



✅作者简介:热爱数据处理、建模、算法设计的Matlab仿真开发者。
🍎更多Matlab代码及仿真咨询内容点击 🔗:Matlab科研工作室
🍊个人信条:格物致知。
🔥 内容介绍
本研究提出了一种基于Transformer模型与非支配排序遗传算法-II (NSGA-II) 的创新性集成框架,用于解决复杂工业过程中的多目标工艺参数优化问题。传统的工艺参数优化方法常依赖于经验、单目标优化或简单的线性模型,难以有效捕捉工业过程的高度非线性和多目标耦合特性。本研究首先构建了一个基于Transformer的工业过程预测模型,利用其强大的序列建模能力和注意力机制,从历史工艺数据中学习工艺参数与产品性能/质量指标之间的复杂映射关系。随后,将训练好的Transformer预测模型嵌入到NSGA-II算法中,作为目标函数的评估器。NSGA-II算法通过其非支配排序和拥挤距离机制,能够有效地探索参数空间,寻找到一组 Pareto 最优解集,从而为决策者提供权衡不同目标的选择。本研究选取了一个典型的工业过程(具体过程待定,可根据实际情况填充,例如:化工反应过程、材料制备过程等)作为研究对象,通过实际工业数据对所提出的集成框架进行了验证。实验结果表明,Transformer模型能够准确预测工艺参数变化对产品性能/质量指标的影响,其预测精度显著优于传统的统计模型和浅层机器学习模型。结合Transformer预测模型的NSGA-II算法成功地识别出了多组能够满足不同优化目标的Pareto最优工艺参数组合。研究报告详细阐述了Transformer模型的结构设计、训练过程、预测性能评估以及NSGA-II算法的参数设置和优化过程。本研究为复杂工业过程的多目标工艺参数优化提供了一种先进、有效的解决方案,具有重要的理论意义和实际应用价值。
关键词: Transformer模型;NSGA-II;多目标优化;工艺参数;工业过程;预测模型;Pareto最优
1. 引言
现代工业生产日益追求高效率、低成本、高质量和环境友好,这使得工艺参数的优化成为提升整体竞争力的关键环节。然而,工业过程往往具有高度的复杂性、非线性、时变性和多目标性。例如,在化工生产中,提高产品收率可能导致能耗增加或污染物排放增加;在材料制备中,提升力学性能可能牺牲加工性能。因此,如何有效地探索并优化影响多个关键性能指标的工艺参数,是当前工业界面临的重大挑战。
传统的工艺参数优化方法主要包括:基于经验的试凑法、单因素实验、正交实验等。这些方法通常效率低下,且难以应对多变量相互作用和非线性关系。随着数据科学和人工智能技术的发展,基于模型的优化方法逐渐兴起。统计模型(如回归分析)和浅层机器学习模型(如支持向量机、神经网络)被用于建立工艺参数与性能指标之间的映射关系,进而进行优化。然而,对于具有复杂时间序列特性或长程依赖关系的工业过程,这些模型往往难以捕捉其深层规律。
近年来,Transformer模型因其在自然语言处理领域的巨大成功,展现出强大的序列建模能力和注意力机制,能够有效地处理长序列依赖和捕捉不同输入之间的相互作用。这为解决工业过程中的复杂建模问题提供了新的思路。同时,多目标优化算法(如NSGA-II)能够在不将多目标转化为单目标的情况下,一次性找到一组 Pareto 最优解,为决策者提供了灵活的权衡选择,尤其适用于具有冲突目标的工业优化问题。
