




👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆下载资源链接👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆
《《《《《《《《更多资源还请持续关注本专栏》》》》》》》
论文与完整源程序_电网论文源程序的博客-优快云博客 https://blog.youkuaiyun.com/liang674027206/category_12531414.html
https://blog.youkuaiyun.com/liang674027206/category_12531414.html
 https://blog.youkuaiyun.com/LIANG674027206?type=download
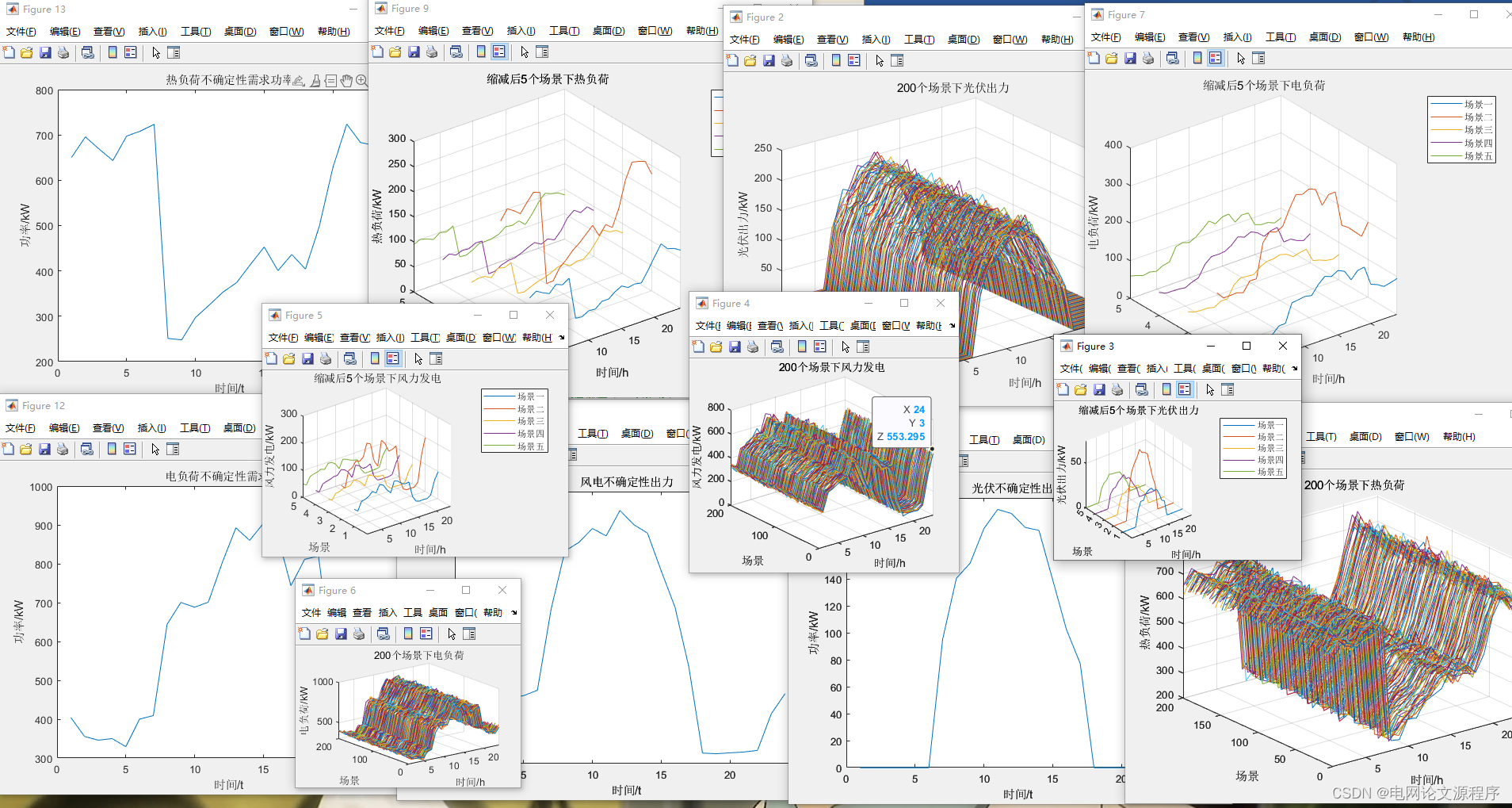
https://blog.youkuaiyun.com/LIANG674027206?type=download每个时刻用拉丁超立方抽样函数抽取200样本,服从正态分布,其中均值为原始数据,方差为一个0到1随机值×原始数据,然后基于概率距离快速削减算法再进行削减到5个场景,得出每个场景的概率与每个对应场景相乘求和得到不确定性出力
部分代码展示:
clc
clear all
%%
%场景法
%%% wf1 wf2 为平均值
shuju=xlsread('shuju.xlsx'); %把一天划分为24小时
d_load1=shuju(2,:);
h_load1=shuju(3,:);
P_wd1=shuju(4,:);
P_pv1=shuju(5,:);
d_load2=ones(24,200);
h_load2=ones(24,200);
P_wd2=ones(24,200);%风生成
P_pv2=ones(24,200);%光生成
P_zong=ones(24,200);
%%
%生成200个场景
%%
%拉丁差立方抽样方法
%%%拉丁超级方抽样=====属于分层抽样技术(从多元参数分布中近似随机抽样的方法)------分层抽样:将抽样区间(本程序为正态分布区间)
%按某种特性或某种规划分为不同的层,然后从不同的层中独立、随机(打乱排序,无规律抽取)
%地抽取样本(如取10个苹果样本,按照特性把苹果树分为5类,每类随机取2个),从而保证样本的结构与总体的结构比较相近,提高估计的精度。
%拉丁超立方相较蒙卡,改进了采样策略能够做到较小采样规模中获得较高的采样精度。
%%lhsnorm(mu,sigma,n); mu平均值(数量a); 求解公式:u=(1/N)*(sum(样本));N为样本数目
% sigma协方差矩阵(数量a*a); 求解公式: =((1/N)^3)*(sum(样本i-u)^2); i=1至N
% n抽样次数
% 表示方式1
c=1;%c 表示基础数据的数量
u1=lhsdesign(1,24);
