



1.
提示词要素:
(1)指令:想要模型执行的特定任务或指令
(2)上下文:包含外部信息或者额外上下文信息,从而引导模型按照特定方向进行响应
(3)输入数据:用户输入内容或问题
(4)输出提示:指定输出类型或者格式
并非所有提示词要素都必须
强调:指令(命令),具体性(详细说明希望执行的任务),避免不明确,避免不要做什么而是强调需要做什么。
2.提示词工程
1.实际上如今大语言模型会通过RLHF(来自人类反馈的强化学习)进行训练,在面对简单的问题时,已经预训练过的模型已经可以很好完成任务,通过详细指令强调,可以做到零样本提示生成。
2.但是面对复杂生成问题时,则需要通过少样本提示生成。
提示:
“whatpu”是坦桑尼亚的一种小型毛茸茸的动物。一个使用whatpu这个词的句子的例子是:我们在非洲旅行时看到了这些非常可爱的whatpus。“farduddle”是指快速跳上跳下。一个使用farduddle这个词的句子的例子是:
生成:
当我们赢得比赛时,我们都开始庆祝跳跃。
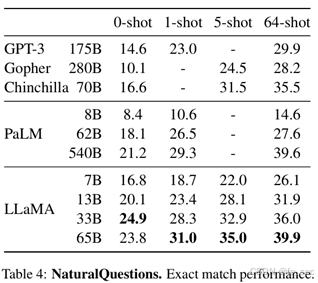
在LLaMA提出时进行测试中,发现模型规模足够大时,k-shot可以更好的进行模型生成,在相同LLaMA 65b模型下,64-shot表现准确度为39.9,但是0-shot表现准确度只有23.8。
3.链式思考(CoT)提示。
Kojima等人提出zero-shot-CoT提示。也就是加上“Think step by step”。但是现在模型以及内置Auto-Cot,所以其除了训练Auto-CoT之外没什么用。
Auto-CoT:
其主要由两个阶段组成:
1.问题聚类:将给定问题划分聚类
2.演示抽样:每组中选择代表性的问题,通过zero-shot-CoT进行生成推理链。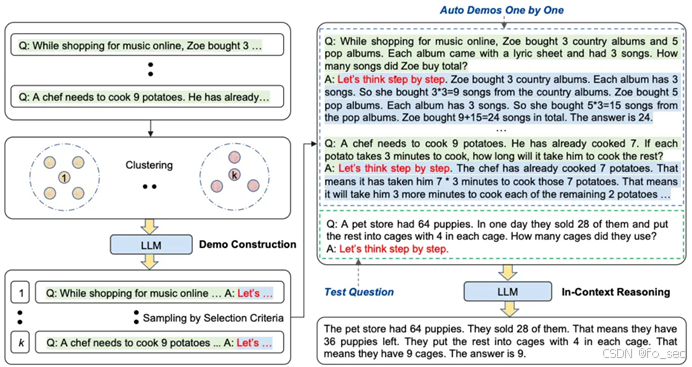
4.思维树提示(ToT)
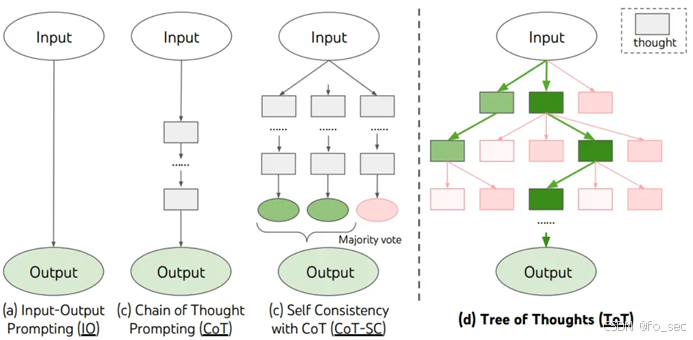
由于传统的思维链等无法准确进行探索或者预判操作,Yao(2023)提出了思维树框架,即基于思维链进行总结,引导语言模型探索把思维链作为中间步骤解决通用问题。目前主流的Yao采用深度优先/广度优先搜索,而Long(2023)提出由强化学习训练ToT控制器驱动树搜索策略。
(用在线的Deepseek-R1实测下来没卵用,可能是因为Deepseek等已经内部接入CoT思考,将不会采用ToT思考)

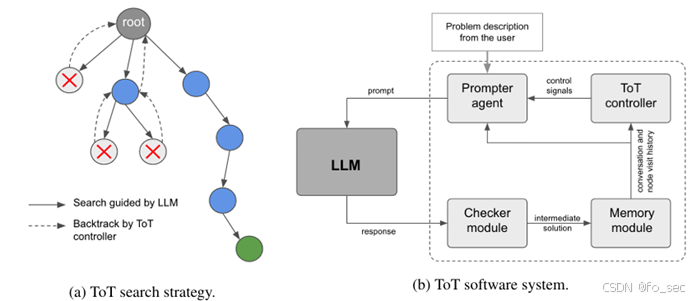
下中通过prompt接入LLM,回答经过checker module进行correctness check,而后经过memory module(存储完整交谈数据)进行ToT controller控制。如果ToT controller认为输出不正确或者无法找到最终解决方案,则返回父节点。
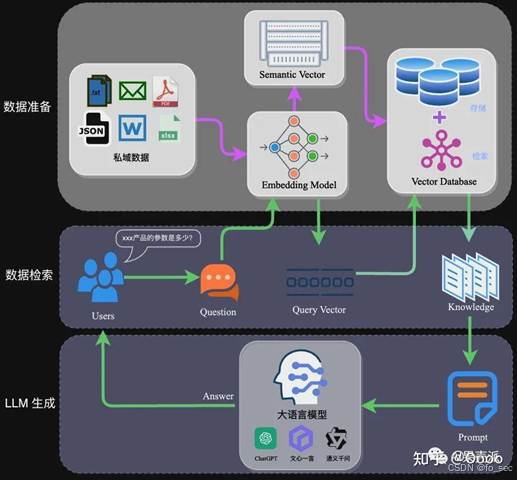
5.RAG
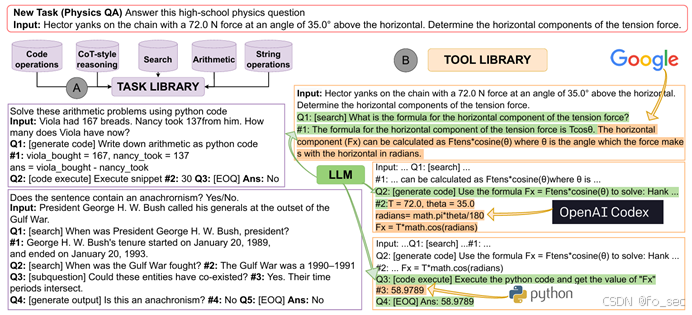
6.自动推理并使用工具(ART)
由于Auto-CoT存在,任务可以拆分为多个步骤组合成Task library,在此基础上引入Tool library,在不同任务时可以调用相关工具进行进一步运算。例如下图:面对问题首先google得出公式,通过OpenAI Codex进行编程,最后调用python进行code运算。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