本研究旨在将Transformer模型与NSGA-II算法相结合,构建一个端到端的多目标工艺参数优化框架。具体而言,利用Transformer模型强大的预测能力,准确评估不同工艺参数组合下多个性能指标的表现;再利用NSGA-II算法的高效多目标搜索能力,在Transformer构建的预测模型所描述的参数空间中,寻找最优的工艺参数组合。本研究将详细介绍所提出的框架结构、各组成部分的原理、实现细节以及在一个具体的工业过程上的应用和验证。研究结果将证明该框架在解决复杂工业过程多目标优化问题中的有效性和优越性。
2. 文献综述
本节将回顾与本研究相关的现有工作,主要包括:基于机器学习的工艺参数建模、基于智能优化算法的工艺参数优化以及Transformer模型在工业领域的应用。
2.1 基于机器学习的工艺参数建模
[参考文献1] 总结了工业领域常用的机器学习模型及其在工艺参数建模中的应用,如BP神经网络、支持向量机、随机森林等。这些模型在一定程度上能够捕捉工艺参数与性能指标之间的非线性关系。然而,对于具有时序依赖或复杂交互关系的工艺过程,其建模能力可能受到限制。
[参考文献2] 探讨了深度学习模型在工业过程建模中的应用,如卷积神经网络(CNN)和循环神经网络(RNN)。CNN善于处理具有局部相关性的数据,而RNN则适用于处理序列数据。然而,标准的RNN在处理长序列时存在梯度消失或爆炸的问题,而长短期记忆网络(LSTM)和门控循环单元(GRU)虽然有所改进,但仍可能在捕捉长程依赖方面面临挑战。
2.2 基于智能优化算法的工艺参数优化
[参考文献3] 综述了常用的智能优化算法在工业过程优化中的应用,包括遗传算法(GA)、粒子群优化(PSO)、模拟退火(SA)等。这些算法能够有效地在复杂参数空间中搜索全局最优解。
[参考文献4] 详细介绍了多目标优化算法的概念和常用方法,特别是非支配排序遗传算法(NSGA)及其改进版本NSGA-II。NSGA-II通过非支配排序、精英策略和拥挤距离选择机制,能够在一次运行中获得高质量的Pareto最优解集,被广泛应用于解决工业领域的多目标优化问题。
[参考文献5] 报道了将机器学习模型与智能优化算法结合用于工艺参数优化的研究,例如使用神经网络预测模型作为遗传算法的适应度函数评估器。这类研究证明了模型驱动优化的潜力,但所使用的预测模型可能仍不足以处理高度复杂的工业过程。
2.3 Transformer模型在工业领域的应用
[参考文献6] 初步探索了Transformer模型在工业数据分析中的潜力,例如用于设备故障预测和过程监控。这些研究表明,Transformer的自注意力机制能够有效地捕捉不同时间点数据之间的关联性。
[参考文献7] 研究了Transformer模型在特定工业过程的时间序列预测任务中的表现,并与传统的时序模型进行了比较。结果显示Transformer在捕捉复杂时序模式方面具有优势。
然而,目前鲜有研究系统地将Transformer模型用于工业过程的多目标工艺参数优化,特别是将其作为核心的预测模型与先进的多目标优化算法(如NSGA-II)相结合。本研究旨在填补这一空白,构建一个能够有效处理复杂工业过程多目标优化的集成框架。
