,这里就不在阐述
- 删除
前面说了,删除操作比较复杂
因为它需要考虑多种情况
下面我们一一来讨论:
- 叶子结点
最简单的情况,直接删除即可(具体实现会有多种方式,对应多种不同的效果)
- 仅有一个子树的结点
由于仅有一个子树,那么我们可以直接用它的唯一子树代替这个结点
代替说得更具体一点,就是把这个唯一子树的根节点放在被删除的结点的位置
举个例子,在上文给出的图中,2 号结点是满足条件的一个结点
假设我们现在要删除 2 号结点
那么它唯一子树的根节点即为 1 号结点,我们直接用 1 号结点替换掉 2 号结点即可
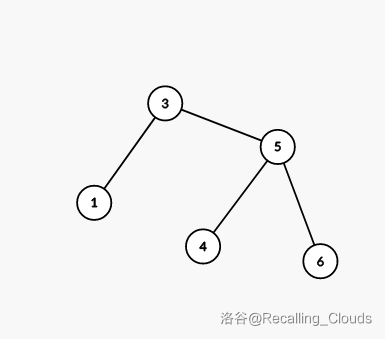
- 有两个子树的结点
有两个子树的结点,我们就不能直接用子树的根替换删除掉的结点了(因为有两个根)
还是拿上文给出的图举例:
假设我们现在要删掉 3 号结点
我们在序列中来看这个操作造成的影响:
原序列: 1 2 3 4 5 6
新序列: 1 2 4 5 6
可以发现,3 号结点的前驱和后继接在了一起
那么我们任取前驱和后继中的一个放在这个删除的结点位置即可
如果你选的这个点是一个叶子结点,直接放即可
如果不是,可以证明它的父亲一定是被删除的结点,直接类似第二种情况替换即可
然而,学会了这些操作,你的平衡树才刚刚入门
为什么???
(因为你学的东西是 BST,而这玩意叫平衡树)
平衡树,顾名思义,它会保证整颗树趋于相对平衡
那为什么 BST 就不平衡呢?
举个例子,如果你按照 1 2 3 4 5 6 7 8 的顺序插入,那么这颗树会退化成一条链
而前面三个操作的复杂度是 O ( h ) O(h) O(h) 的, h h h 为树的深度
也就是说,如果数据中出现了一些比较长的单调上升子段,那么树的高度会很高,操作的时间复杂度从会从最优的 O ( log 2 n ) O(\log_2n) O(log2n) 退化至 O ( n ) O(n) O(n)
为了解决这种情况,伟大的数据结构——平衡树应运而生
(注意:各类平衡树的以上三种操作都是大同小异的,区别在于平衡整颗树的方法)
二、常见的平衡树
1. S p l a y 1.~Splay 1. Splay
S p l a y Splay Splay 又称伸展树,它的很多操作都基于伸展操作
而伸展操作又是基于旋转操作
旋转操作是平衡树的一种基本操作,用于调整一颗树至平衡状态,除了 S p l a y Splay Splay 外,下文将要介绍的 T r e a p Treap Treap 也会有这种操作
下面来介绍一下旋转操作:
旋转分为左旋和右旋,又称 zag 和 zig,但是它的本质都是一个结点往它的父结点旋转,区别仅在于被旋转的结点是左儿子还是右儿子,所以下文在讲解过程中不一定会作区分
放一张图:
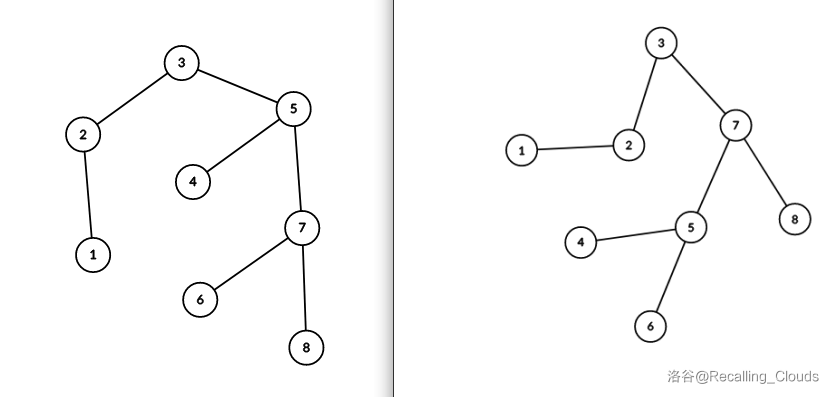
