







经过四、步骤的一系列操作(点击跳转软件如何操作~过程非常硬核)
我们获取了包含有河流样本的与真实DOM相同大小的标签图片

但是我们的训练样本是要与真实图片放在一起进行训练的
如下图

那么我得把DOM图片从文件夹里筛选出来
由于当时我是通过arcgis软件把包含有河流样本的方格筛选出来的
而图片无法通过这个过程进行筛选
最好是通过代码来进行
幸好当时改图片名字就是考虑到了这个问题
接下来就是要挑选出与标签具有相同名称的DOM图片了
Python批量复制指定文件名称的文件到目标文件夹
这部分参考这位博主的原文
真真的很有用
这里做一下简单记录
代码贴在下面了
# -*- coding: utf-8 -*-
"""
Created on Fri May 13 15:18:50 2022
@author:Laney_Midory
csdn:Laney_Midory
"""
import os
import shutil
filePath = r"C:\Users\Administrator\Desktop\water_train" # 用于获取文件名称列表
old_path = r"D:\toWuda\DOM\CGdom-114(CK0-17)0.1m" # 源文件夹
new_path = r"C:\Users\Administrator\Desktop\DOM" # 目标文件夹
file_list = os.listdir(filePath)
# print(file_list)
old_list = os.listdir(old_path)
for file in old_list:
if os.path.isfile(filePath+'\\'+file):
for i in range(len(file_list)):
if file_list[i] in old_list:
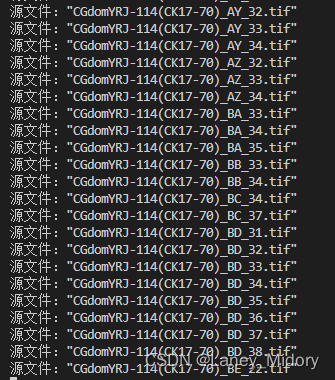
print('源文件:"'+file_list[i]+'",绝对路径:'+old_path+'\\'+file_list[i])
print('目标文件夹:'+new_path+'\\'+file_list[i])
shutil.copy(old_path+'\\'+file,new_path+'\\'+file)
print("复制完成")
但总是报错

于是我认真看了一下代码
发现代码出现了多余的部分才导致这个问题
我的情况是一个文件夹是需要获取的文件名称
一个文件夹是源文件夹
一个文件夹是需要移动到的目标文件夹
那么其实不需要写的那么复杂
我修改后果然就不会出现上述的问题了
同时我发现copy的速度较慢
move的速度快点
要是可以的话可以改成shutil.move
完美适合我的情况
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri May 13 16:56:50 2022
@author:Laney_Midorycsdn:Laney_Midory"""
