



就在昨晚,智谱开源了GLM-4.6V 模型。
128k 超长上下文(约等于150 页文档)
最大的亮点:原生支持视觉工具调用(Function Call)
不仅能看,还能动手干活
两个版本,丰俭由人:
• GLM-4.6V(106B-A12B):这是满血版,性能强悍,对标云端业务,支持高性能集群
• GLM-4.6V-Flash(9B):这是轻量版,跑得快,适合本地部署
价格方面:
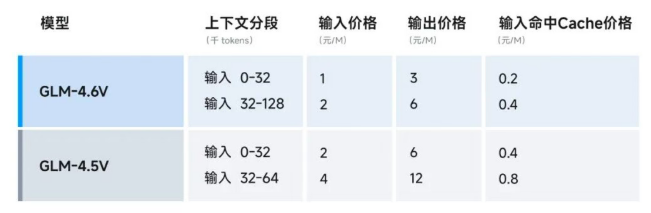
image.png
相比上一代,直接降价 50%
输入:1 元 / 百万 token
输出:3 元 / 百万 token
Flash 版本:免费
以及,这次更新,唯一的重点
GLM-4.6V,打通了“视觉”和“工具”
以前的多模态模型是:我看图 -> 转成文字 -> 调工具 -> 给你结果。中间转来转去,信息全丢了。
GLM-4.6V 是原生的:图像即参数,结果即上下文
直接把图扔给工具,工具返回的图表、网页,模型也能直接看懂
从“看懂”到“执行”,一条龙搞定
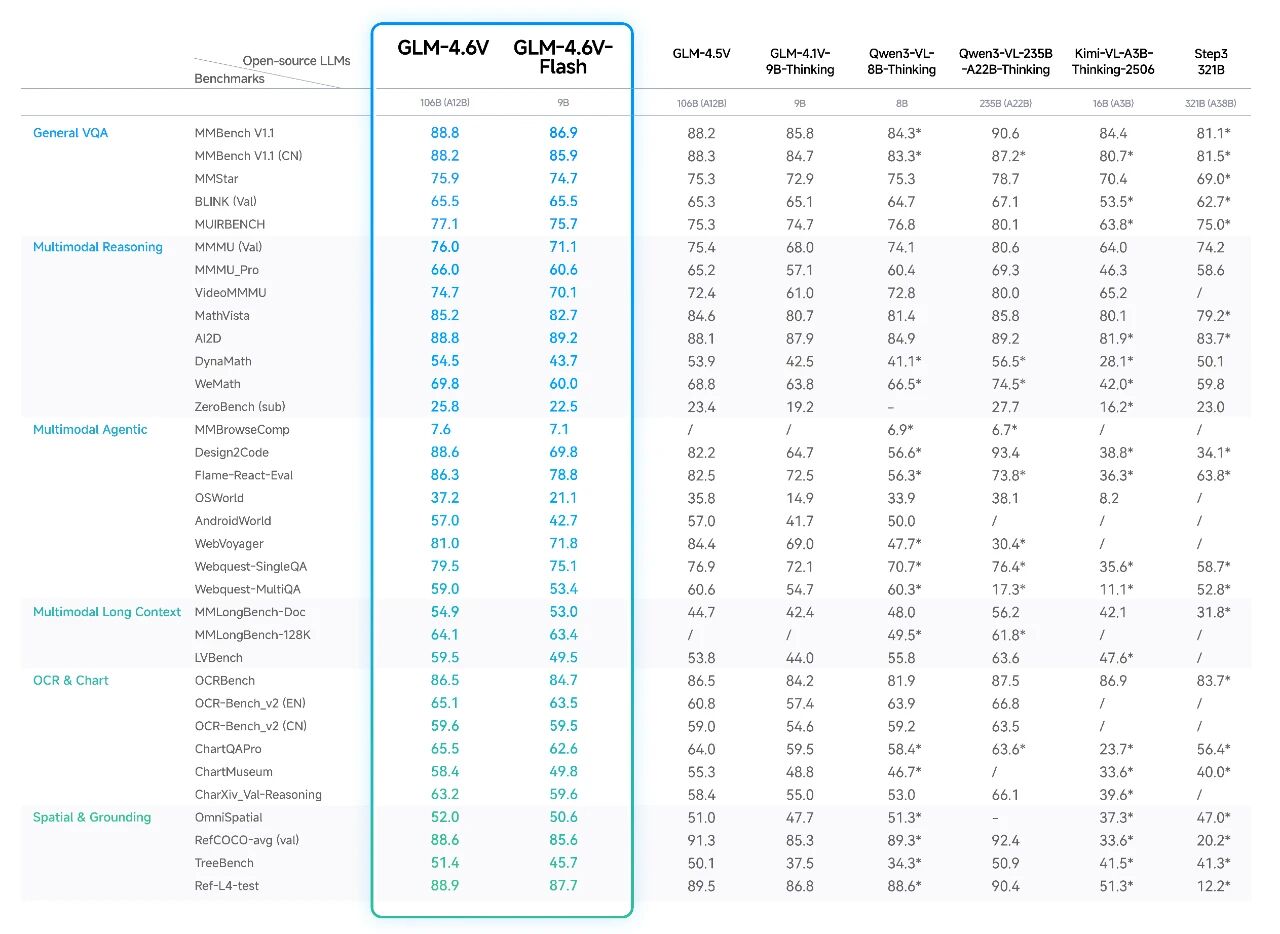
评测数据,简单总结就是“以小博大”
7ad5306a4ee92d3735d5cb0b4ecc4fdf.jpg
在 MMBench、MathVista 等 30+ 评测基准上验证:
• 9B Flash 版本:整体干翻 Qwen3-VL-8B
• 106B 版本:跟参数量是它 2 倍的 Qwen3-VL-235B 打得有来有回
官方场景案例:
1. 图文混排神器:内容创作的福音
扔给它一个主题,或者一篇干巴巴的论文、研报
它不是简单的配图,而是真正理解了内容
模型能自己调搜索工具找图,还自带“审美”做视觉审核
最后采用“草稿 -> 选图 -> 润色”的流程,吐出一篇结构清晰、图文并茂的公众号文章或 PPT 素材
