






PyTorch Lightning官方:https://lightning.ai/
文档:https://lightning.ai/docs/pytorch/stable/
PyTorch Lightning官方源码:https://github.com/Lightning-AI/pytorch-lightning?tab=readme-ov-file
Keras中文文档:https://keras-zh.readthedocs.io/callbacks/(进入这里查看会发现Keras中集成的东西和PyTorch Lightning部分地方都很像)
本文涉及代码:https://github.com/KeepTryingTo/DeepLearning/tree/main/pytorch_lightning
论文CrowdCLIP(基于CLIP的无监督人群计数模型)详解(PyTorch,Pytorch_Lighting)
论文CLIP-Count(基于文本指导的零样本目标计数)详解(PyTorch)
前置了解
简介:PyTorch Lightning 是一个基于 PyTorch 的高级深度学习框架,旨在将科研代码的灵活性与工程化最佳实践结合,通过标准化训练流程大幅减少模板代码。其中,继承LightningModule之后,可以很方便的把自己的训练过程,验证以及测试过程都给集成起来,包括优化器的配置等函数,可以比较容易的进行配置和训练。定义Trainer之后,结合继承至LightningModule对象,就可以实现完整的训练了(除了一些额外的配置之外)。这个视频和文字教程就是想让大家快速的上手PyTorch Lightning,这也是自己在看代码的时候遇到的问题。虽然PyTorch Lightning帮我们集成了很多东西,但是在调试和解决错误的时候会比较麻烦。
我相信本文讲解之后,你对PyTorch Lightning会有不同的看法,甚至想上手去尝试快速写出自己的代码。
-
自动支持以下功能,无需手动实现:
- 多GPU/TPU训练
-
混合精度训练
-
梯度裁剪
-
早停(Early Stopping)
-
模型检查点保存
-
跨平台兼容性
-
同一代码可无缝运行于:
-
CPU/GPU/TPU
-
单机或多节点集群
-
云平台(AWS、GCP等)
-
PyTorch Lightning和torch之间的版本关系:下载PyTorch Lightning和torch的时候一定要注意这个版本问题:https://lightning.ai/docs/pytorch/latest/versioning.html#compatibility-matrix
注:假设你已经下载了一个cuda版本的torch,但是现在下载最新版本的PyTorch Lightning的话,就很可能会导致PyTorch Lightning下载过程中重新安装一个CPU版本的torch,把之前的cuda版本的torch覆盖掉,所以特别注意版本之间关系问题。
-
pytorch_lightning(旧包名):
PyTorch Lightning 最初发布的包名(2019年至今),专为 PyTorch 用户设计。 -
lightning(新包名):
从 Lightning 2.0 版本(2023年)开始推出的新包名,作为统一入口,支持多框架(如 PyTorch、JAX 等)。
目录
五 ModelCheckpoint和EarlyStopping
一 安装
pip install lightning -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
或者
pip install pytorch_lightning -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
以上都是下载当前最新版本,如果指定版本,如下类似:
pip install pytorch_lightning==1.9 -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple注:我之前就已经安装的是pytorch_lightning ,所以就用pytorch_lightning 来讲解(都一样的)。
二 Trainer类
2.1 基础参数配置
| 参数 | 类型 | 默认值 | 说明 |
| max_epochs | int | None | 最大训练轮次(必填) |
| min_epochs | int | 1 | 最小训练轮次 |
| max_steps | int | -1 | 最大训练步数(总batch迭代次数,优先级高于max_epochs) |
| min_steps | int | -1 | 最小训练步数 |
| accelerator | str | "auto" | 硬件加速器("cpu", "gpu", "tpu", "auto") |
| devices | int/list | "auto" | 使用的设备数量(如 devices=2 用2个GPU) |
2.2 训练参数配置
| 参数 | 说明 |
| gradient_clip_val | 梯度裁剪阈值(如 1.0) |
| accumulate_grad_batches | 梯度累积步数(模拟更大batch) |
| limit_train_batches | 限制每epoch训练batch数(如 0.1 表示10%) |
| limit_val_batches | 限制验证batch数 |
| val_check_interval | 验证频率(1.0=每epoch,0.5=每半个epoch) |
| check_val_every_n_epoch | 每N轮验证一次(默认 1) |
| 参数 | 说明 |
| fast_dev_run | 快速运行少量batch(如 True 或 5) |
| overfit_batches | 过拟合少量batch(测试代码) |
| precision | 精度("32"-全精度, "16"-半精度, "bf16") |
2.3 回调日志
| 参数 | 说明 |
| logger | 日志器(如 TensorBoardLogger、WandbLogger) |
| callbacks | 回调列表(如 ModelCheckpoint, EarlyStopping) |
| log_every_n_steps | 每N步记录一次日志(默认 50) |
trainer = L.Trainer(
limit_train_batches=100,
max_epochs=10,
callbacks=[save_callback],
val_check_interval=5
)2.4 多显卡GPU或者TPU训练
# 8 块上GPUs训练模型
trainer = Trainer(accelerator="gpu", devices=8)