import os
import shutil
filePath = r"C:\Users\Administrator\Desktop\water_train" # 用于获取文件名称列表
old_path = r"C:\Users\Administrator\Desktop\pic" # 源文件夹
new_path = r"C:\Users\Administrator\Desktop\DOM" # 目标文件夹
file_list = os.listdir(filePath)
# print(file_list)
old_list = os.listdir(old_path)
for file in old_list:
if os.path.isfile(filePath+'\\'+file):
print('源文件:"'+file+'"')
shutil.copy(old_path+'\\'+file,new_path)
print("复制完成")
话说我还一直以为是图片放到硬盘里不好读取才会出现bug
把50多个G的图片拷到了桌面
等了将近一小时拷完
现在还把我的电脑弄卡了
C盘巨红
以后一定要认真看看代码
很可能需要自己修改一下
下面要做的
由于我的标签和原图名称一样还都是tif格式
不能放在同一个文件夹里
所以得对文件名处理一下
图片批量重命名—Python批量给文件名加后缀
我的原图后缀都是“_sat”
我的样本后缀都是“_mask”
所以图片需要重命名一下
而且
我的文件名太长了

也有太长的不需要的前缀
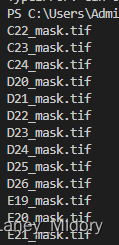
所以要在下划线处断开只保留后面
然后加上mask
效果如下
试运行之后成功
接下来就是完整代码
# -*- coding: utf-8 -*-
"""
Created on Mon May 17 17:30:47 2022
@author:Laney_Midory
csdn:Laney_Midory
"""
import os
path = 'C:/Users/Administrator/Desktop/train-water/'
#path = 'C:/Users/Administrator/Desktop/test/'
file_names = os.listdir(path)
for temp in file_names:
img = os.path.join(path, temp)
fname, ext = os.path.splitext(img)
base_name = os.path.basename(fname)
base_name = base_name.split('_')
new_n = base_name[1] +base_name[2]+ '_mask' + ext
print(os.path.join(path, new_n))
os.rename(os.path.join(path, temp), os.path.join(path, new_n))