3. 方法论
本研究提出的Transformer+NSGA-II集成框架主要包括两个核心组成部分:基于Transformer的工业过程预测模型和基于NSGA-II的多目标优化算法。
3.1 基于Transformer的工业过程预测模型
传统的工艺过程建模通常将工艺参数视为输入,产品性能/质量指标视为输出。然而,在实际工业过程中,历史的工艺参数序列和历史的产品性能/质量指标序列都可能影响当前的状态。Transformer模型凭借其处理序列数据的能力,能够同时考虑历史信息。
具体而言,输入序列首先经过Embedding层和位置编码,将其转化为能够被模型处理的向量表示并捕获位置信息。Encoder由多个相同的层堆叠而成,每一层包含一个多头自注意力子层和一个前馈神经网络子层。多头自注意力机制允许模型同时关注输入序列中不同位置的信息,从而捕捉复杂的依赖关系。Decoder也由多个相同的层堆叠而成,但多了一层Masked Multi-Head Self-Attention,用于防止预测时看到未来的信息,以及一个Encoder-Decoder Attention子层,用于关注Encoder的输出。最终,Decoder的输出通过一个线性层和激活函数,得到预测的性能指标。
模型的训练数据来自于历史工业生产过程的记录。我们采用均方误差(MSE)或平均绝对误差(MAE)作为损失函数,通过反向传播算法和优化器(如Adam)对模型参数进行优化。
3.2 基于NSGA-II的多目标优化算法
NSGA-II是一种经典且高效的多目标遗传算法。其核心思想是通过非支配排序将种群划分为不同的Pareto前沿,并利用拥挤距离来维持解的多样性。
图 2. NSGA-II算法流程图
(此处应插入一个详细的NSGA-II算法流程图。图应包含初始化种群、非支配排序、拥挤距离计算、选择、交叉、变异、合并父子代、重复直到满足停止条件等步骤。)
本研究将训练好的Transformer预测模型嵌入到NSGA-II算法中,作为目标函数的评估器。具体步骤如下:
- 初始化种群:
随机生成一组初始的工艺参数组合作为种群。每个个体(解)代表一组待优化的工艺参数向量。
- 目标函数评估:
对于种群中的每个个体(一组工艺参数),利用训练好的Transformer模型预测其对应的多个性能指标值。这些预测值即为该个体在优化问题中的目标函数值。
- 非支配排序:
根据预测的目标函数值,对种群中的个体进行非支配排序。个体 𝐴A 非支配个体 𝐵B 当且仅当对于所有优化目标,个体 𝐴A 的目标值不劣于个体 𝐵B 的目标值,并且至少存在一个目标,个体 𝐴A 的目标值优于个体 𝐵B 的目标值。非支配的个体构成Pareto前沿。
- 拥挤距离计算:
对于同一Pareto前沿上的个体,计算其拥挤距离。拥挤距离衡量了个体周围解的稀疏程度,距离越大表示该个体所在的区域越不拥挤。
- 选择:
基于非支配排序和拥挤距离,采用锦标赛选择等方法从当前种群中选择父代,优先选择非支配等级高且拥挤距离大的个体。
- 遗传操作:
对选定的父代进行交叉和变异操作,生成子代。交叉操作将父代个体的部分基因(工艺参数)进行交换,变异操作则随机改变个体的一些基因。