# 256 块GPUs训练模型
trainer = Trainer(accelerator="gpu", devices=8, num_nodes=32)
# 指定单卡(例如 GPU 1)
trainer = Trainer(accelerator="gpu", devices=[1]) # 使用索引为1的GPU
# 指定多卡(例如 GPU 0和2)
trainer = Trainer(accelerator="gpu", devices=[0, 2]) # 使用索引0和2的GPU
# 自动选择可用GPU(不推荐,可能不可控)
trainer = Trainer(accelerator="gpu", devices="auto")
# 训练在TPU上(Google开发的加速器)
trainer = Trainer(accelerator="tpu", devices=8)
# 半精度训练模型
trainer = Trainer(precision=16)
2.5 训练日志
#TensorFlow可视化工具包: tensorboard
https://www.tensorflow.org/tensorboard
trainer = Trainer(logger=TensorBoardLogger("logs/"))
from pytorch_lightning import Trainer
from pytorch_lightning.loggers import TensorBoardLogger
logger = TensorBoardLogger("tb_logs", name="my_model")
trainer = Trainer(logger=logger)# weights and biases
trainer = Trainer(logger=loggers.WandbLogger())
from pytorch_lightning.loggers import WandbLogger
from pytorch_lightning import Trainer
wandb_logger = WandbLogger()
trainer = Trainer(logger=wandb_logger)# comet
trainer = Trainer(logger=loggers.CometLogger())
Comet需要API Key(在线模式)或本地目录路径(离线模式)
import os
from pytorch_lightning import Trainer
from pytorch_lightning.loggers import CometLogger
#在线模式
comet_logger = CometLogger(
api_key=os.environ.get('COMET_API_KEY'),
workspace=os.environ.get('COMET_WORKSPACE'),
save_dir='.',
project_name='default_project',
rest_api_key=os.environ.get('COMET_REST_API_KEY'),
experiment_key=os.environ.get('COMET_EXPERIMENT_KEY'),
experiment_name='default' # Optional
)
trainer = Trainer(logger=comet_logger)
#离线模式
from pytorch_lightning.loggers import CometLogger
# arguments made to CometLogger are passed on to the comet_ml.Experiment class
comet_logger = CometLogger(
save_dir='.',
workspace=os.environ.get('COMET_WORKSPACE'),
project_name='default_project',
rest_api_key=os.environ.get('COMET_REST_API_KEY'),
experiment_name='default'
)
trainer = Trainer(logger=comet_logger)# mlflow
https://mlflow.org/#integrations
trainer = Trainer(logger=loggers.MLFlowLogger())
from pytorch_lightning import Trainer
from pytorch_lightning.loggers import MLFlowLogger
mlf_logger = MLFlowLogger(
experiment_name="default",
tracking_uri="file:./ml-runs"
)
trainer = Trainer(logger=mlf_logger)# neptune
trainer = Trainer(logger=loggers.NeptuneLogger())
from pytorch_lightning import Trainer
from pytorch_lightning.loggers import NeptuneLogger
#模式1
neptune_logger = NeptuneLogger(
api_key='ANONYMOUS',
project_name='shared/pytorch-lightning-integration',
experiment_name='default',
params={'max_epochs': 10},
tags=['pytorch-lightning', 'mlp']
)
trainer = Trainer(max_epochs=10, logger=neptune_logger)
#模式2
from pytorch_lightning.loggers import NeptuneLogger
neptune_logger = NeptuneLogger(
offline_mode=True,
project_name='USER_NAME/PROJECT_NAME',
experiment_name='default', # Optional,
params={'max_epochs': 10}, # Optional,
tags=['pytorch-lightning', 'mlp'] # Optional,
)
trainer = Trainer(max_epochs=10, logger=neptune_logger)| Logger | 适用平台 | 主要特点 | 适用场景 |
| TensorBoardLogger | 本地/TensorBoard | 轻量级,快速可视化 | 本地调试、简单实验 |