2. 识图购物 Agent:比你更懂全网低价
你在街上拍个好看的衣服,模型直接识别你的“剁手”意图
自动规划任务,调起 image_search 工具
它能处理京东、拼多多等不同平台的脏数据,自动清洗、对齐
最后甩给你一张带购买链接、价格对比和缩略图的 Excel 表格
3. 前端复刻:程序员狂喜
直接上传一张设计稿或者网页截图,模型直接生成 HTML/CSS/JS 代码
它支持“视觉交互调试”
你可以在生成的图上圈一下,说:“把这个按钮左移一点,换成深蓝色”
模型利用视觉反馈循环,自动定位代码并修正,像素级还原
4. 财报/长视频分析:过目不忘
128k 上下文不是摆设,大概能塞进 150 页文档或 1 小时视频
一次扔进去 4 家上市公司的财报,它能跨文档提取核心指标,生成对比表
或者扔进一场足球比赛录像,它能精准定位进球时刻,生成集锦时间轴,关键信息一个不漏
这次智谱很敞亮,权重、代码全放出来了。
支持 vLLM、SGLang、Transformers 等主流框架,国产卡(NPU)也支持
GitHub👉https://github.com/zai-org/GLM-V
Hugging Face👉https://huggingface.co/collections/zai-org/glm-46v
魔搭 ModelScope👉https://modelscope.cn/collections/GLM-46V
在线体验👉z.ai (选 GLM-4.6V)或者智谱清言 APP
如果你也对AI感兴趣,想拥抱AI,不妨可以来看看我们的AI超级个体知识库👇 免费的!

AI超级个体知识库
https://hyperspace.feishu.cn/wiki/SpRGwQNKMiYk8UkzInBcQkzZnLh


















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