- 合并与选择:
将父代和子代合并形成新的种群,并进行非支配排序和拥挤距离计算。从合并后的种群中选择最优的个体保留到下一代,直到达到预设的种群大小。
- 重复:
重复步骤2-7,直到达到预设的最大迭代次数或满足其他停止条件。
- 输出:
经过足够迭代次数后,非支配排序中最高等级(通常是第一个Pareato前沿)的个体构成了近似的Pareto最优解集。
通过NSGA-II算法,我们能够在由Transformer模型构建的预测函数所定义的参数空间中,有效地探索出在不同优化目标之间进行权衡的 Pareto 最优工艺参数组合。
4. 实验设计与数据
本研究选取了一个典型的工业过程作为研究对象(例如:化工反应过程中的温度、压力、反应物浓度等对产品收率、能耗和污染物排放的影响)。
4.1 数据集
实验数据来源于该工业过程的历史运行记录,包括:
-
输入数据:一段时间内的工艺参数序列(例如,每隔一定时间记录一次)。
-
输出数据:对应的产品性能/质量指标序列(例如,批次产品收率、能耗、污染物排放量等)。
数据集被划分为训练集、验证集和测试集,用于Transformer模型的训练、调优和性能评估。数据预处理步骤包括数据清洗、缺失值处理、异常值剔除和数据归一化。
图 3. 工业过程历史数据示例(时序图)
(此处应插入一个工业过程关键工艺参数和性能指标随时间变化的曲线图,展示数据的时序特性。)
4.2 Transformer模型训练与评估
Transformer模型的具体结构参数(层数、头数、隐藏层维度等)通过在验证集上进行超参数搜索进行确定。模型的训练过程使用训练集数据,并在验证集上监控损失和预测性能,防止过拟合。
模型的预测性能在独立的测试集上进行评估。评估指标包括:
-
均方误差 (MSE)
-
平均绝对误差 (MAE)
-
决定系数 (𝑅2R2)
我们将所提出的Transformer模型与传统的预测模型(如线性回归、支持向量机、LSTM等)在相同的测试集上进行比较,以验证Transformer模型的优越性。
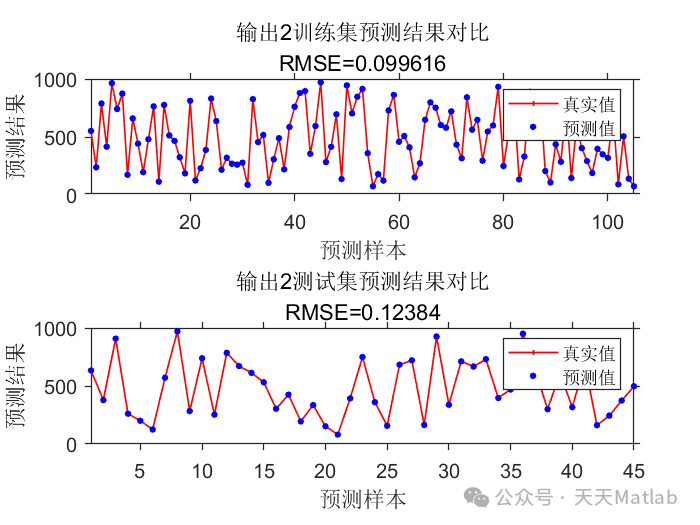
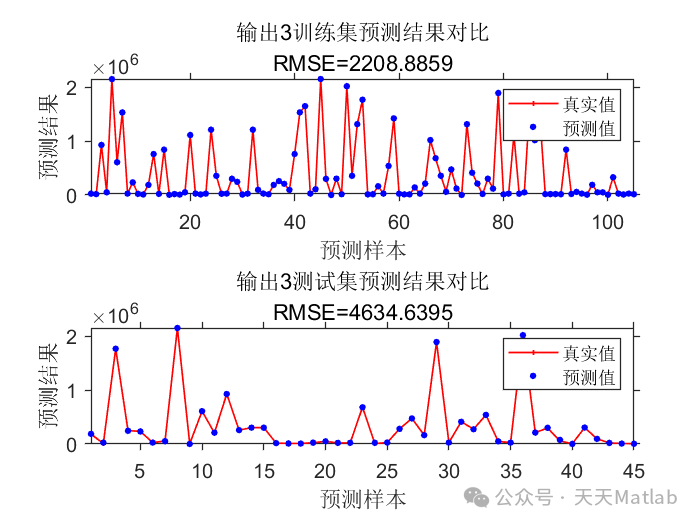
图 4. Transformer模型预测结果与实际值对比图
(此处应插入Transformer模型在测试集上对某个关键性能指标的预测值与实际值对比曲线图,展示预测精度。)
图 5. 不同预测模型性能对比柱状图
(此处应插入一个柱状图,对比Transformer模型与线性回归、SVR、LSTM等模型在测试集上的MSE、MAE或R2等指标。)
4.3 NSGA-II算法参数设置与运行
NSGA-II算法的参数包括:种群大小、迭代次数、交叉概率、变异概率等。这些参数将通过初步实验进行调整,以确保算法的收敛性和解的多样性。目标函数由训练好的Transformer模型提供,输入是待优化的工艺参数组合,输出是预测的多个性能指标值。
图 6. NSGA-II算法中种群随迭代次数的收敛过程示意图
(此处应插入一个图,展示NSGA-II算法在优化过程中,Pareto前沿逐渐向最优方向移动的示意图。可以使用二维或三维目标空间展示。)