os.path.splitext(“文件路径”) 分离文件名与扩展名;默认返回(fname,fextension)元组,可做分片操作
import os
path_01=‘D:/User/wgy/workplace/data/notMNIST_large.tar.gar’
path_02=‘D:/User/wgy/workplace/data/notMNIST_large’
root_01=os.path.splitext(path_01)
root_02=os.path.splitext(path_02)
print(root_01)
print(root_02)
结果:
(‘D:/User/wgy/workplace/data/notMNIST_large.tar’, ‘.gar’)
(‘D:/User/wgy/workplace/data/notMNIST_large’, ‘’)
os.path.basename()
函数作用:返回path最后的文件名
示例:
path=‘D:\file\cat\dog.jpg’
print(os.path.basename(path))
结果:
dog.jpg
想查看更多有关文件路径的操作可以查看这篇文章
结果如图:

同理对原图加上后缀并且重命名
最后就可以放在一个文件夹配好对啦

接下来就开始训练吧
样本顺利完成
以为这样就结束了么!!!!
oh no!!!
不要放心的太早
我检查了一下我的道路和河流样本
发现我确实在裁剪的时候删除掉了全黑的没有样本的图片
但是!!!
我的原图也有问题
道路和河流都会有白色的图片
这是本身数据的问题
不是我的操作的问题
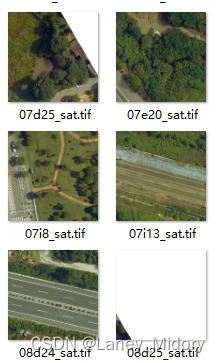
对于道路来说,这种情况只会发生在边缘图片的区域
会出现白色部分
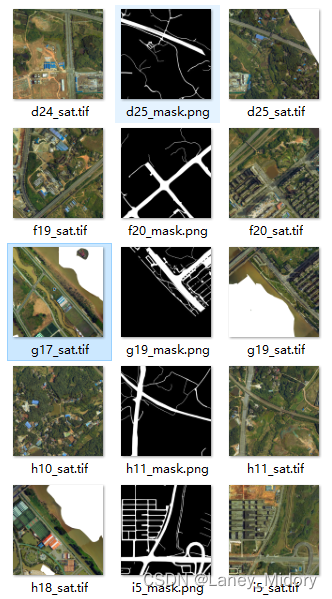
但对于河流来说
这些都是些什么图片!!!!!
这样的

这样的
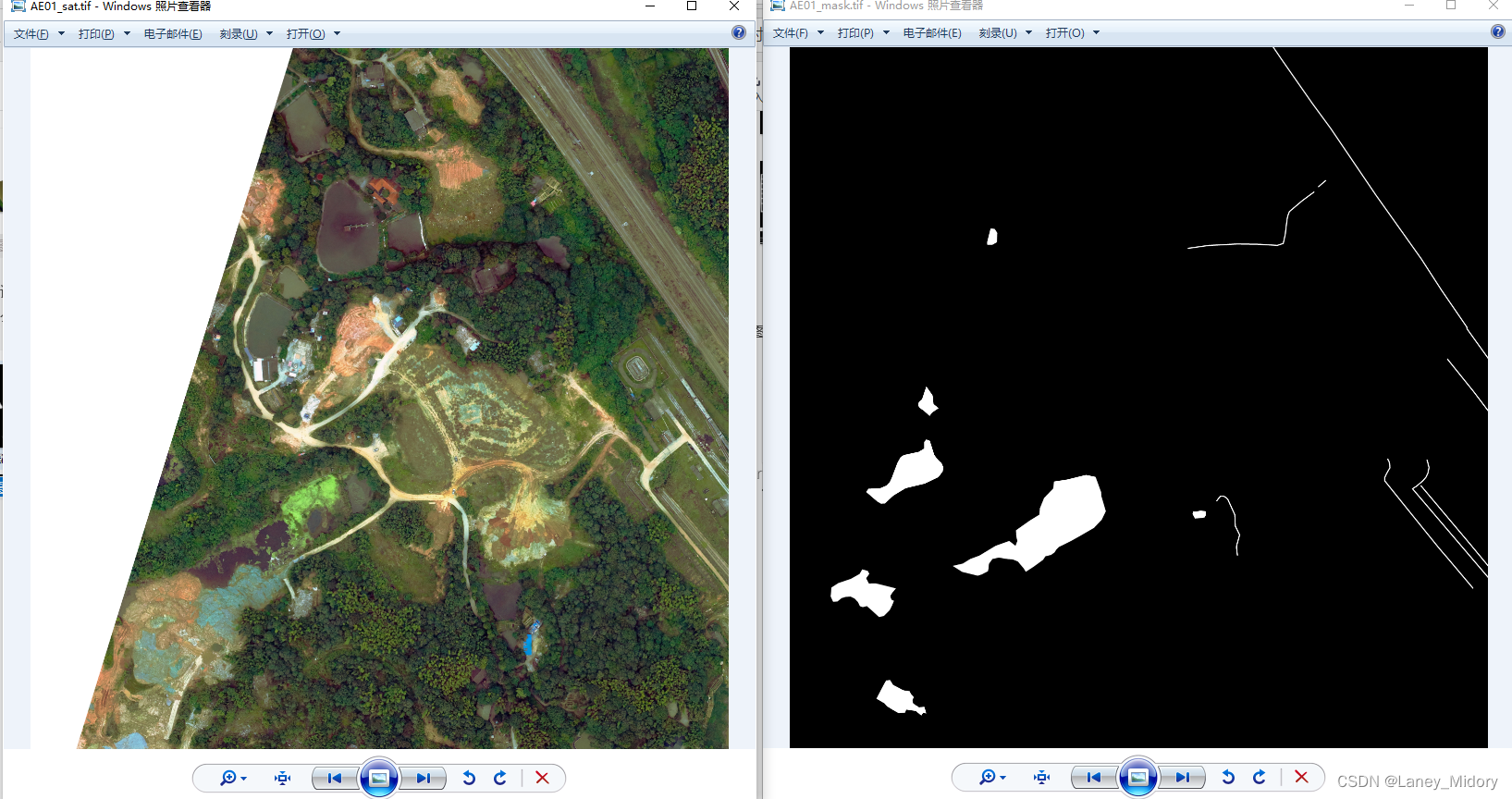
河流水体出现白色的也太过分了吧
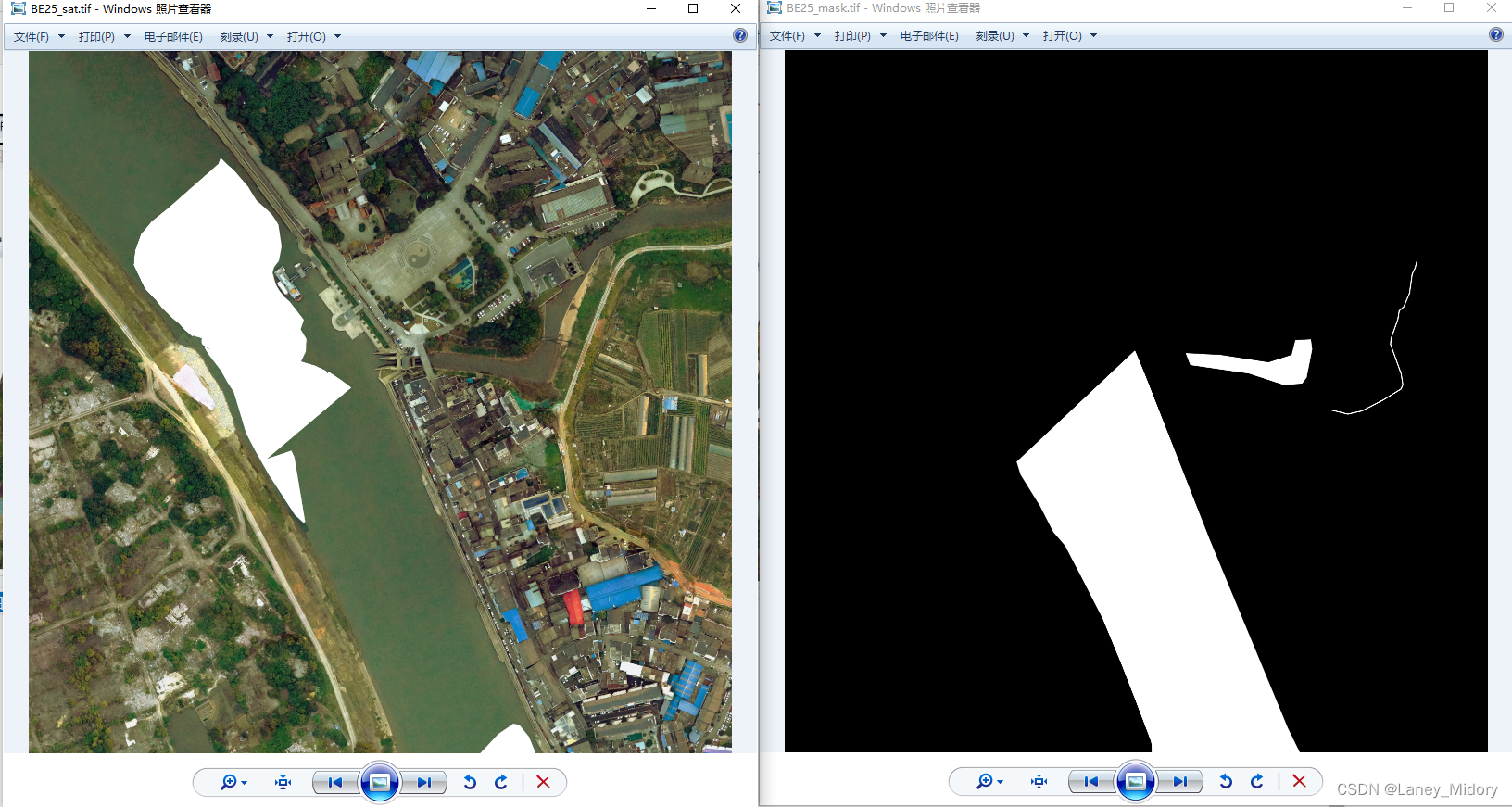
这还训练个鬼?不会对我的结果造成影响么
这是还没裁剪,还是6060大小的图片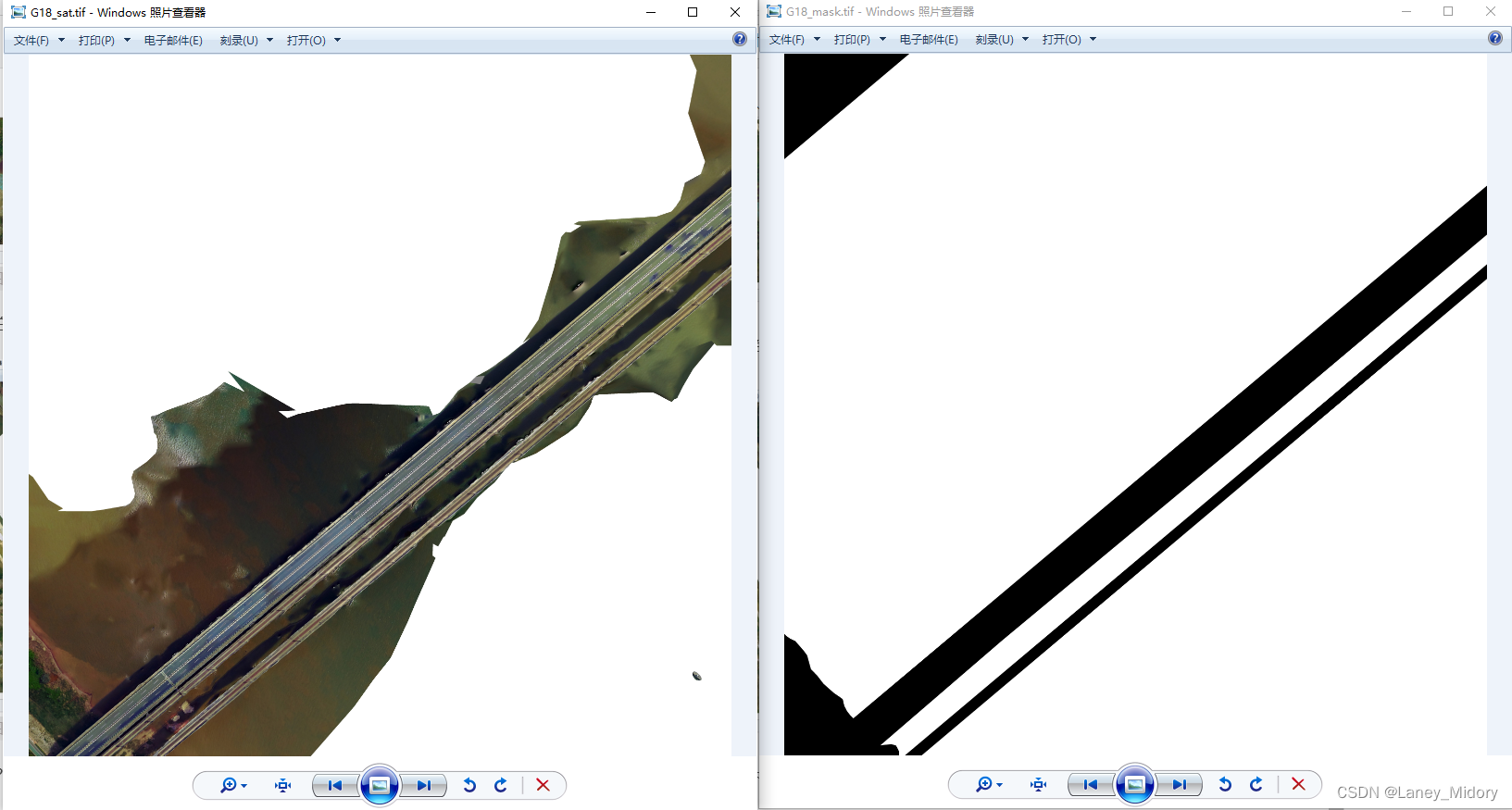
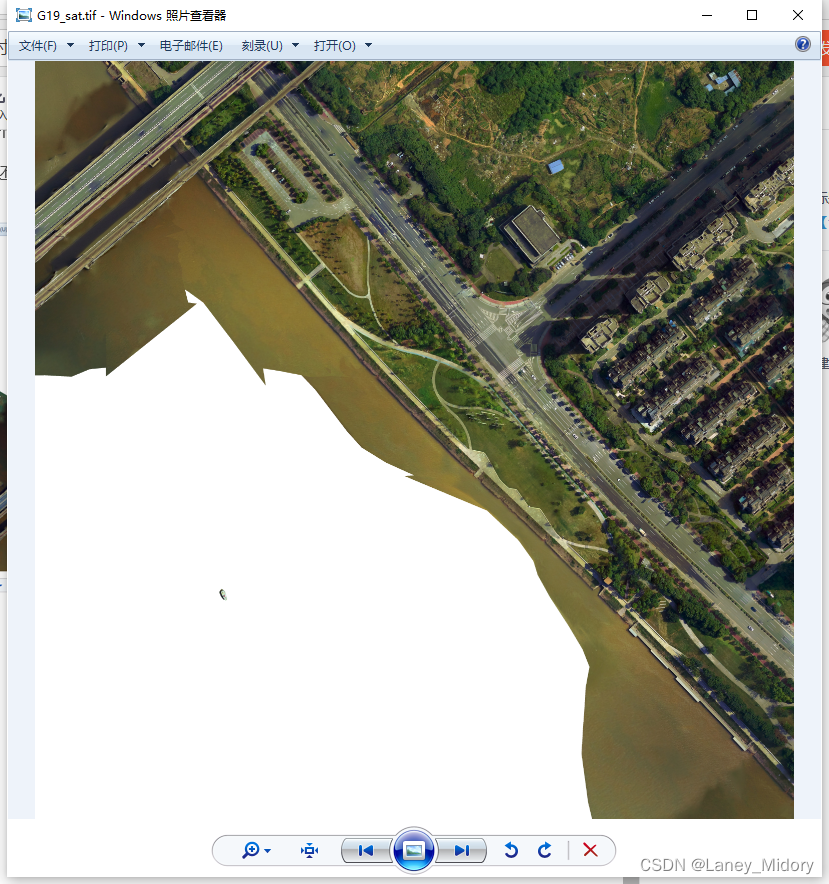
原图出现这个问题的图片真的非常多
接下来就是样本的问题
我发现一条很大的河流但是样本并没有画出来
这可怎么办
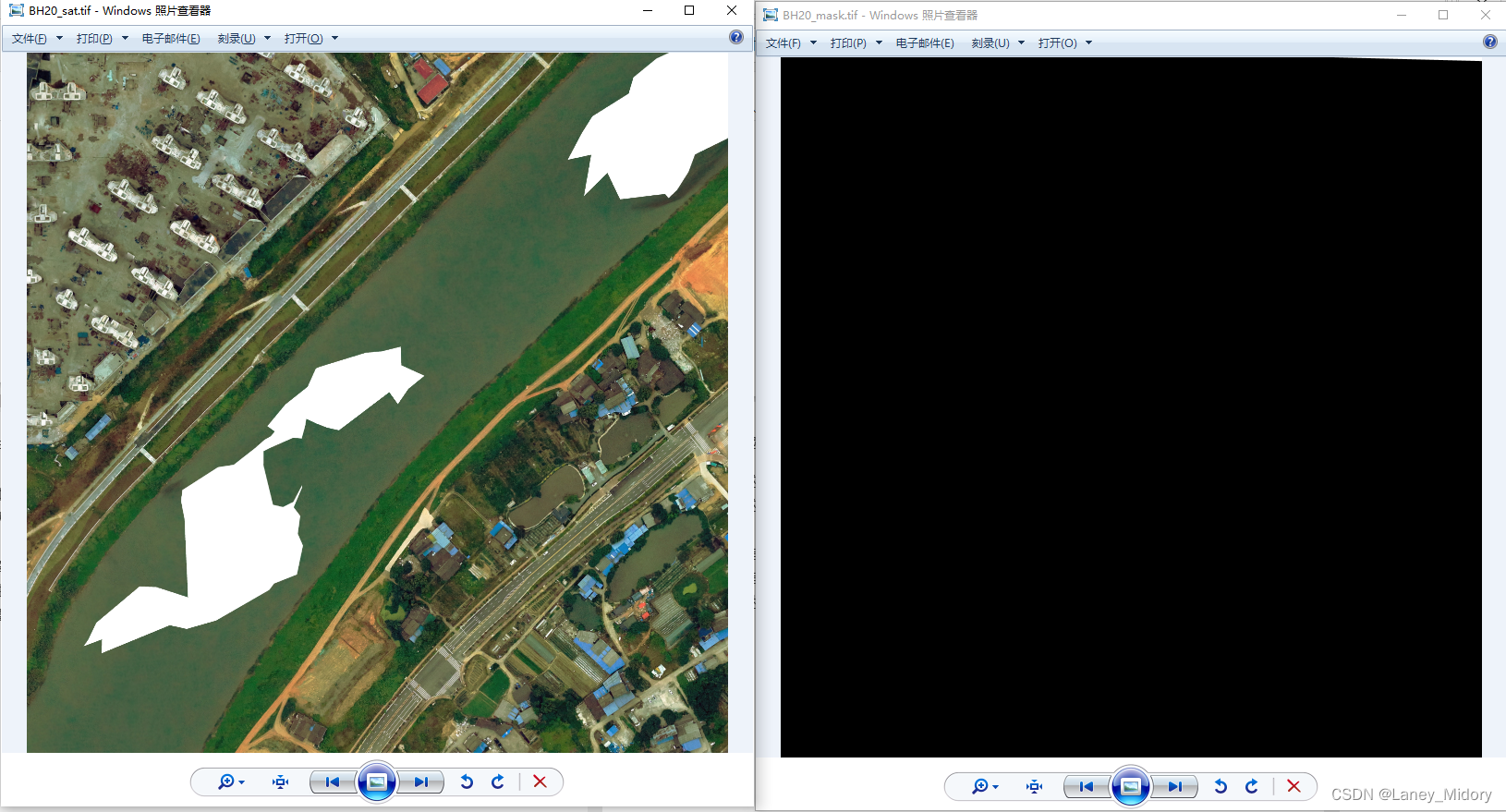
这是他本来就没有画的
我总不能无中生有吧
莫非要用激光雷达数据。。。。太无语了




















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