在左边的树中,我们把 7 号结点旋转,即可得到右边的树
同理,在右边的树中,如果我们把 5 号结点旋转,即可得到左边的树
拿左边的树旋转到右边来举例,在一次旋转中,3、5、6、7 四个结点的父子关系会有所改变
它们分别对应:爷爷、爸爸、自己和儿子
其中儿子有一些特殊,因为儿子相对自己的方向和自己相对爸爸的方向是相反的
可以发现旋转之后,树的结构仍然保持 BST 的性质,这就是我们想要的效果
给出示例代码:
void Rotate(int u)
{
int f = fa[u], g = fa[f], k = (son[f][1] == u); //k = 0 表示左儿子,反之则表示右儿子
son[g][son[g][1] == f] = u, fa[u] = g;
son[f][k] = son[u][k ^ 1], fa[son[u][k ^ 1]] = f;
son[u][k ^ 1] = f, fa[f] = u;
return Pushup(f), Pushup(u); //要先上传点 f 的信息,再上传点 u 的信息,很多情况下不需要上传点 g 的信息(如果点 f 原本为根节点,那么点 g 甚至不存在)
}
中间的三个转换关系可以自己手推一下,如果弄懂了其实就会很简单
那么下面就进入到伸展操作:
伸展操作可以简单描述为把某个结点一直旋转到自己祖先的下方,成为这个祖先的儿子,如果祖先为 0 则表示把这个结点转到根结点上
所以,伸展操作实际上并不是所谓的平衡操作,而是一种重构树的方法,类似搜索引擎,把可能会访问到较多次的结点尽量靠近根,这样每次操作的均摊复杂度是 O ( log 2 n ) O(\log_2n) O(log2n)
你可以通过把一个结点不断往上旋转 ,然后就会被某些毒瘤数据给卡掉
为了避免这种情况产生,我们采用双旋的方法
下面给出伸展操作的代码:
void Splay(int u, int to = 0)
{
while(fa[u] != to)
{
int f = fa[u], g = fa[f];
if(g != to) (son[f][1] == u) ^ (son[g][1] == f) ? Rotate(u) : Rotate(f); //第一次旋转,如果点 u 和点 f 相对于自己父亲的方向相同,就把点 f 旋转上去,否则把点 u 旋转上去
Rotate(u); //第二次旋转,把点 u 旋转上去
}
if(!to) rt = u; //特判点 u 旋转到根结点的情况
return;
}
至于具体证明,有兴趣的读者可以参考
S
p
l
a
y
Splay
Splay 原论文,这里不再阐述 (其实是根本不会)
如果实在理解不了,你可以拿一条链,把链底转到链顶,看看单旋和双旋的区别
可以发现,单旋后的树还是一条链,不过双旋后整颗树的深度规模整整缩小了一半!
这就是双旋的优势所在,所以以后一定别用单旋!