u2=lhsdesign(1,24);
for t=1:24
P_wd2(t,:)=lhsnorm(sum(P_wd1(:,t))/c,u1(t)*sum(P_wd1(:,t))/c,200); %拉丁超立方抽样(lhsnorm函数)方法
d_load2(t,:)=lhsnorm(sum(d_load1(:,t))/c,u1(t)*sum(d_load1(:,t))/c,200);
h_load2(t,:)=lhsnorm(sum(h_load1(:,t))/c,u1(t)*sum(h_load1(:,t))/c,200);
if t>=7&&t<=17
P_pv2(t,:)=lhsnorm(sum(P_pv1(:,t))/c,u2(t)*sum(P_pv1(:,t))/c,200);
else
P_pv2(t,:)=0;
end
P_zong(t,:)=P_wd2(t,:)+P_pv2(t,:)+d_load2(t,:)+h_load2(t,:);
end
d_load3=d_load2;
h_load3=h_load2;
P_wd3=P_wd2;
P_pv3=P_pv2;
%%
%场景削减(快速后向削减)
%原理:确定初始场景集合的一个子集,并给其重新分配场景概率,使保留场景的概率分布Q与初始场景集合的概率P之间的某种概率距离最短(即,P与Q相近),
%从而削减概率小的概率,将其加到与其场景的概率距离最近的场景上。
%%
%计算各个场景之间的概率距离
k=zeros(200,200);
for i=1:200
for j=1:200
if i==j
k(i,j)=0;%K距离
else
k(i,j)=sqrt(sum((P_zong(:,i)-P_zong(:,j)).^2));
end
end
end
p=ones(200,1)*0.005;%各场景初始概率 p=ones(a,1)*b a为场景数 a*b==1
%%
%%寻找最小概率距离场景效果展示:
102号资源-程序:《拉丁超立方源荷场景生成》本人博客有解读资源-优快云文库https://download.youkuaiyun.com/download/LIANG674027206/89272069 👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆下载资源链接👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆👆
《《《《《《《《更多资源还请持续关注本专栏》》》》》》》
论文与完整源程序_电网论文源程序的博客-优快云博客https://blog.youkuaiyun.com/liang674027206/category_12531414.html


















 3867
3867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











