





“全网都说 AI 好、牛逼,为什么我用起来,觉得它就是个智障呢?”,为什么有此疑问,也许是你不会表达。
像下面这种提示词,也许你也会问出来。
如何在 Excel 中添加数字?
谁是总统?
总结会议纪要。
然后发现 AI 的回复像个智障心里默默吐槽,AI 大模型也就这样啊,回答的什么玩意。
今天,阿七告诉大家几个通用的提示词框架,大家只要去套框架,输出的质量,绝对有提升。
1、ICIO 框架
ICIO 框架是由 Elavis Saravia 提出并发表,只要包含四个部分:
- 指令 I(Instruction)
- 背景信息 C(context)
- 输入数据 I (input Data)
- 输出引导 O(output indicator)
我们来一个简单的例子,这是一个程序员比较容易理解的提示词案例:
Instruction(任务):
请编写一个 Python 函数,该函数能够接受一个字符串列表作为输入,并返回一个新的列表,其中包含所有字符串长度大于5的元素。
Context(背景):
这个函数将被用于数据清洗过程,我们需要过滤掉那些不符合特定长度要求的字符串,以便后续的文本分析工作。这个函数将被集成到我们的数据分析工具中,因此需要确保它具有良好的性能和稳定性。
Input Data(输入数据):
[“hello”, “world”, “Moonshot”, “AI”, “technology”]
Output Indicator(输出格式):
函数应返回一个新的列表,其中只包含长度大于5的字符串。例如,对于上述输入数据,期望的输出应该是[“Moonshot”, “technology”]。
我们使用这个提示词,直接咨询 kimi,以下是返回:
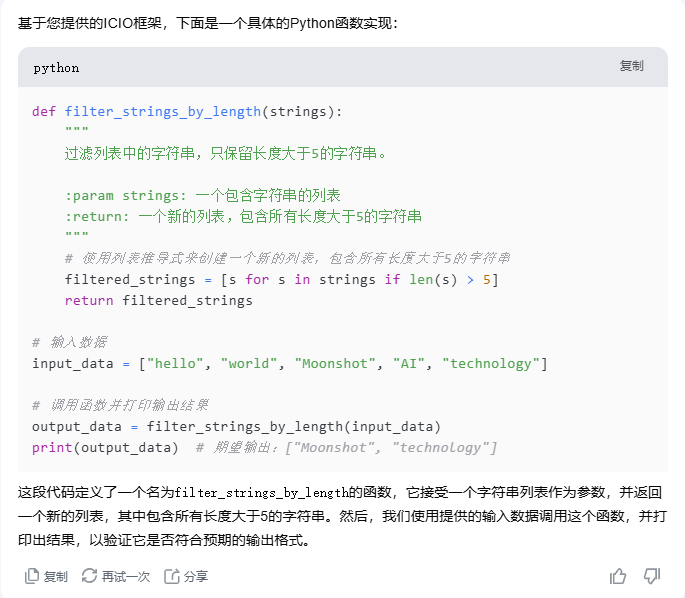
ICIO 框架虽然简单,但是非常实用,大部分场景都能使用这个框架拿到一个非常不错的返回。
2、CRISPE 框架
CRISPE 框架有 Matt Nigh 提出,主要包含五个部分:
- Capacity and Role(角色):告诉AI你要它扮演的角色,比如老师、翻译官等。
- Insight(背景):告诉 AI 你让它扮演这个角色的背景,比如扮演老师是要教自己 10 岁的儿子等。
- Statement(任务):告诉 AI 你要它做什么任务。
- Personality(格式):告诉 AI 用什么风格、方式、格式来回答。
- Experiment(实验):请求 AI 为你回复多个示例(如果不需要,可无)。
来一个程序员工作中常见场景的示例:
Capacity and Role(角色):
你是一位经验丰富的软件开发顾问,专门帮助解决复杂的编程问题。
Insight(背景):
我们正在开发一个电子商务平台,需要处理大量的用户交易数据。我们的目标是优化数据库查询性能,以减少页面加载时间并提高用户体验。
Statement(任务):
请提供一个优化 SQL 查询性能的策略,特别是针对高并发环境下的读操作。
Personality(格式):
请以简洁明了的技术文档格式提供解决方案,包括关键点和代码示例。
Experiment(实验):
如果你能提供多种策略,我们将非常感激,这样我们可以评估不同方法的优劣。
Exception(例外):
请避免使用我们技术栈不支持的数据库特性。
我们来看 kimi 的返回:

还是非常不错的。
3、BROKE 框架
BROKE 框架有陈财猫提出,主要包含五个部分:
- 背景(Background):提供足够的背景信息,使 AI 能够理解问题的上下文。
- 角色定义(Role):设定特定的角色,让 AI 能够根据该角色来生成响应。
- 目标设定(Objectives):明确任务目标,让 AI 清楚知道需要实现什么。
- 关键成果展示(Key Result):定义关键的、可衡量的结果,以便让 AI 知道如何衡量目标的完成情况。
- 持续的试验与优化(Evolve):通过试验和调整来测试结果,并根据需要进行优化。
看到这里我们发现,其实所有的提示词框架都要求你把背景信息补充好,明确任务目标,不要让 AI 来猜你想干嘛,它不是你的男朋友。
我们来看一个具体案例:
背景(Background):我们正在启动一个新项目,目标是在接下来的六个月内开发并上线一个电子商务平台。
角色定义(Role):你是一位经验丰富的项目经理,负责规划项目的关键里程碑和任务分配。
目标设定(Objectives):制定一个详细的项目计划,包括项目启动、开发、测试和上线各个阶段的时间表和关键任务。
关键成果展示(Key Result):项目计划应包含每个阶段的开始和结束日期,以及每个任务的具体负责人和预期成果。
持续的试验与优化(Evolve):在项目执行过程中,根据实际情况调整项目计划,并在每个阶段结束时评估项目进度,以确保项目按时完成。



我们能看到通过这种框架,AI 的答复会非常有结构。
4、CO-STAR 框架
CO-STAR 框架是新加坡政府科技局的数据科学与 AI 团队开发的一种提示词构建工具。
提示词女王 Sheila Teo 通过这个提示词框架,获得了 GPT-4 提示词大赛的冠军。
这个框架包含六个部分:
- (C)上下文(context):提供于任务有关的背景信息,越详细越好。这可以帮助大模型理解正在讨论的问题,问题背景,理解具体场景,确保大模型的回复是相关性强的回复。
- (O)目标(Objective):定义你希望大模型完成的任务,这可以帮助大模型明确响应目标。
- (S)风格(Style):希望回复的风格,可以减少「AI 味」,同时也可以指定风格为自己的写作风格。
- (T)语气(Tone):设定响应的态度。确保大模型的响应符合特定的情感或情绪。
- (A)受众(Audience):明确响应目标的受众。做到有的放矢,不响应目标受众无法理解的内容。
- (R)响应(Response):提供响应的格式、内容结构。格式上:我们可以要求大模型以 Json 格式进行输出,方面程序对其响应进行处理。内容结构上:我们可以要求大模型以常见的行文结构进行输出,比如金字塔结构、列表结构等。
我们来看一个案例:
Context(上下文):
你是一位经验丰富的软件工程师,目前正参与一个敏捷开发项目,该项目旨在为一家金融科技公司开发一个风险评估工具。这个工具需要集成到现有的系统中,并与多个数据源交互,以实时计算风险评分。
Objective(目标):
编写一个函数,该函数能够从多个数据源中提取数据,并计算出一个综合的风险评分。这个函数需要能够处理异常情况,并确保数据的一致性和准确性。
Style(风格):
请以清晰、简洁的技术文档风格提供解决方案,包括伪代码或实际代码示例,以及必要的注释。
Tone(语调):
保持专业和事实性的语调,确保内容适合技术团队内部交流。
Audience(受众):
这个函数将由项目团队中的其他开发人员使用,他们具有不同的技术背景,因此需要确保代码易于理解和维护。
Response(回应):
请提供一个完整的函数实现,包括输入参数、处理逻辑和返回值。如果可能,请提供单元测试用例,以验证函数的正确性。


5、总结
虽然上面说的框架,看起来高大上,其实目的就是为了把事情、任务说明白。
和日常工作、生活一样,如果和你沟通的人是你的隔级领导,对你日常工作并不清楚,当你想向他咨询一个问题的时候,你应该介绍事情的前因后果和需要他解决的具体问题。
讲让没有背景知识的人也能听明白的话,他才能进行有效的回复。


















 1944
1944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