| WandbLogger | Weights & Biases | 实时同步、团队协作、强大可视化 | 学术研究、团队项目 |
| CometLogger | Comet.ml | 自动化报告、数据集版本管理 | 企业级实验管理 |
| MLFlowLogger | MLflow | 实验跟踪 → 模型部署一体化 | MLOps、生产环境部署 |
| NeptuneLogger | Neptune.ai | 高度自定义、私有化部署支持 | 企业级复杂实验管理 |
例举tensorboard
注意:模型中我们直接使用self.log保存日志信息之后,也是使用tensorboard --logdir=./lightning_logs打开可视化结果
class LitAutoEncoder(L.LightningModule):
def __init__(self,
encoder,
decoder,
save_dir : str = None
):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.save_dir = save_dir
def training_step(self, batch, batch_idx):
# training_step defines the train loop.
# it is independent of forward
x, _ = batch
x = x.view(x.size(0), -1)
x_hat = self(x)
loss = nn.functional.mse_loss(x_hat, x)
# Logging to TensorBoard (if installed) by default
self.log("train_loss", loss)
return loss
def validation_step(self, val_batch, batch_idx):
x,_ = val_batch
x = x.view(x.size(0), -1)
x_hat = self(x)
loss = nn.functional.mse_loss(x_hat, x)
self.log("val_loss", loss)self.log("val_loss", loss)日志保存之后,也同样可以使用tensorboard打开,那和使用logger.TensorBoardLogger有什么区别?
| 直接使用 self.log | 使用 TensorBoardLogger | |
| 日志存储位置 | 默认保存在 lightning_logs/version_X 目录 | 可自定义路径(如 logs/exp_name) |
| 日志格式 | 自动生成 TensorBoard 兼容的 events.out.tfevents | 明确指定 TensorBoard 格式,支持更多自定义选项 |
| 多日志器支持 | 需手动配置其他 Logger | 专为 TensorBoard 优化,但可与其他 Logger 共存 |
| 额外功能 | 依赖 Trainer 的默认配置 | 支持自定义实验分组、版本命名等高级功能 |
self.log参数介绍
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
name | str | - | 指标的键名(如 "val_loss"),用于后续查询或可视化 |
value | Any | - | 指标值(必须是 Tensor 或标量) |
prog_bar | bool | False | 若为 True,指标会显示在训练进度条上 |
logger | bool | True | 若为 True,指标会记录到日志器(如 TensorBoard/WandB) |
_step | Optional[bool] | None | 若为 True,记录当前 batch 的值。• None 时自动行为:- 训练阶段: True(每 batch 记录)- 验证/测试阶段: False |
on_epoch | Optional[bool] | None | 若为 True,记录整个 epoch 的累积值(如平均 loss)。• None 时自动行为:- 训练阶段: False- 验证/测试阶段: True |
reduce_fx | Callable | torch.mean | epoch 级累积时的聚合函数(如 mean/sum/max) |
tbptt_reduce_fx | Callable | torch.mean | 截断反向传播(TBPTT)时的序列数据聚合函数 |
tbptt_pad_token | int | 0 | TBPTT 序列填充的 token(用于 NLP 任务) |
sync_dist | bool | False | 若为 True,跨 GPU/TPU 同步指标(多卡训练必备) |
sync_dist_op | Union[Any, str] | 'mean' | 同步操作(如 'mean'/'sum') |
sync_dist_group | Optional[Any] | None | 指定同步的进程组 |
三 转换保存格式
模式1
autoencoder = LitAutoEncoder()
torch.jit.save(autoencoder.to_torchscript(), "model.pt")模式2
with tempfile.NamedTemporaryFile(suffix=".onnx", delete=False) as tmpfile:
autoencoder = LitAutoEncoder()
input_sample = torch.randn((1, 64))
autoencoder.to_onnx(tmpfile.name, input_sample, export_params=True)
os.path.isfile(tmpfile.name)
参数介绍:
tmpfile.name:临时文件路径。
input_sample:示例输入(用于推断模型输入形状)。
export_params=True:将模型参数(权重)嵌入到 ONNX 文件中大家也可以根据自己需要看一下下面之前讲的不同框架的中格式转换方式:
QT 6.6.0 中腾讯优图NCNN环境配置以及基于ONNX转NCNN模型文件实现图像分类
QT 6.6.0 中腾讯优图NCNN环境配置以及基于PNNX转NCNN模型文件实现目标检测
QT 6.6.0 中腾讯优图NCNN环境配置以及基于PNNX转NCNN模型文件实现图像分割
PyTorch加载预训练目标检测模型实现物体检测,同时将预训练模型转换为ONNX模型文件(过程详解)
PyTorch 训练之后的网络模型.pth转.onnx文件并对图像进行预测
四 学习率调度器(configure_optimizer)