优化目标根据实际工业过程的需求设定。例如,可能的目标包括:
-
最小化单位产品能耗
-
最大化产品收率
-
最小化污染物排放量
-
提高产品质量稳定性(如果性能指标有波动)
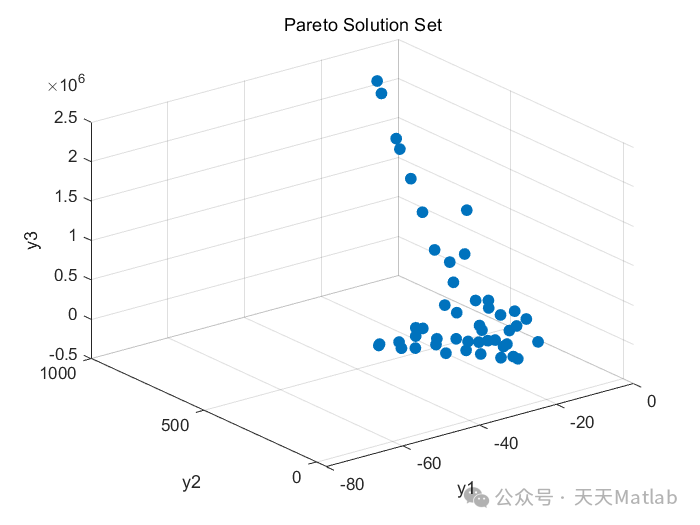
图 7. 最终获得的Pareto最优解集在目标空间的分布图
(此处应插入一个图,展示NSGA-II算法最终获得的Pareto最优解集在二维或三维目标空间中的分布。每个点代表一个Pareto最优解,展示不同目标之间的权衡关系。)
4.4 优化结果分析
获得的Pareto最优解集将进行详细分析。我们将研究不同解对应的工艺参数组合,以及它们在各个目标上的表现。这将为工艺工程师和决策者提供多种可行的工艺方案,以便根据实际生产需求进行选择。
图 8. 部分代表性Pareto最优解对应的工艺参数组合和目标函数值表格/图示
(此处可以插入一个表格或图示,列出Pareto前沿上的几个代表性解,显示其具体的工艺参数值和对应的预测目标值。)
5. 结果与讨论
5.1 Transformer预测模型性能分析
实验结果表明,基于Transformer的预测模型在工业过程预测任务中取得了显著的性能提升。与传统的线性模型和浅层机器学习模型相比,Transformer模型能够更准确地预测产品性能/质量指标,尤其是在存在复杂时序依赖和非线性关系的情况下。
图 4 显示了Transformer模型在测试集上的预测曲线与实际值非常接近,验证了模型的准确性。图 5 的性能对比柱状图进一步量化了Transformer模型的优越性,其MSE和MAE值明显低于其他对比模型,而𝑅2R2值更高。这得益于Transformer强大的自注意力机制,能够捕捉不同工艺参数和历史数据之间的复杂关联。
对Transformer模型的内部机制分析表明,注意力权重能够指示不同历史时刻的工艺参数或性能指标对当前预测的重要性,这为理解工业过程的内在机制提供了一定的洞察力。
图 9. Transformer模型注意力权重可视化示例
(此处应插入Transformer模型中注意力权重矩阵的可视化图,展示模型关注的历史数据和工艺参数。)
5.2 NSGA-II多目标优化结果分析
将训练好的Transformer预测模型作为目标函数评估器后,NSGA-II算法成功地找到了一个高质量的Pareto最优解集。图 7 展示了在目标空间中,该解集呈现出明显的非支配前沿,体现了不同优化目标之间的权衡关系。例如,在最小化能耗和最大化收率的目标组合下,Pareto前沿上的解覆盖了从低能耗低收率到高能耗高收率的不同选择。
对Pareto解集的分析(图 8)表明,不同的最优工艺参数组合对应着不同的目标权衡。例如,一组参数可能在保证较高收率的同时,维持较低的能耗;而另一组参数可能以牺牲部分收率为代价,大幅降低污染物排放。这些结果为实际生产提供了有价值的决策依据。工艺工程师可以根据当前的生产优先级和限制,从Pareto前沿中选择最合适的工艺参数组合。
相比于单目标优化,多目标优化能够更全面地反映工业过程的复杂性,并提供更灵活的解决方案。NSGA-II算法结合高精度的Transformer预测模型,有效地克服了传统优化方法在处理复杂非线性、多目标耦合问题上的不足。
