






视频讲解:论文以及代码详解
论文下载地址:https://arxiv.org/pdf/2211.01335v3.pdf
代码下载地址:https://github.com/ofa-sys/chinese-clip
论文CrowdCLIP(基于CLIP的无监督人群计数模型)详解(PyTorch,Pytorch_Lighting)
Reference-less Counting,Zero-shot Counting,Few-shot Counting,单域泛化以及域自适应之间的区别?
论文CLIP-Count(基于文本指导的零样本目标计数)详解(PyTorch)
虽然基于“图像-英文”的CLIP在很多下游任务中得到广泛的应用,但是毕竟是国外(OpenAi)公司做出来的,因此如果直接将CLIP应用到“图像-中文”上的话效果比较差,为了能更好的应用中文的图文检索其实是非常好的,针对中文训练一个Chinese-CLIP。虽然Chinese-CLIP很大程度上还是基于CLIP来做的,但是其中涉及的知识点还是应该讲一下的,具体做了什么以及源码训练以及模型是具体怎么实现的,这也很重要。了解Chinese-CLIP对于后期的应用到自己的任务具有很大的优势。

目录
一 提出目的和方法
提出目的
视觉-语言基础模型的巨大成功推动了计算机视觉与多模态表征学习的研究与应用。然而,如何将此类基础模型有效迁移至语言特定场景仍存在挑战。
提出方法
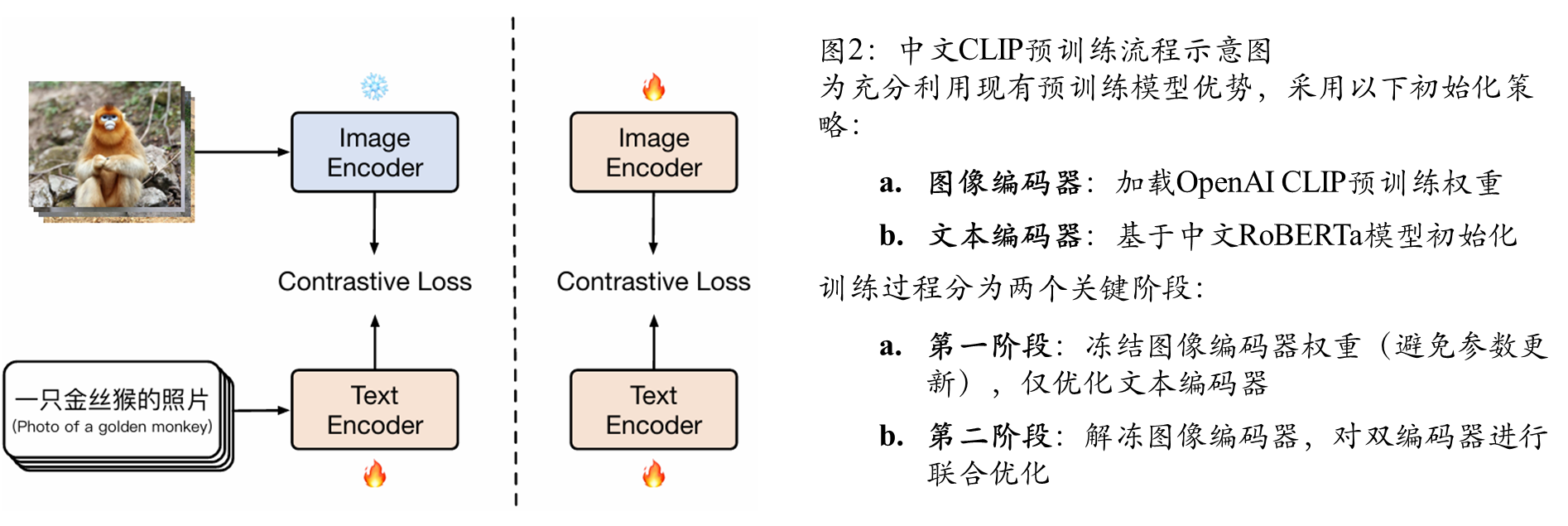
提出采用两阶段预训练方法的中文CLIP模型:第一阶段通过锁定图像调优(locked-image tuning)训练模型,第二阶段进行对比调优(contrastive tuning)。具体而言,我们开发了参数量从7700万至9.58亿不等的5个规模的中文CLIP模型,并在自主构建的大规模中文图文对数据集上进行预训练。
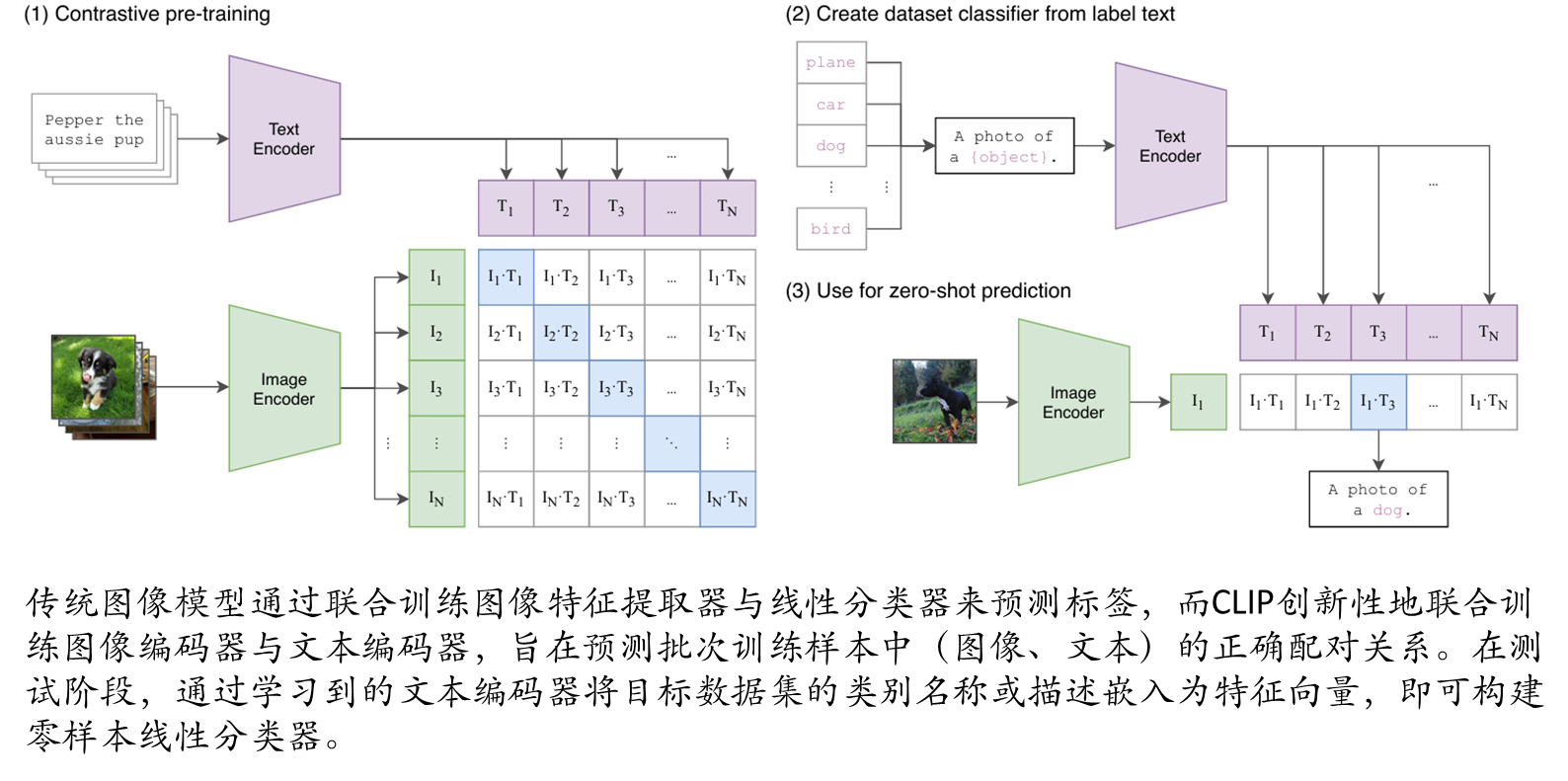
二 回顾CLIP


| 特性 | 传统模型 | CLIP |
| 训练目标 | 单模态监督学习 | 跨模态自监督对比学习 |
| 数据依赖 | 需要人工标注 | 纯自然语言监督(无标注成本) |