带学习率的调度器
def configure_optimizers(self):
optimizer = torch.optim.SGD(self.parameters(), lr=0.1)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
return {
"optimizer": optimizer,
"lr_scheduler": {
"scheduler": scheduler,
"interval": "epoch", # 或 "step"
"frequency": 1, # 每1个interval调用一次
}
}
关键参数:
interval: 调度器触发时机 ("epoch" 或 "step")
frequency: 每隔 N 个 interval 触发一次
monitor: 监控指标多优化器
def configure_optimizers(self):
# 生成器和判别器分开优化
gen_opt = torch.optim.Adam(self.generator.parameters(), lr=1e-4)
disc_opt = torch.optim.Adam(self.discriminator.parameters(), lr=1e-3)
# 为判别器添加调度器
disc_sch = torch.optim.lr_scheduler.CosineAnnealingLR(disc_opt, T_max=10)
return [gen_opt, disc_opt], [disc_sch]
注意:Lightning 会自动按顺序调用 optimizer.step()
参数分组和不同学习率
def configure_optimizers(self):
params = [
{"params": self.backbone.parameters(), "lr": 1e-4},
{"params": self.head.parameters(), "lr": 1e-3}
]
return torch.optim.AdamW(params)监控指标动态调度
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters())
return {
"optimizer": optimizer,
"lr_scheduler": {
"scheduler": torch.optim.ReduceLROnPlateau(optimizer, patience=3),
"monitor": "val_loss", # 监控验证集损失
"interval": "epoch",
"frequency": 1,
}
}五 ModelCheckpoint和EarlyStopping
save_callback = L.callbacks.ModelCheckpoint(
monitor='val_loss', # 监控验证集损失(需与日志中的键名一致)
save_top_k=1, # 只保留最优的 1 个模型(改为 4 需调整)
mode='min', # 取最小值(损失越小越好)
filename='{epoch}-{val_mae:.2f}', # 文件名格式:epoch-验证集MAE
dirpath='checkpoints/', # 可选:指定保存目录
save_last=True, # 可选:额外保存最后一个epoch的模型
)early_stopping = L.callbacks.EarlyStopping(
monitor='val_loss', # 监控指标(需与日志一致)
min_delta=0.1, # 最小改进阈值(变化小于此值视为无改进)
patience=5, # 容忍的连续无改进epoch数
verbose=True, # 打印早停信息
mode='min', # 监控指标越小越好
check_finite=True, # 可选:跳过NaN/inf值
stopping_threshold=None # 可选:达到绝对阈值时立即停止
)六 加载数据集方式
LightningDataModule 是一个用于标准化数据加载和处理流程的类,它将数据相关的代码(如下载、预处理、划分数据集等)封装在一起,使项目更模块化且易于复用。当然也可以不使用LightningDataModule 数据加载,也可以使用torch.utils.data.Dataset和DataLoader来自定义数据加载方式,没有一定要求使用LightningDataModule 。
| 方法 | 作用 |
|---|---|
prepare_data() | 下载数据或一次性处理(如解压、生成缓存),仅在全局调用一次(如 rank_zero_only)。 |
setup() | 数据分割和预处理(如划分训练集/验证集/测试集),每个进程都会调用。 |
train_dataloader() | 返回训练集的 DataLoader。 |
val_dataloader() | 返回验证集的 DataLoader。 |
test_dataloader() | 返回测试集的 DataLoader(可选)。 |
predict_dataloader() | 返回预测用的 DataLoader(可选)。 |
比如下面加载MNIST数据集的方式以及使用(后面我们给出了更多例子供大家参考):
import torch
from torch.utils.data import DataLoader, random_split
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
import pytorch_lightning as pl
class MNISTDataModule(pl.LightningDataModule):
def __init__(self, data_dir: str = "./data", batch_size: int = 32):
super().__init__()
self.data_dir = data_dir
self.batch_size = batch_size
self.transform = ToTensor()
def prepare_data(self):
# 下载数据(仅在 rank 0 上执行一次)
MNIST(self.data_dir, train=True, download=True)
MNIST(self.data_dir, train=False, download=True)
def setup(self, stage: Optional[str] = None):
# 划分数据集(每个进程都会调用)
if stage == "fit" or stage is None:
mnist_full = MNIST(self.data_dir, train=True, transform=self.transform)
