




 本文通过实验探讨了Unity中动态批处理的特性及其版本间的差异。重点介绍了在不同物体缩放情况下批处理的表现,并对比了4.0版本与5.0版本之间的改进。
本文通过实验探讨了Unity中动态批处理的特性及其版本间的差异。重点介绍了在不同物体缩放情况下批处理的表现,并对比了4.0版本与5.0版本之间的改进。
尊重原创:https://blog.youkuaiyun.com/a2587539515/article/details/51178308
转自大佬见笑
网上看了几篇文章,觉得不如自己试试,果然发现了一些问题,又查了查官网,才知道版本更新的时候批处理也更新了。
新版本官网上的介绍中去掉了缩放的限制,增加了一条对于镜像物体无法进行批处理,比如Scale为(1,1,1)的物体与Scale为(-1,1,1)的物体无法进行批处理。而限制(1,1,1)与(1,2,3)可以进行批处理。
以下,实验过程,眼见为实嘛。
先看第一种情况。
1、创建几个物体大小相同时。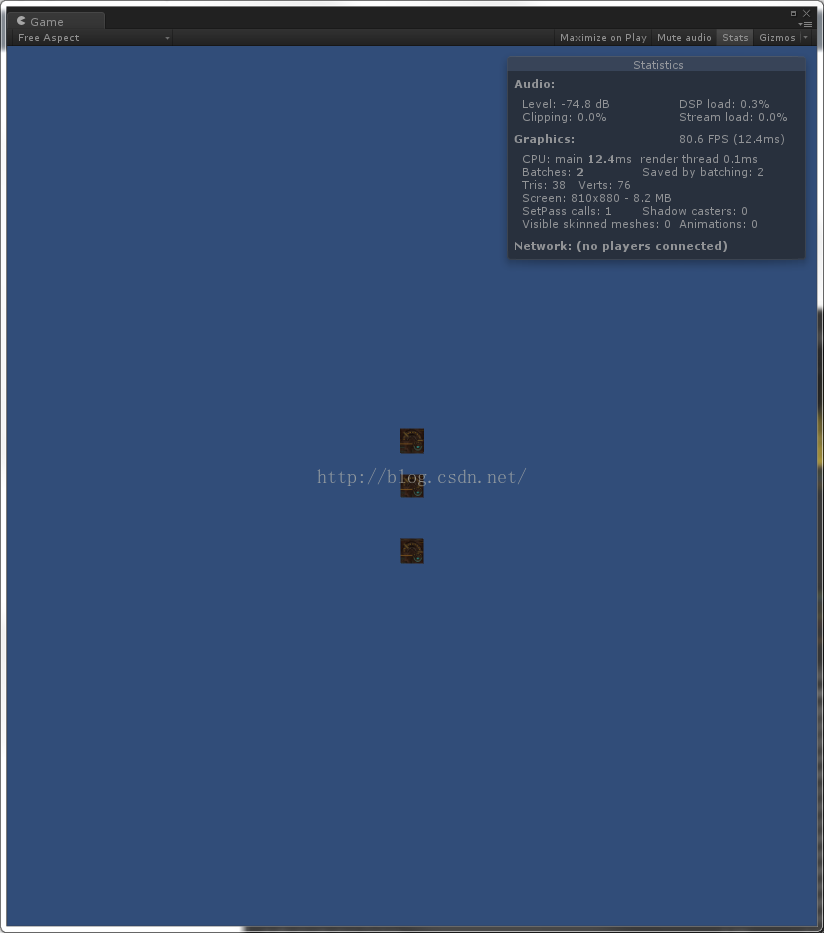
可以看出,3个物体,Save By Batching是2,说明有两个物体进行了一次批处理,SetPass Call是1,说明只有一个DrawCall,这是对的。在这个例子中,我是直接在场景中创建的物体。
2、创建几个物体大小不同时
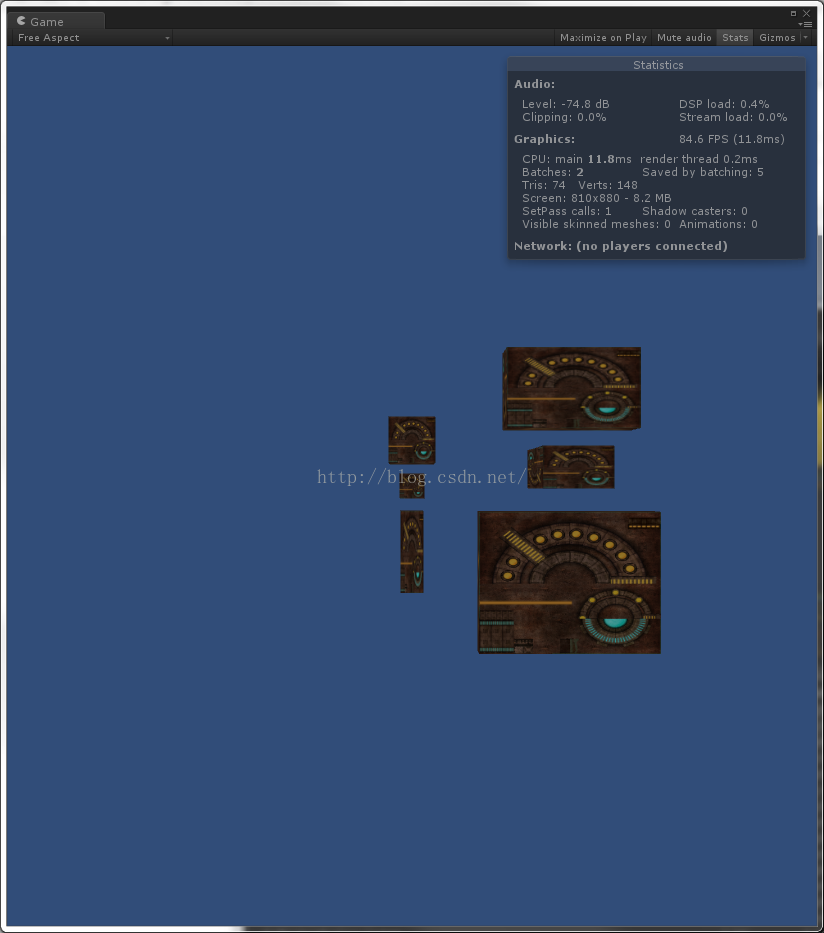
多加了几个物体,Save By Batching是5,SetPass Call是1,就是说我们仍然做了批处理,DrawCall还是1。
网上有4.0版本的Dynamic Batching介绍,效果不一样这是,这是5.0版本对动态批处理进行的升级。
3、动态创建物体