下面给出 P3369 【模板】普通平衡树 的 S p l a y Splay Splay 写法:
#include<iostream>
#include<cstdio>
#include<cstdlib>
#define MAXN 500005
#define INF 0x7FFFFFFF
using namespace std;
int n, tot = 0, rt = 0;
struct Tree { int fa, son[2], val, si, cnt; } t[MAXN];
void Link(int x, int y, int k)
{
t[x].son[k] = y;
t[y].fa = x;
return;
}
void Update(int x)
{
t[x].si = t[x].cnt;
if(t[x].son[0]) t[x].si += t[t[x].son[0]].si;
if(t[x].son[1]) t[x].si += t[t[x].son[1]].si;
return;
}
void Rotate(int x)
{
int y = t[x].fa, z = t[y].fa, k = (t[y].son[1] == x);
Link(z, x, (t[z].son[1] == y));
Link(y, t[x].son[k ^ 1], k);
Link(x, y, k ^ 1);
Update(y); Update(x);
return;
}
void Splay(int x, int Goal)
{
while(t[x].fa != Goal)
{
int y = t[x].fa, z = t[y].fa;
if(z != Goal) (t[z].son[1] == y) ^ (t[y].son[1] == x) ? Rotate(x) : Rotate(y);
Rotate(x);
}
if(!Goal) rt = x;
return;
}
void Insert(int x)
{
int u = rt, f = 0;
while(u && t[u].val != x)
{
f = u;
u = t[u].son[x > t[u].val];
}
if(u) t[u].cnt++;
else
{
u = ++tot;
if(f) t[f].son[x > t[f].val] = u;
t[u].fa = f;
t[u].son[0] = t[u].son[1] = 0;
t[u].val = x;
t[u].cnt = t[u].si = 1;
}
Splay(u, 0);
return;
}
void Find(int x)
{
int u = rt;
if(!u) return;
while(t[u].son[x > t[u].val] && t[u].val != x) u = t[u].son[x > t[u].val];
Splay(u, 0);
return;
}
int Get(int x, int k)
{
Find(x);
int u = rt;
if((k && t[u].val > x) || (!k && t[u].val < x)) return u;
u = t[u].son[k];
while(t[u].son[k ^ 1]) u = t[u].son[k ^ 1];
return u;
}
void Delete(int x)
{
int p = Get(x, 0), s = Get(x, 1);
Splay(p, 0); Splay(s, p);
int k = t[s].son[0];
if(t[k].cnt > 1)
{
t[k].cnt--;
Splay(k, 0);
}
else t[s].son[0] = 0;
}
int Get_Number(int x)
{
int u = rt;
if(t[u].si < x) return 0;
while(true)
{
if(x > t[t[u].son[0]].si && x <= t[t[u].son[0]].si + t[u].cnt) return t[u].val;
if(x <= t[t[u].son[0]].si) u = t[u].son[0];
else
{
x -= t[t[u].son[0]].si + t[u].cnt;
u = t[u].son[1];
}
}
}
int main()
{
Insert(INF); Insert(-INF);
scanf("%d", &n);
for(int i = 1; i <= n; i++)
{
int tp, x;
scanf("%d%d", &tp, &x);
if(tp == 1) Insert(x);
if(tp == 2) Delete(x);
if(tp == 3) { Find(x); printf("%d\n", t[t[rt].son[0]].si); }
if(tp == 4) printf("%d\n", Get_Number(x + 1));
if(tp == 5) printf("%d\n", t[Get(x, 0)].val);
if(tp == 6) printf("%d\n", t[Get(x, 1)].val);
}
return 0;
}
可以发现在插入和查询操作中都有伸展操作,这是为了使整颗树尽量平衡以保证时间复杂度,尽量不要少写也不要多写 (因为邪恶的出题人会想尽办法卡你)
2. T r e a p 2.~Treap 2. Treap
T r e a p Treap Treap 实际上是 T r e e Tree Tree 和 H e a p Heap Heap 两个单词的结合
顾名思义,它在保证了 BST 性质的同时,也保证了堆的性质
而这个堆的比较键值是什么呢?
(不会是随机吧)
没错,就是随机数!这样它的期望复杂度仍是 O ( n log 2 n ) O(n \log_2 n) O(nlog2n) 的!
(所以你如果人品不好用这玩意会 T 掉)
在插入或者删除掉一个数的时候,我们同样需要用到 S p l a y Splay Splay 中讲到的旋转操作,使得整颗树满足堆的性质
具体代码就不给了 (因为人品不太好所以一直不敢写)
我们来看看这道题目:P3391 【模板】文艺平衡树
对于 S p l a y Splay Splay 来说,我们只要做两次伸展操作,就可以使某一个子树代表这个区间内的所有数了,然后我们就可以直接在这个子树的根上打一个翻转标记,类似线段树一样延迟下传即可
但是 T r e a p Treap Treap 在元素固定的时候是静态的,你破坏不了它的结构
所以 T r e a p Treap Treap 有一个劣势就是很难进行区间操作
但是,伟大的队爷 fhq 发明了一种可以支持区间操作的 Treap,并且可以省去繁琐的旋转操作!