self.mnist_train, self.mnist_val = random_split(mnist_full, [55000, 5000])
if stage == "test" or stage is None:
self.mnist_test = MNIST(self.data_dir, train=False, transform=self.transform)
def train_dataloader(self):
return DataLoader(self.mnist_train, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
return DataLoader(self.mnist_val, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.mnist_test, batch_size=self.batch_size)class LitModel(pl.LightningModule):
def __init__(self):
super().__init__()
self.model = torch.nn.Linear(28 * 28, 10)
def training_step(self, batch, batch_idx):
x, y = batch
x = x.view(x.size(0), -1) # 展平图像
y_hat = self.model(x)
loss = torch.nn.functional.cross_entropy(y_hat, y)
self.log("train_loss", loss)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.model.parameters())
# 训练模型
data_module = MNISTDataModule(batch_size=64)
model = LitModel()
trainer = pl.Trainer(max_epochs=10)
trainer.fit(model, datamodule=data_module) # 自动调用数据加载方法或者自定义数据加载方式如下:
class myDataset(torch.utils.data.Dataset):
def __init__(self,split = 'train'):
super().__init__()
self.split = split
pass
def __len__(self):
pass
def __getitem__(self, item):
pass
class customModel(L.LightningModule):
def __init__(self):
super().__init__()
pass
def training_step(self, batch, batch_dix):
pass
train_dataset = myDataset(split='train')
test_dataset = myDataset(split='test')
train_dataloader = DataLoader(dataset=train_dataset, batch_size=2, shuffle=True)
test_dataloader = DataLoader(dataset=test_dataset, batch_size=1, shuffle=False)
model = customModel()
train_ = L.Trainer(
max_epochs=10,
devices=[0],
check_val_every_n_epoch=1
)
train_.fit(
model,
train_dataloaders= train_dataloader,
val_dataloaders=test_dataloader
)七 整体模型训练框架
LightningModule中函数的大致调用过程
[初始化]
├─ __init__()
├─ prepare_data() # 数据下载(可选)
└─ setup(stage) # 数据拆分(可选)
[数据加载]
├─ train_dataloader()
├─ val_dataloader()
└─ test_dataloader()
[训练循环]
for epoch in max_epochs:
[训练阶段]
├─ on_train_epoch_start()
│ for batch in train_loader:
│ ├─ training_step()
│ ├─ backward() # 自动调用
│ ├─ optimizer_step() # 可覆盖
│ └─ on_train_batch_end()
└─ on_train_epoch_end()
[验证阶段]
├─ on_validation_epoch_start()
│ for batch in val_loader:
│ ├─ validation_step()
│ └─ on_validation_batch_end()
└─ on_validation_epoch_end()
[测试/预测]
├─ test_step() # 类似validation_step
└─ predict_step() # 自定义预测逻辑训练模型搭建框架
# define the LightningModule
class LitAutoEncoder(L.LightningModule):
def __init__(self,
model,
save_dir : str = None
):
super().__init__()
self.model = model
self.save_dir = save_dir
def on_train_start(self) -> None:
pass
def on_train_batch_start(self, batch: Any, batch_idx: int) -> None:
pass
def on_train_end(self) -> None:
pass
def on_train_epoch_end(self) -> None:
pass
def configure_optimizers(self):
pass
def training_step(self, batch, batch_idx):
pass
def validation_step(self, val_batch, batch_idx):
pass
def backward(self, loss: Tensor, optimizer: Optimizer, optimizer_idx: int, *args, **kwargs) -> None:
pass
def configure_optimizers(self):
pass
def forward(self, x):
pass训练模型框架继承:LightningModule,下面给出常用继承函数的使用以及最后给出重新函数例子
(1) 初始化与配置
| 方法 | 必须实现 | 说明 |
| __init__() | 是 | 定义模型结构、超参数 |
| configure_optimizers() | 是 | 返回优化器(及可选的学习率调度器),这个上面优化器的配置已经讲了 |
(2) 数据加载
| 方法 | 必须实现 | 说明 |
| train_dataloader() | 否 | 返回训练集 DataLoader |
| val_dataloader() | 否 | 返回验证集 DataLoader |
| test_dataloader() | 否 | 返回测试集 DataLoader |
| predict_dataloader() | 否 | 返回预测集 DataLoader |
注:数据加载部分完全可以在“训练模型框架”之外加载好
(3) 训练/验证/测试逻辑
| 方法 | 说明 |
| training_step(batch, batch_idx) | 必须实现:定义训练批次逻辑(计算损失、日志) |
| validation_step(batch, batch_idx) | 定义验证批次逻辑(推荐实现) |
| test_step(batch, batch_idx) | 定义测试批次逻辑 |
| predict_step(batch, batch_idx) | 定义预测逻辑(默认调用 forward) |
(4) 钩子函数(可选)
| 方法 | 调用时机 | 用途 |
| on_train_start() | 训练开始时 | 初始化全局变量,训练开始时准备工作 |
| on_train_epoch_start() | 每个epoch开始时 | 重置指标,比如重新累积损失loss |
| on_train_batch_end() | 每个batch结束后 | 后处理/日志,训练完一个batch之后的处理,比如记录loss |
| on_validation_epoch_end() | 验证epoch结束时 | 汇总验证结果,一个epochs验证结束之后需要处理的东西 |
| on_fit_end() | 训练完全结束时 | 保存模型/清理资源 |
八 完整例子
"""
@Author : Keep_Trying_Go
@Major : Computer Science and Technology
@Hobby : Computer Vision
@Time : 2025/5/18-18:42
@优快云 : https://blog.youkuaiyun.com/Keep_Trying_Go?spm=1010.2135.3001.5421
"""
import os
from typing import Any
import torch
from torch import nn
from torch import optim, nn, utils, Tensor
from torch.optim import Optimizer
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
import pytorch_lightning as L
from pytorch_lightning import loggers
from torch.utils.data import DataLoader
# define any number of nn.Modules (or use your current ones)
class Encoder(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(28 * 28, 64),
nn.ReLU(),
nn.Linear(64, 3)
)
def forward(self,x):
return self.encoder(x)
class Decoder(nn.Module):
def __init__(self):
super().__init__()
self.decoder = nn.Sequential(
nn.Linear(3, 64),
nn.ReLU(),
nn.Linear(64, 28 * 28)
)
def forward(self,x):
return self.decoder(x)
# define the LightningModule
class LitAutoEncoder(L.LightningModule):
def __init__(self,
encoder,
decoder,
save_dir : str = None
):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.save_dir = save_dir
def on_train_start(self) -> None:
if os.path.exists(self.save_dir):
os.mkdir(self.save_dir)
def on_train_batch_start(self, batch: Any, batch_idx: int, dataloader_idx: int) -> None:
pass
def on_train_end(self) -> None:
pass
def on_train_epoch_end(self, outputs) -> None:
# TODO 在训练周期结束时调用,并输出所有训练步骤的输出。
# 如果您需要对每个training_step的所有输出执行某些操作,请使用此方法。
self.scheduler.step()
def configure_optimizers(self):
self.optimizer = torch.optim.SGD(self.encoder.parameters() + self.decoder.parameters(),
lr=0.1)
self.scheduler = torch.optim.lr_scheduler.StepLR(self.optimizer, step_size=10, gamma=0.1)
return {
"optimizer": self.optimizer,
"lr_scheduler": {
"scheduler": self.scheduler,
"interval": "step", # 或 "step"
"frequency": 1, # 每1个interval调用一次
},
"monitor": "loss"
}
def training_step(self, batch, batch_idx):