等大的物体创建就不说了,仍然DrawCall是1。
看第一句,这是个等比例放大。

结果没有变。
第二句再来个非等比例放大。
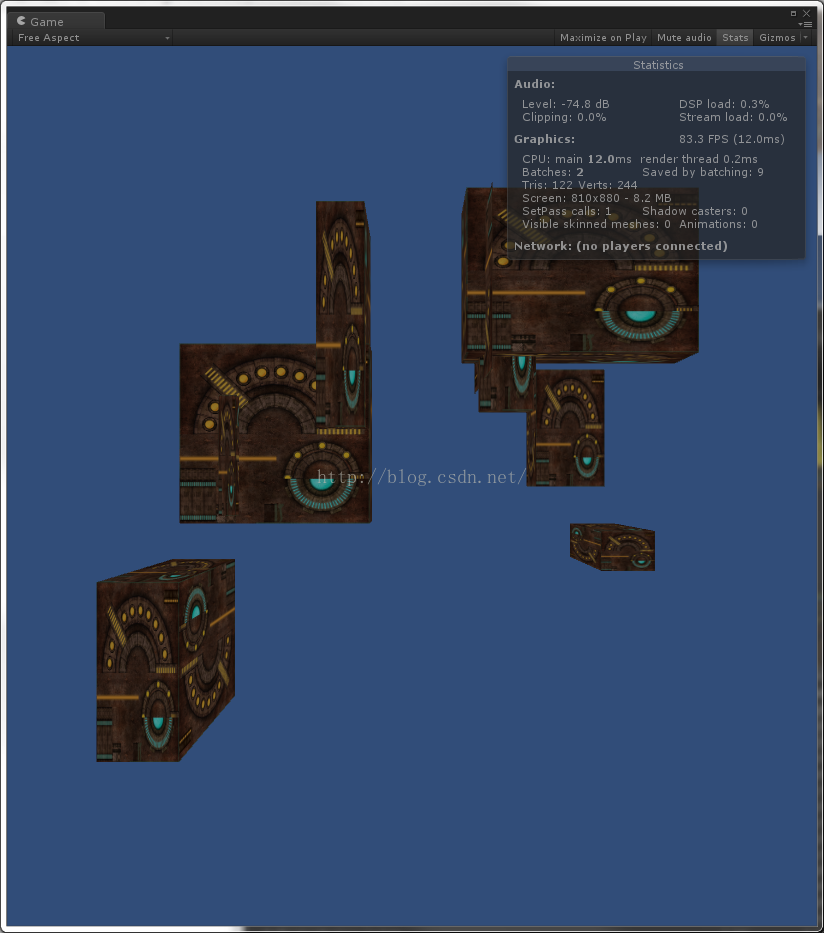
结果没有变,最后来个最有意思的,第三句。
obj.transform.localScale = new Vector3((Random.value - 0.5f) * 2 * range, Random.value * range, Random.value * range);
这里仍然是非等比例放大,然而我将x的值改为-1~1之间。我们来看下效果。

因为这里我用的是随机,所以值会出现很多种,但是可以看出Save By Call发生了变化。同时DrawCall也发生了变化。

















 333
333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