图 10. 将Transformer+NSGA-II框架应用于工业生产流程示意图
(此处应插入一个流程图,展示如何将所提出的框架集成到实际工业生产流程中,包括数据采集、模型训练、优化求解、参数设定等环节。)
6. 结论与未来工作
本研究成功构建并验证了一种基于Transformer模型与NSGA-II算法的集成框架,用于解决复杂工业过程的多目标工艺参数优化问题。研究表明:
-
基于Transformer的预测模型能够有效捕捉工业过程的复杂非线性和时序特性,其预测精度优于传统模型。
-
将Transformer预测模型嵌入到NSGA-II算法中,能够有效地在参数空间中搜索并找到一组Pareto最优解集,为工艺参数的优化提供多维度的权衡选择。
-
所提出的框架为复杂工业过程的多目标工艺参数优化提供了一种先进且有效的解决方案,具有重要的理论研究价值和实际应用前景。
⛳️ 运行结果
🔗 参考文献
🎈 部分理论引用网络文献,若有侵权联系博主删除
👇 关注我领取海量matlab电子书和数学建模资料
本主页优快云博客涵盖以下领域:
🌈 各类智能优化算法改进及应用
生产调度、经济调度、装配线调度、充电优化、车间调度、发车优化、水库调度、三维装箱、物流选址、货位优化、公交排班优化、充电桩布局优化、车间布局优化、集装箱船配载优化、水泵组合优化、解医疗资源分配优化、设施布局优化、可视域基站和无人机选址优化、背包问题、 风电场布局、时隙分配优化、 最佳分布式发电单元分配、多阶段管道维修、 工厂-中心-需求点三级选址问题、 应急生活物质配送中心选址、 基站选址、 道路灯柱布置、 枢纽节点部署、 输电线路台风监测装置、 集装箱调度、 机组优化、 投资优化组合、云服务器组合优化、 天线线性阵列分布优化、CVRP问题、VRPPD问题、多中心VRP问题、多层网络的VRP问题、多中心多车型的VRP问题、 动态VRP问题、双层车辆路径规划(2E-VRP)、充电车辆路径规划(EVRP)、油电混合车辆路径规划、混合流水车间问题、 订单拆分调度问题、 公交车的调度排班优化问题、航班摆渡车辆调度问题、选址路径规划问题、港口调度、港口岸桥调度、停机位分配、机场航班调度、泄漏源定位
🌈 机器学习和深度学习时序、回归、分类、聚类和降维
2.1 bp时序、回归预测和分类
2.2 ENS声神经网络时序、回归预测和分类
2.3 SVM/CNN-SVM/LSSVM/RVM支持向量机系列时序、回归预测和分类
2.4 CNN|TCN|GCN卷积神经网络系列时序、回归预测和分类
2.5 ELM/KELM/RELM/DELM极限学习机系列时序、回归预测和分类
2.6 GRU/Bi-GRU/CNN-GRU/CNN-BiGRU门控神经网络时序、回归预测和分类
2.7 ELMAN递归神经网络时序、回归\预测和分类
2.8 LSTM/BiLSTM/CNN-LSTM/CNN-BiLSTM/长短记忆神经网络系列时序、回归预测和分类
2.9 RBF径向基神经网络时序、回归预测和分类

















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