# training_step defines the train loop.
# it is independent of forward
x, _ = batch
x = x.view(x.size(0), -1)
x_hat = self(x)
loss = nn.functional.mse_loss(x_hat, x)
# Logging to TensorBoard (if installed) by default
self.log("train_loss", loss)
return loss
def validation_step(self, val_batch, batch_idx):
x,_ = val_batch
x = x.view(x.size(0), -1)
x_hat = self(x)
loss = nn.functional.mse_loss(x_hat, x)
self.log("val_loss", loss)
def backward(self, loss: Tensor, optimizer: Optimizer, optimizer_idx: int, *args, **kwargs) -> None:
loss.backward()
def configure_optimizers(self):
optimizer = optim.Adam(self.parameters(), lr=1e-3)
return optimizer
def forward(self, x):
out = self.encoder(x)
out = self.decoder(out)
return out
# TODO init the autoencoder
encoder = Encoder()
decoder = Decoder()
autoencoder = LitAutoEncoder(encoder, decoder)
# setup data
train_dataset = MNIST(root='./data', download=True, transform=ToTensor())
val_dataset = MNIST(root='./data', download=True, transform=ToTensor())
train_loader = DataLoader(
dataset = train_dataset,
batch_size = 4
)
val_loader = DataLoader(
dataset = val_dataset,
batch_size = 4
)
#TODO 第一点 保存模型
save_callback = L.callbacks.ModelCheckpoint(
monitor='val_loss',#TODO 监控的指标为平均绝对误差最小的,这一点和on_validation_epoch_end日志记录的指标是呼应的
save_top_k=1, #TODO 这里的1,表示保存的模型中,只保存前4个最好结果模型权重文件
mode='min',#TODO 表示保存当前误差最小的模型
filename='{epoch}-{val_mae:.2f}'#TODO 保存模型格式
)
#TODO 早停机制
early_stopping = L.callbacks.EarlyStopping(
monitor='val_loss',
min_delta=0.1,
patience=5,
verbose=True,#TODO 冗长模式
mode='min'
)
# train the model (hint: here are some helpful Trainer arguments for rapid idea iteration)
logger_ten = L.loggers.TensorBoardLogger("lightning_logs", name="mnist")
logger_mlf = L.loggers.MLFlowLogger(experiment_name='mnist')
#TODO 以yaml和CSV格式记录到本地文件系统。
logger_csv = L.loggers.CSVLogger(save_dir="save path")
logger_comet = L.loggers.CometLogger(api_key="")
logger_wand = L.loggers.WandbLogger(name="mnist")
logger_ = L.loggers.NeptuneLogger()
trainer = L.Trainer(
limit_train_batches=100,
max_epochs=10,
callbacks=[save_callback],
val_check_interval=5
)
trainer.fit(
model=autoencoder,
train_dataloader=train_loader,
val_dataloaders=val_loader
)
# TODO 加载模型 load checkpoint
checkpoint = r"D:\conda3\Transfer_Learning\PyTorchLighting\lightning_logs\version_0\checkpoints\epoch=9-step=999.ckpt"
autoencoder = LitAutoEncoder.load_from_checkpoint(
checkpoint,
encoder=encoder,
decoder=decoder
)
# TODO 选择编码器 choose your trained nn.Module
encoder = autoencoder.encoder
encoder.eval()