这种 T r e a p Treap Treap 被称做 f h q _ T r e a p fhq\_Treap fhq_Treap,也叫做无旋 T r e a p Treap Treap
f h q _ T r e a p fhq\_Treap fhq_Treap 主要基于两种操作: S p l i t Split Split 和 M e r g e Merge Merge
其中的 M e r g e Merge Merge 并不仅仅只是单纯的两颗平衡树的合并
为什么?看完 S p l i t Split Split 你就明白了
S p l i t Split Split 操作是指按照某一个分界点把整颗树分成两个部分
分为两种,一种是权值分裂,另一种是排名分裂,这里给出后者的代码:
void Split(int now, int k, int &a, int &b)
{
if(!now) a = b = 0;
else
{
if(si[ls[now]] < k) a = now, Split(rs[now], k - si[ls[now]] - 1, rs[now], b); //把当前结点分到 a 中,跳向右子树
else b = now, Split(ls[now], k, a, ls[now]); //把当前结点分到 b 中,跳向左子树
}
return Pushup(now);
}
那么 M e r g e Merge Merge 操作实际上就是把分裂出来的两颗树合并:
int Merge(int a, int b)
{
if(!a || !b) return (a + b);
if(rd[a] < rd[b]) //比较随机权值
{
rs[a] = Merge(rs[a], b);
return Pushup(a), a;
}
else
{
ls[b] = Merge(a, ls[b]);
return Pushup(b), b;
}
}
所以,使用 f h q _ T r e a p fhq\_Treap fhq_Treap,我们可以通过分裂操作,弄出一个表示操作区间的子树,然后打标记即可
代码:
#include<iostream>
#include<cstdio>
#include<cstdlib>
#define MAXN 100005
using namespace std;
int n, m;
struct Node { int ls, rs, si, vl, rd, rv; };
struct Treap
{
int rt, cnt;
Node p[MAXN];
inline void New(int v) { cnt++; p[cnt] = (Node){0, 0, 1, v, rand(), 0}; return; }
inline void Pushdown(int u) { if(p[u].rv) { swap(p[u].ls, p[u].rs); p[p[u].ls].rv ^= 1; p[p[u].rs].rv ^= 1; p[u].rv ^= 1; } return; }
inline void Update(int u) { p[u].si = p[p[u].ls].si + p[p[u].rs].si + 1; return; }
void Split(int u, int k, int &l, int &r)
{
if(!u) return (l = r = 0, void());
Pushdown(u);
if(p[p[u].ls].si < k)
{
l = u;
Split(p[u].rs, k - p[p[u].ls].si - 1, p[u].rs, r);
}
else
{
r = u;
Split(p[u].ls, k, l, p[u].ls);
}
Update(u);
return;
}
int Merge(int l, int r)
{
if(!l || !r) return (l + r);
if(p[l].rd < p[r].rd)
{
Pushdown(l);
p[l].rs = Merge(p[l].rs, r);
Update(l);
return l;
}
else
{
Pushdown(r);
p[r].ls = Merge(l, p[r].ls);
Update(r);
return r;
}
}
void Output(int u)
{
if(!u) return;
Pushdown(u);
Output(p[u].ls);
printf("%d ", p[u].vl);
Output(p[u].rs);
return;
}
} t;
int main()
{
srand((unsigned)(time(NULL)));
scanf("%d%d", &n, &m);
for(int i = 1; i <= n; i++) { t.New(i); t.rt = t.Merge(t.rt, i); }
for(int i = 1, l, r; i <= m; i++)
{
scanf("%d%d", &l, &r);
int a, b, c;
t.Split(t.rt, r, a, b);
t.Split(a, l - 1, a, c);
t.p[c].rv ^= 1;
t.rt = t.Merge(t.Merge(a, c), b);
}
t.Output(t.rt);
return 0;
}
当然 f h q _ T r e a p fhq\_Treap fhq_Treap 也存在一个缺点:会比单旋 T r e a p Treap Treap 稍微慢一些,但是它的小码量是无可替代的
以上两种是比较常见的平衡树,实际上有一种很好理解的平衡树叫替罪羊树,在我的 这篇文章 中有提到
还有一种十分高效的平衡树是红黑树,是 STL 中的内置操作树,不过码量太大,这里就不做介绍
当然还存在更多的平衡树,有兴趣的读者可以自行查找相关资料~
三、树套树
(这里特指线段树套平衡树)
我们来看一个问题:P3380 【模板】二逼平衡树(树套树)
如果把里面的所有区间都变成全局,那么这个题就是平衡树的基本操作
可是怎么处理这个区间呢?