| 迁移能力 | 需微调适配新任务 | 零样本直接迁移 |
| 模态扩展性 | 单一模态 | 原生支持视觉-语言协同 |
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
跨模态挑战
跨模态预训练模型向其他语言的迁移仍存在多重挑战。首要关键在于:模型必须学习目标语言原生视觉-语言数据的分布特性。尽管CLIP在多数场景中展现出强大基础能力,但发现,即便是结合机器翻译的CLIP版本,在中文原生跨模态检索基准测试中仍表现欠佳。
三 方法
本文认为双编码器必须学习语言原生的视觉-文本数据分布是取得突破的关键。其次,现有中文多模态预训练方法的性能受制于多重因素:从头预训练需要构建类似Web Image Text(WIT)的大规模高质量中文图文对数据集。虽然通过CLIP初始化与锁定图像调优(Locked-Image Tuning)可实现快速迁移,但视觉编码器仍难以学习语言特定域的图像特征。
提出中文CLIP——基于公开中文图文对数据预训练的语言专用视觉-语言基础模型。在架构上保持与OpenAI CLIP的一致性,但创新性地开发了两阶段预训练方法:
该方案使模型既能继承基础模型的预训练优势,又能有效适应中文数据特性。
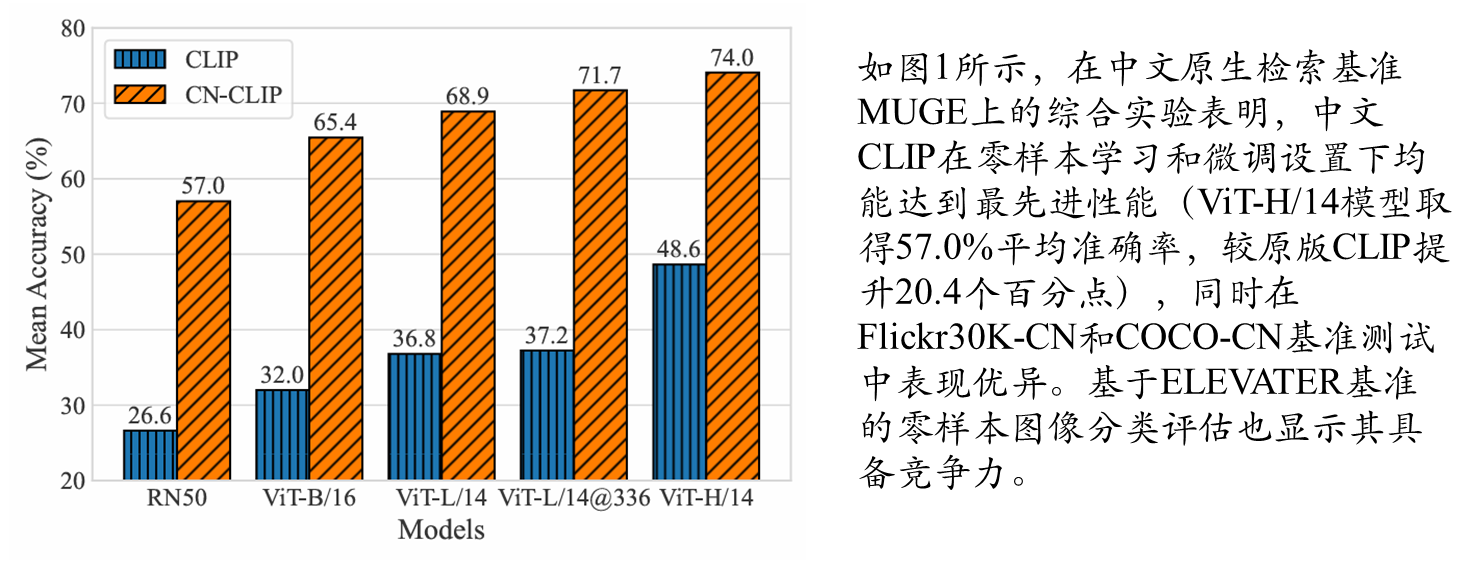
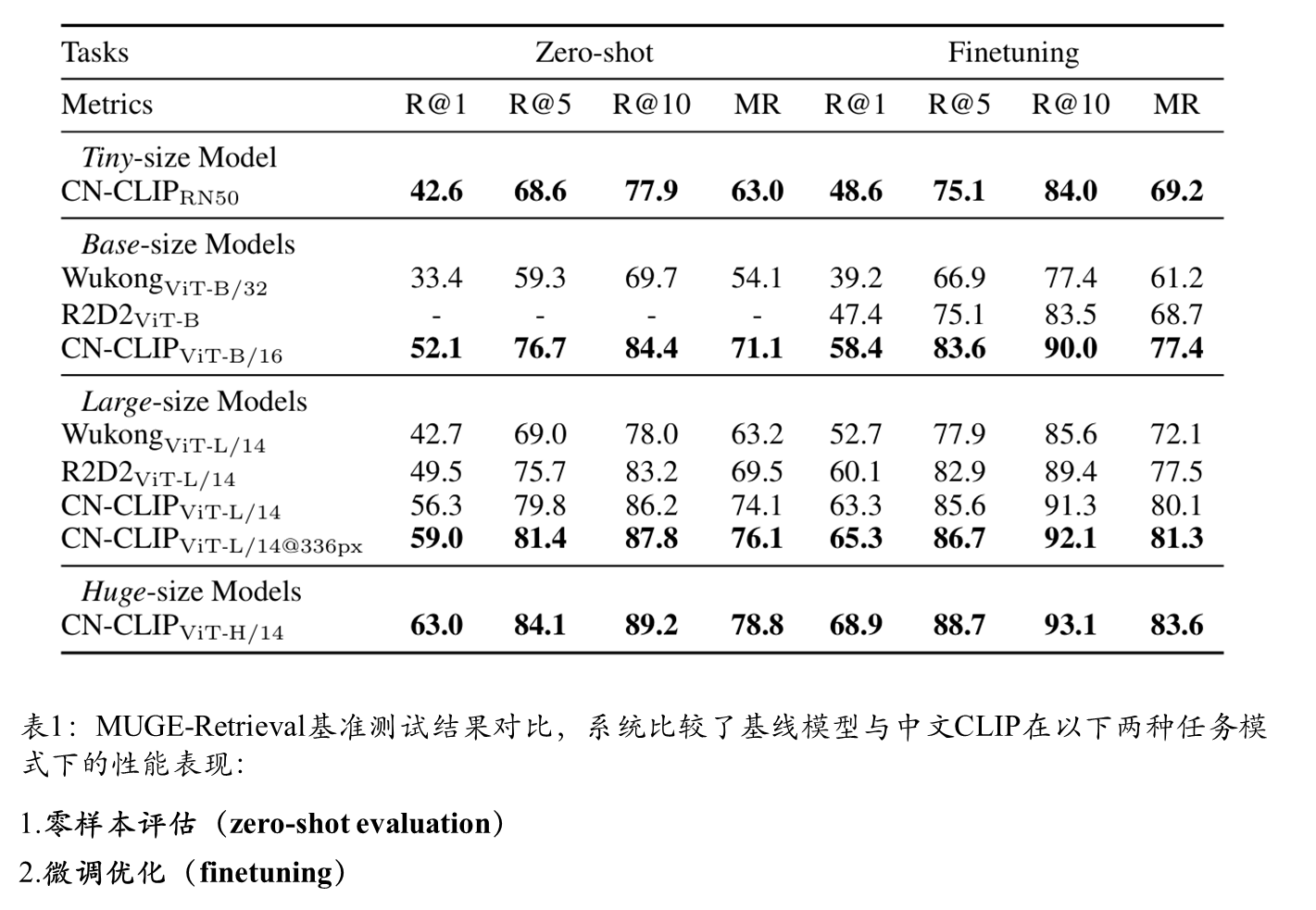
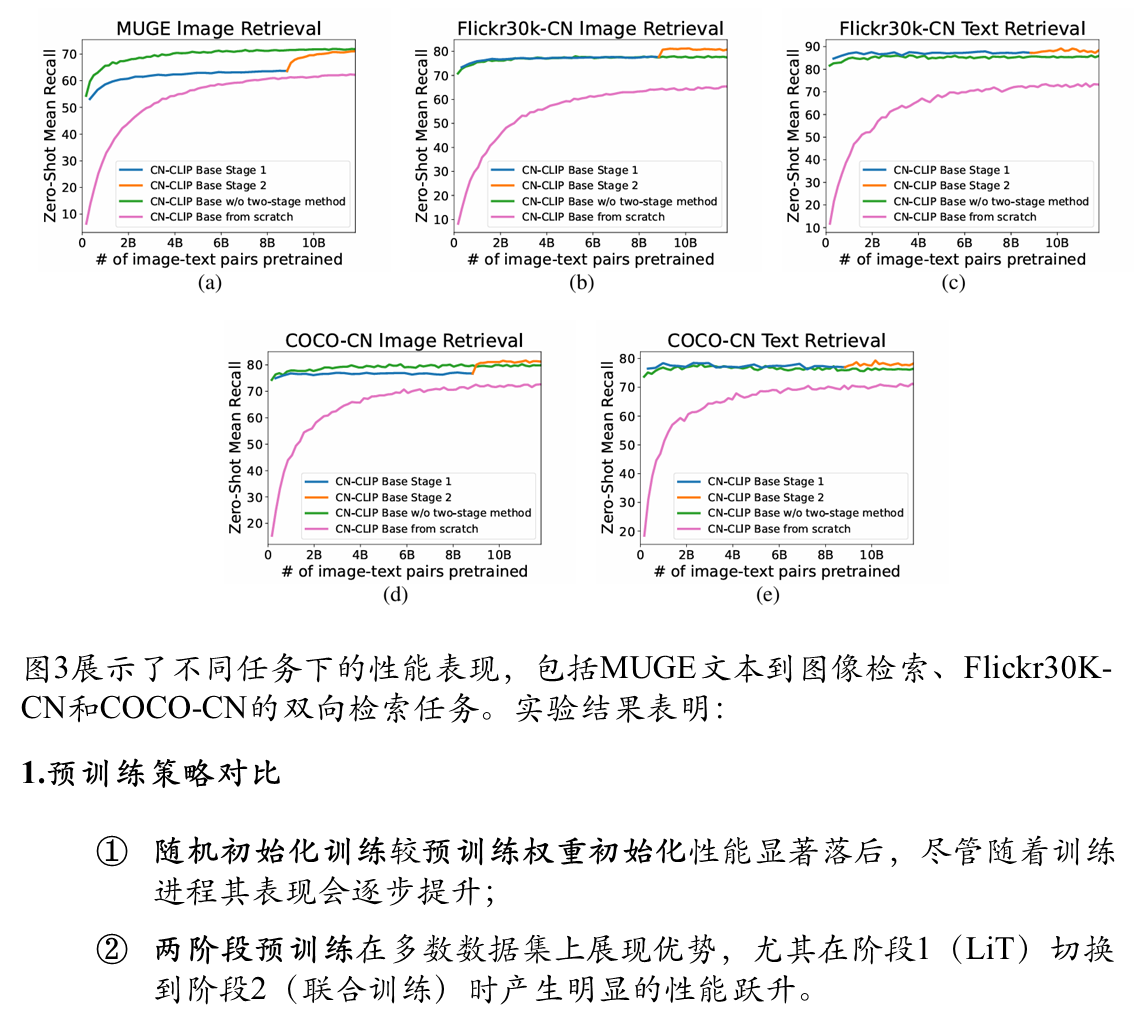
在MUGE、Flickr30K-CN和COCO-CN三个中文跨模态检索数据集上的实验表明:
数据预处理
成功关键要素在于预训练数据规模,至于数据的质量以及规模是不是模型性能的上限这个不十分清楚,但是数据的规模和质量一定是成功的关键。CLIP实验表明,扩大数据量并延长训练周期能持续提升零样本学习性能。今年最新推出的多模态预训练模型——悟空与R2D2分别使用1亿公开图文对和2.5亿内部数据(仅发布2300万子集)进行训练。为便于复现,我们致力于基于公开数据预训练中文CLIP,重点收集以下高质量数据源:
最终构建约2亿规模的图文对预训练数据集,数据清洗流程包括:
预训练方法
import torch
from PIL import Image
import cn_clip.clip as clip
from cn_clip.clip import load_from_name, available_models
print("Available models:", available_models())
# Available models: ['ViT-B-16', 'ViT-L-14', 'ViT-L-14-336', 'ViT-H-14', 'RN50']
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = load_from_name("ViT-B-16", device=device, download_root='./')
model.eval()
image = preprocess(Image.open("examples/pokemon.jpeg")).unsqueeze(0).to(device)
text = clip.tokenize(["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
# 对特征进行归一化,请使用归一化后的图文特征用于下游任务
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
logits_per_image, logits_per_text = model.get_similarity(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # [[1.268734e-03 5.436878e-02 6.795761e-04 9.436829e-01]]拓展(值得看一下)
请问这两行代码之间的区别 ?
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logit_scale * text_features @ image_features.t()| 计算式 | 维度变换 | 物理意义 |
|---|---|---|
logits_per_image = logit_scale * image_features @ text_features.t() | (B,d) @ (d,B) → (B,B) | 每张图像与所有文本的相似度 |
logits_per_text = logit_scale * text_features @ image_features.t() | (B,d) @ (d,B) → (B,B) | 每个文本与所有图像的相似度 |
logits_per_image:以图像为中心,计算每张图像与整个文本集的匹配程度logits_per_text:以文本为中心,计算每个文本与整个图像集的关联强度
# 图像检索任务(文搜图)使用:
text_query_similarity = logits_per_text[query_id] # 获取特定文本对所有图像的得分
# 文本检索任务(图搜文)使用:
image_query_similarity = logits_per_image[query_id] # 获取特定图像对所有文本的得分四 综合实验对比