# TODO 初始化一张图像 embed 4 fake images!
fake_image_batch = torch.rand(4, 28 * 28, device=autoencoder.device)
embeddings = encoder(fake_image_batch)
print("⚡" * 20, "\nPredictions (4 image embeddings):\n", embeddings, "\n", "⚡" * 20)训练完成之后就会默认生成日志文件lightning_logs,在终端输入以下命令:
tensorboard --logdir=lightning_logs/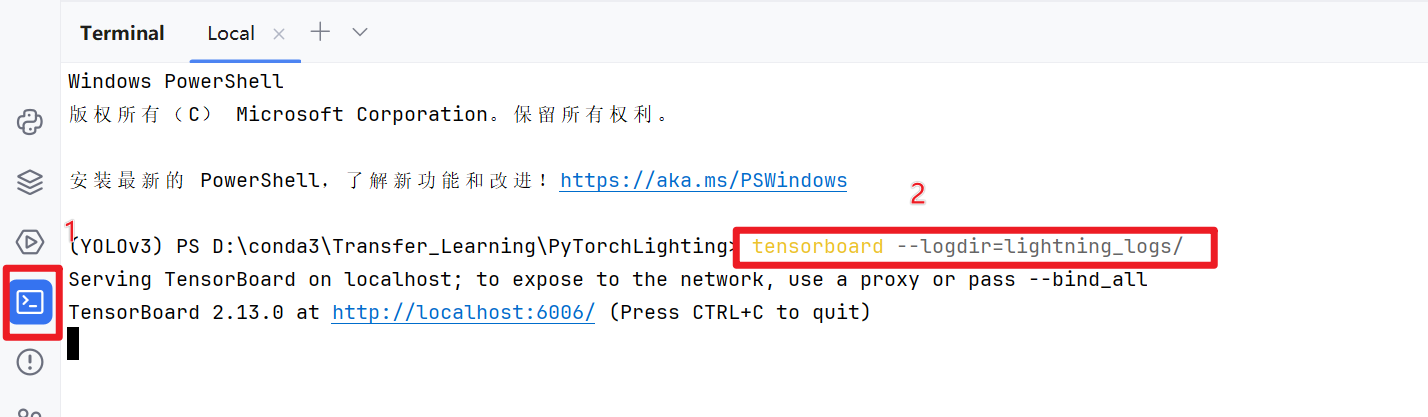
九 图像分割和目标检测案例讲解
PyTorch加载预训练目标检测模型实现物体检测,同时将预训练模型转换为ONNX模型文件(过程详解)
FCN图像分割和QT 6.6.0 加载分割FCN_Resnet50.ONNX模型文件进行图像分割(过程详解)
图像分割
https://lightning.ai/lightning-ai/studios/image-segmentation-with-pytorch-lightning?section=featured
加载VOC2012数据集,文件目录结构如下:
<root>
VOCdevkit
└── VOC2012
├── Annotations
├── ImageSets
│ ├── Action
│ ├── Layout
│ ├── Main
│ └── Segmentation
├── JPEGImages
├── SegmentationClass
└── SegmentationObject数据集呢?大家直接可以到官网下载即可。
代码下载:https://github.com/KeepTryingTo/DeepLearning/tree/main/pytorch_lightning
目标检测
https://lightning.ai/lightning-ai/studios/object-detection-with-pytorch-lightning?section=featured
数据集下载地址:
- WIDER_train.zip:https://huggingface.co/datasets/wider_face/resolve/main/data/WIDER_train.zip
- WIDER_val.zip:https://huggingface.co/datasets/wider_face/resolve/main/data/WIDER_val.zip
- wider_face_split.zip:
- https://huggingface.co/datasets/wider_face/resolve/main/data/wider_face_split.zip
- WIDER_test: https://drive.google.com/file/d/1HIfDbVEWKmsYKJZm4lchTBDLW5N7dY5T/view?usp=sharing
文件结构:
<root>
└── widerface
├── wider_face_split ('wider_face_split.zip' if compressed)
├── WIDER_train ('WIDER_train.zip' if compressed)
├── WIDER_val ('WIDER_val.zip' if compressed)
└── WIDER_test ('WIDER_test.zip' if compressed)代码下载:https://github.com/KeepTryingTo/DeepLearning/tree/main/pytorch_lightning



















 800
800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