这个时候我们就要用到树套树了
我们考虑建立一颗表示位置的线段树,在线段树的每个节点上再建一颗权值平衡树,表示这个节点所代表区间内所有点的权值
这样,我们在查找区间排名时,就能够先在线段树上找到对应的区间,再在这些区间上挂的平衡树中查询了
那么我们来讲一下这个题目:
首先树套树的建树应该是 O ( n log 2 n ) O(n\log_2n) O(nlog2n)的,在线段树的基础上,合并两颗平衡树会带一个 log \log log 的复杂度
下面分别讲每一个操作:
-
我们先在线段树上找到区间 [ l , r ] [l, r] [l,r],再在每个结点的平衡树上寻找比 k 小的数的个数,最后加上 1 就是答案,复杂度 O ( log 2 2 n ) O(\log_2^2 n) O(log22n)
-
显然我们很难直接找,那么基于第 1 个操作,我们可以二分一个答案,然后再查这个数的排名,复杂度 O ( log 2 3 n ) O(\log_2^3 n) O(log23n)
-
我们再线段树上找出所有包含这个位置的区间,把区间内该位置原来的数删掉之后再插入新数即可,复杂度 O ( log 2 2 n ) O(\log_2^2 n) O(log22n)
-
在线段树上找到区间后,在每颗平衡树上求一个前驱,求最大值即可
-
类似操作四,在线段树上找到区间后,在每颗平衡树上求一个后继,求最小值即可
由于笔者太菜,这道题的代码先咕了,如果哪一天调出来了会补上
好了好了,我不咕了
#include<iostream>
#include<cstdio>
#include<cstdlib>
#include<cctype>
#include<cassert>
#include<vector>
#define MAXN 500005
#define INF 0x7FFFFFFF
#define MOD 998244353
#define up(i, l, r) for(register int i = (l); i <= (r); i = -~i)
#define down(i, l, r) for(register int i = (l); i >= (r); i--)
using namespace std;
namespace IO
{
int f; char c;
template<typename T> inline void _Read(T &v)
{
v = 0; f = 1; c = getchar();
while(!isdigit(c)) { if(c == '-') f = -1; c = getchar(); }
while(isdigit(c)) { v = (v << 3) + (v << 1) + (int)(c - '0'); c = getchar(); }
v *= f;
return;
}
template<typename T> inline void _Write(T k)
{
if(k < 0) { putchar('-'); k = -k; }
if(k > 9) _Write(k / 10);
putchar((char)(k % 10 + '0'));
return;
}
inline int Read() { int v; _Read(v); return v; }
inline void Write(int v, char ed = '\n') { return _Write(v), putchar(ed), void(); }
}
using IO :: Read;
using IO :: Write;
int n, m, a[MAXN];
struct fhq_Treap
{
int cnt, ls[MAXN << 4], rs[MAXN << 4], rd[MAXN << 4], si[MAXN << 4], vl[MAXN << 4];
inline int Newnode(int v) { ++cnt; return ls[cnt] = rs[cnt] = 0, rd[cnt] = 1LL * rand() * rand() % MOD, si[cnt] = 1, vl[cnt] = v, cnt; }
inline void Pushup(int now) { return si[now] = si[ls[now]] + si[rs[now]] + 1, void(); }
inline void Split_Value(int now, int k, int &a, int &b)
{
if(!now) return a = b = 0, void();
if(vl[now] <= k) a = now, Split_Value(rs[now], k, rs[a], b);
else b = now, Split_Value(ls[now], k, a, ls[b]);
return Pushup(now);
}
inline void Split_Rank(int now, int k, int &a, int &b)
{
if(!now) return a = b = 0, void();
if(si[ls[now]] < k) a = now, Split_Rank(rs[now], k - si[ls[now]] - 1, rs[a], b);
else b = now, Split_Rank(ls[now], k, a, ls[b]);
return Pushup(now);
}
inline int Merge(int a, int b)
{
if(!a || !b) return a + b;
if(rd[a] < rd[b]) { rs[a] = Merge(rs[a], b); return Pushup(a), a; }
else { ls[b] = Merge(a, ls[b]); return Pushup(b), b; }
}
inline int Getrank(int now, int k)
{
int res = 0;
while(now)
{
if(vl[now] < k) res += si[ls[now]] + 1, now = rs[now];
else now = ls[now];
}
return res;
}
inline void Insert(int &now, int vl)
{
int L, R; Split_Value(now, vl, L, R);
return now = Merge(Merge(L, Newnode(vl)), R), void();
}
inline void Delete(int &now, int vl)
{
int rk = Getrank(now, vl);
int a, b, c, d;
return Split_Rank(now, rk + 1, a, b), Split_Rank(a, rk, c, d), assert(si[d] == 1), now = Merge(c, b), void();
}
inline int Precursor(int now, int k)
{
int res = -INF;
while(now)
{
if(vl[now] < k) res = max(res, vl[now]), now = rs[now];
else now = ls[now];
}
return res;
}
inline int Successor(int now, int k)
{
int res = INF;
while(now)
{
if(vl[now] > k) res = min(res, vl[now]), now = ls[now];
else now = rs[now];
}
return res;
}
} trp;
struct Segment_Tree
{
#define ls (now << 1)
#define rs (now << 1 | 1)
#define mid ((l + r) >> 1)
int rt[MAXN << 4];
inline void Build(int now, int l, int r)
{
up(i, l, r) trp.Insert(rt[now], a[i]);
if(l == r) return;
return Build(ls, l, mid), Build(rs, mid + 1, r);
}
inline int Query_Range(int now, int l, int r, int L, int R, int k)
{
if(L <= l && r <= R) return trp.Getrank(rt[now], k);
int res = 0;
if(L <= mid) res += Query_Range(ls, l, mid, L, R, k);
if(R > mid) res += Query_Range(rs, mid + 1, r, L, R, k);
return res;
}
inline void Modify(int now, int l, int r, int pos, int k)
{
trp.Delete(rt[now], a[pos]), trp.Insert(rt[now], k);
if(l == r) return;
if(pos <= mid) Modify(ls, l, mid, pos, k);
else Modify(rs, mid + 1, r, pos, k);
return;
}
inline int Query_Precursor(int now, int l, int r, int L, int R, int k)
{
if(L <= l && r <= R) return trp.Precursor(rt[now], k);
int res = -INF;
if(L <= mid) res = max(res, Query_Precursor(ls, l, mid, L, R, k));
if(R > mid) res = max(res, Query_Precursor(rs, mid + 1, r, L, R, k));
return res;
}
inline int Query_Successor(int now, int l, int r, int L, int R, int k)
{
if(L <= l && r <= R) return trp.Successor(rt[now], k);
int res = INF;
if(L <= mid) res = min(res, Query_Successor(ls, l, mid, L, R, k));
if(R > mid) res = min(res, Query_Successor(rs, mid + 1, r, L, R, k));
return res;
}
#undef ls
#undef rs
#undef mid
} st;
int main()
{
srand((unsigned)(time(NULL)));
n = Read(), m = Read();
up(i, 1, n) a[i] = Read();
st.Build(1, 1, n);
while(m--)
{
int op = Read();
if(op == 1)
{
int L = Read(), R = Read(), k = Read();
Write(st.Query_Range(1, 1, n, L, R, k) + 1);
continue;
}
if(op == 2)
{
int L = Read(), R = Read(), k = Read();
int l = 0, r = 1e8, ans = 0;
while(l <= r)
{
int mid = (l + r) >> 1;
int rk = st.Query_Range(1, 1, n, L, R, mid) + 1;
if(rk <= k) ans = mid, l = mid + 1;
if(rk > k) r = mid - 1;
}
Write(ans);
continue;
}
if(op == 3)
{
int pos = Read(), k = Read();
st.Modify(1, 1, n, pos, k);
a[pos] = k;
continue;
}
if(op == 4)
{
int L = Read(), R = Read(), k = Read();
Write(st.Query_Precursor(1, 1, n, L, R, k));
continue;
}
if(op == 5)
{
int L = Read(), R = Read(), k = Read();
Write(st.Query_Successor(1, 1, n, L, R, k));
}
}
return 0;
}

















 309
309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