图文检索
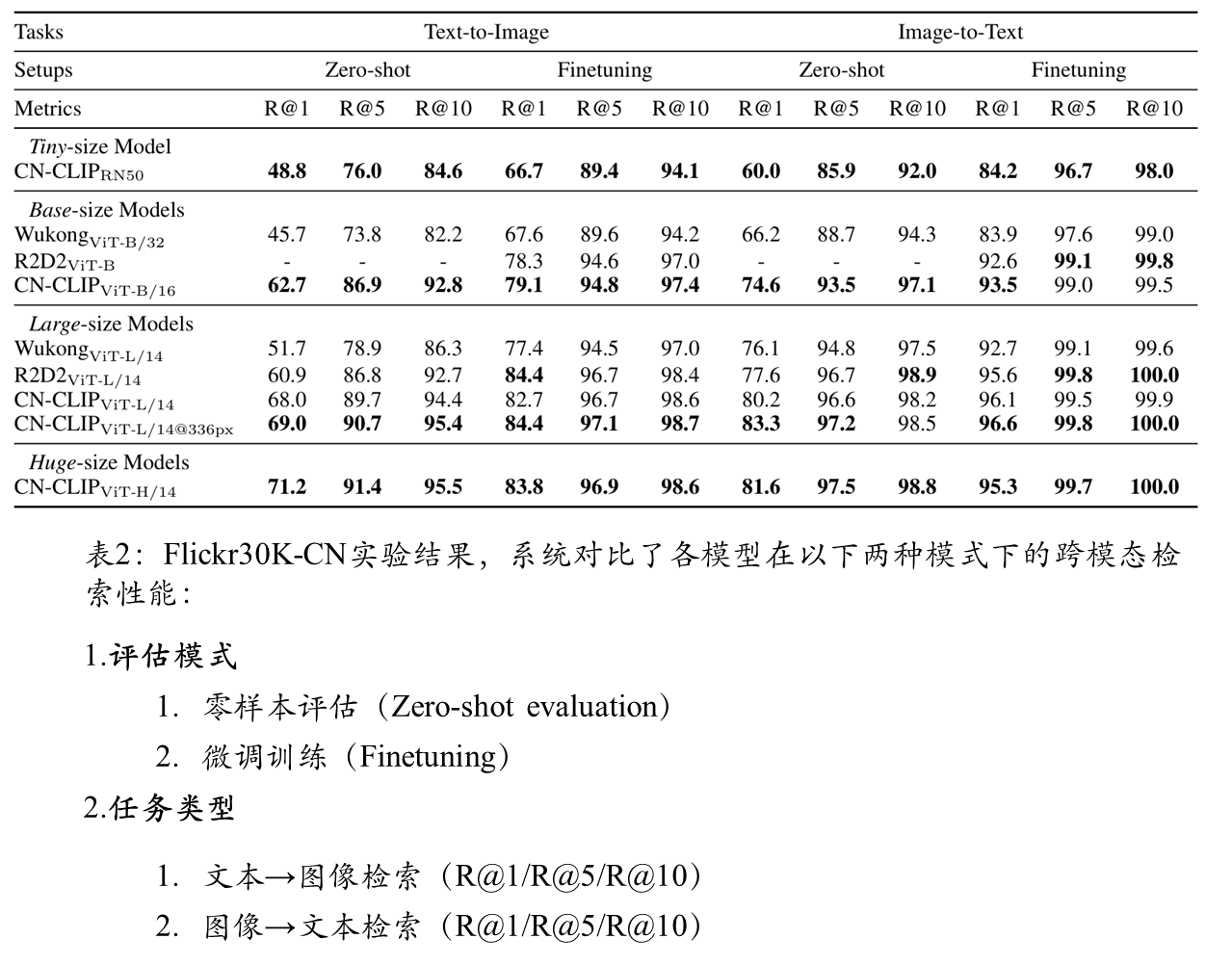
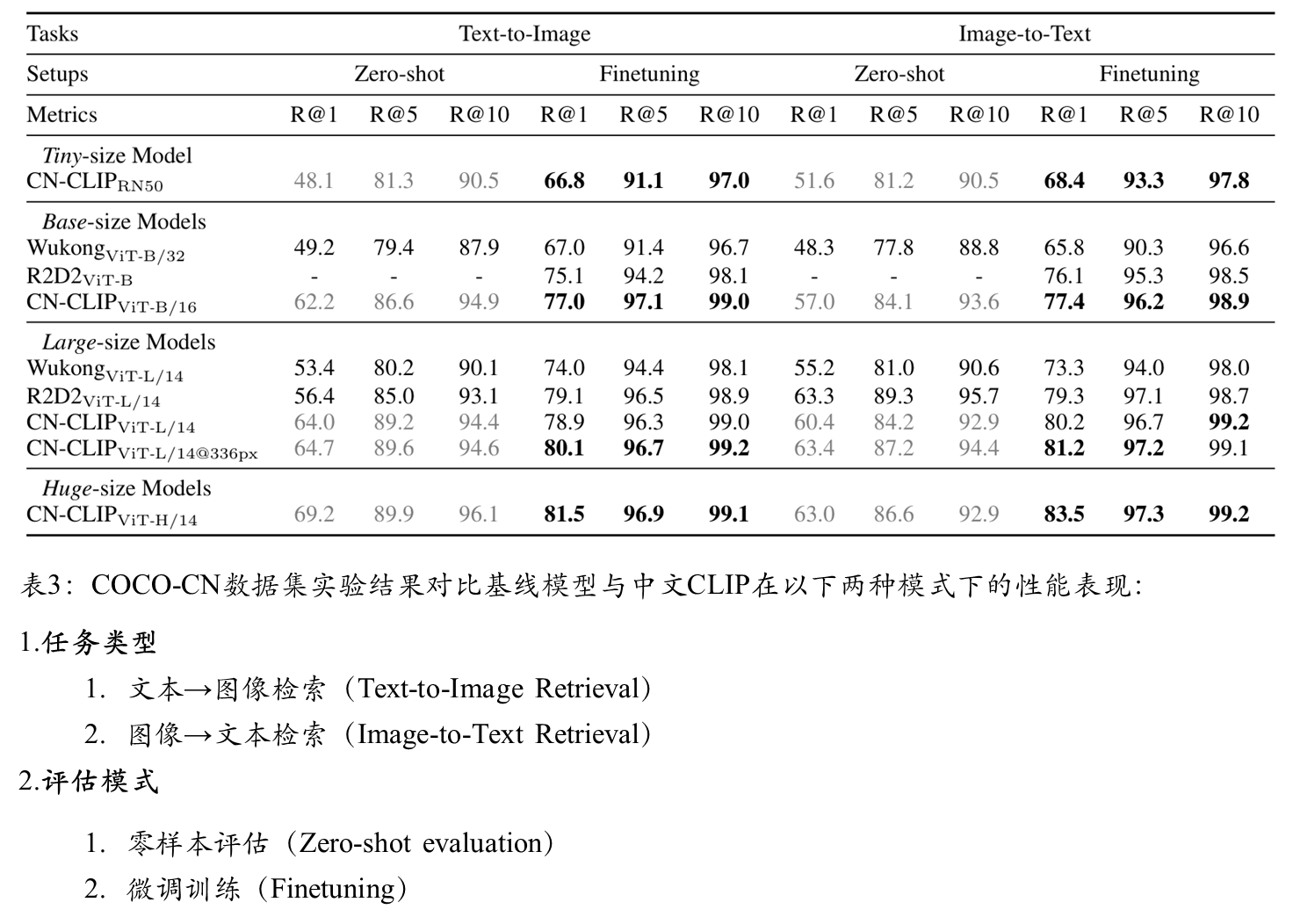
Zero-shot 图像分类
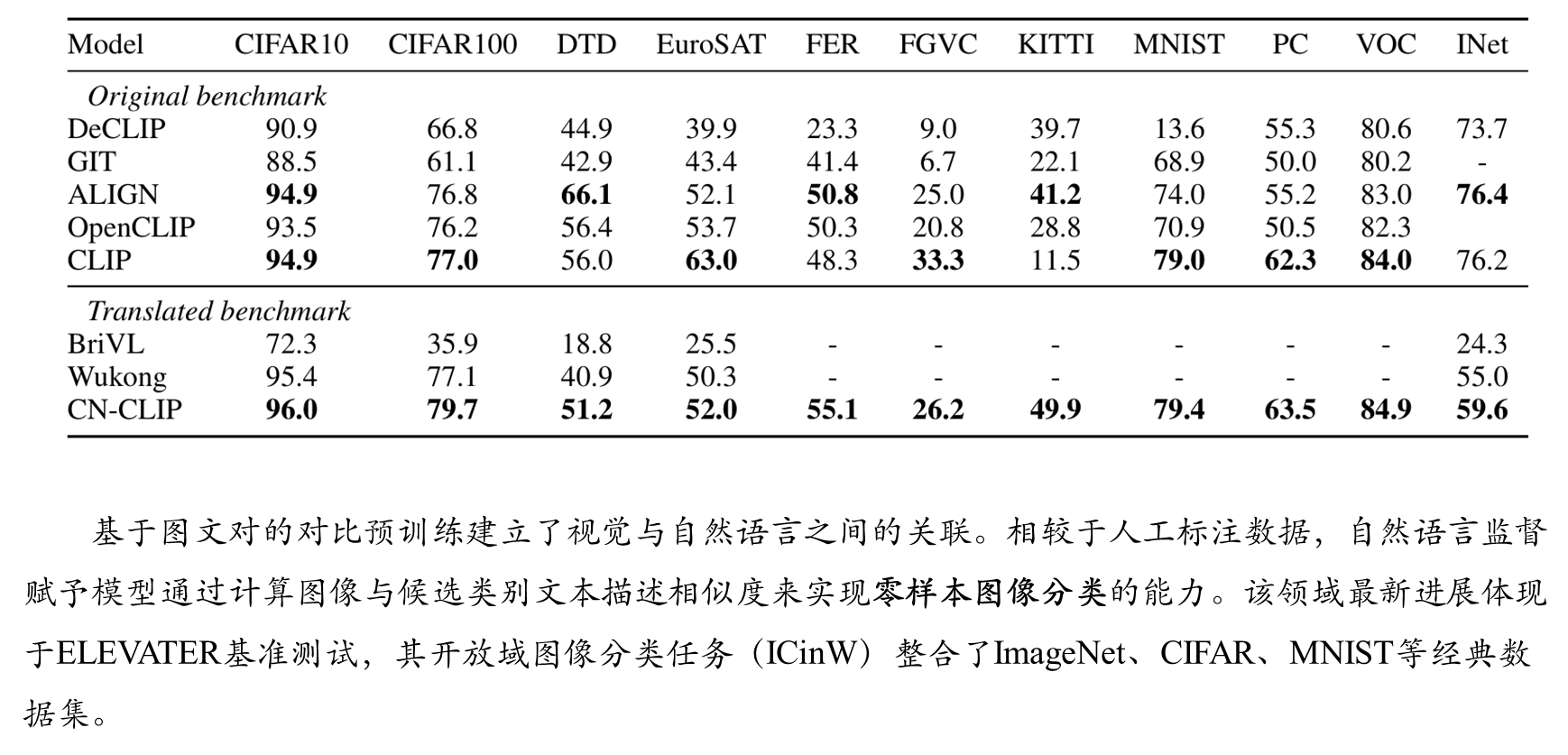
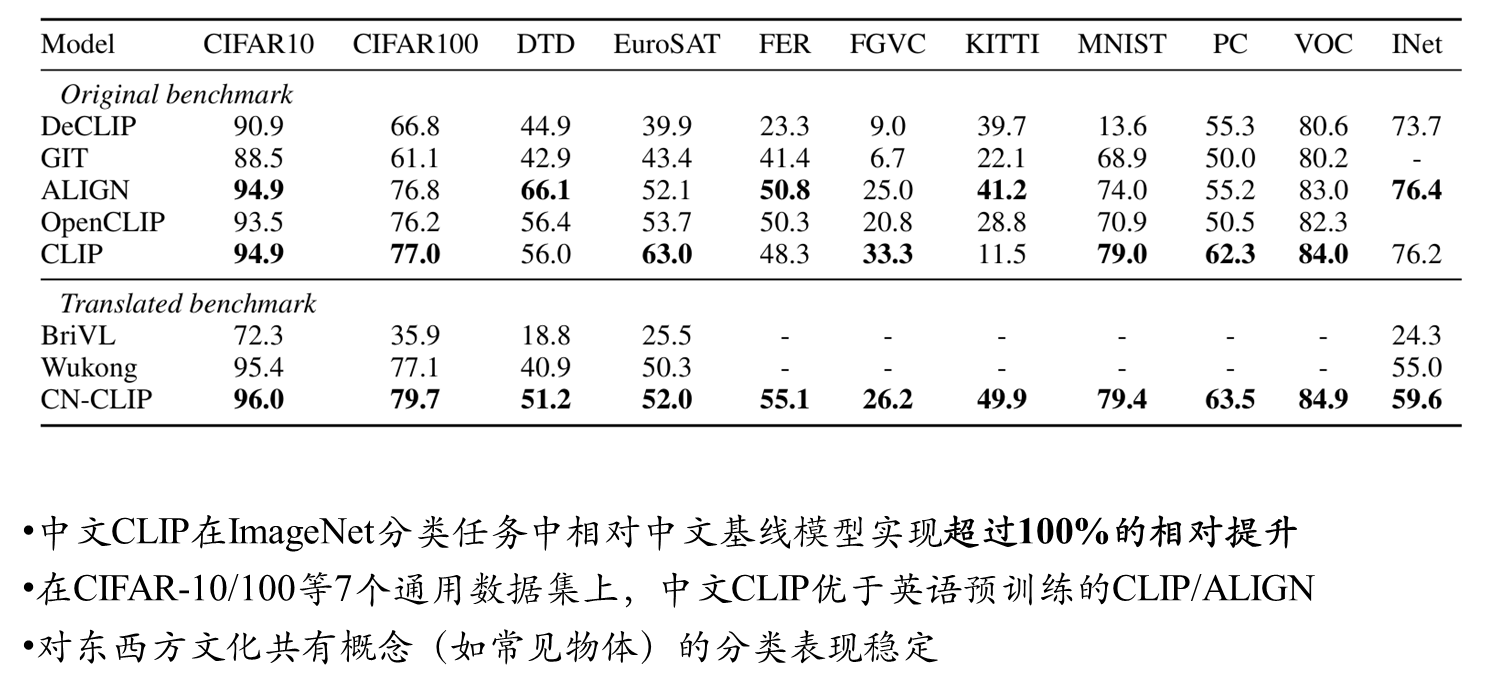
进一步分析
典型案例 :飞机分类任务中,采用航空领域知识设计的提示词(如 " 标签,一架客机的照片 " 、 " 标签,战斗机的特写图像 " )将准确率从 13.8 提升至 16.0
通过 KITTI-Distance 和 PatchCamelyon 数据集测试发现:
∙ KITTI-Distance 任务中,将标签 "others" 改为 "no cars" 导致准确率下降 48.1% ( 49.9→25.9 )
∙ PatchCamelyon 任务中, "no green block in the middle" 表述使准确率从 63.5 降至 50.2
五 附录部分
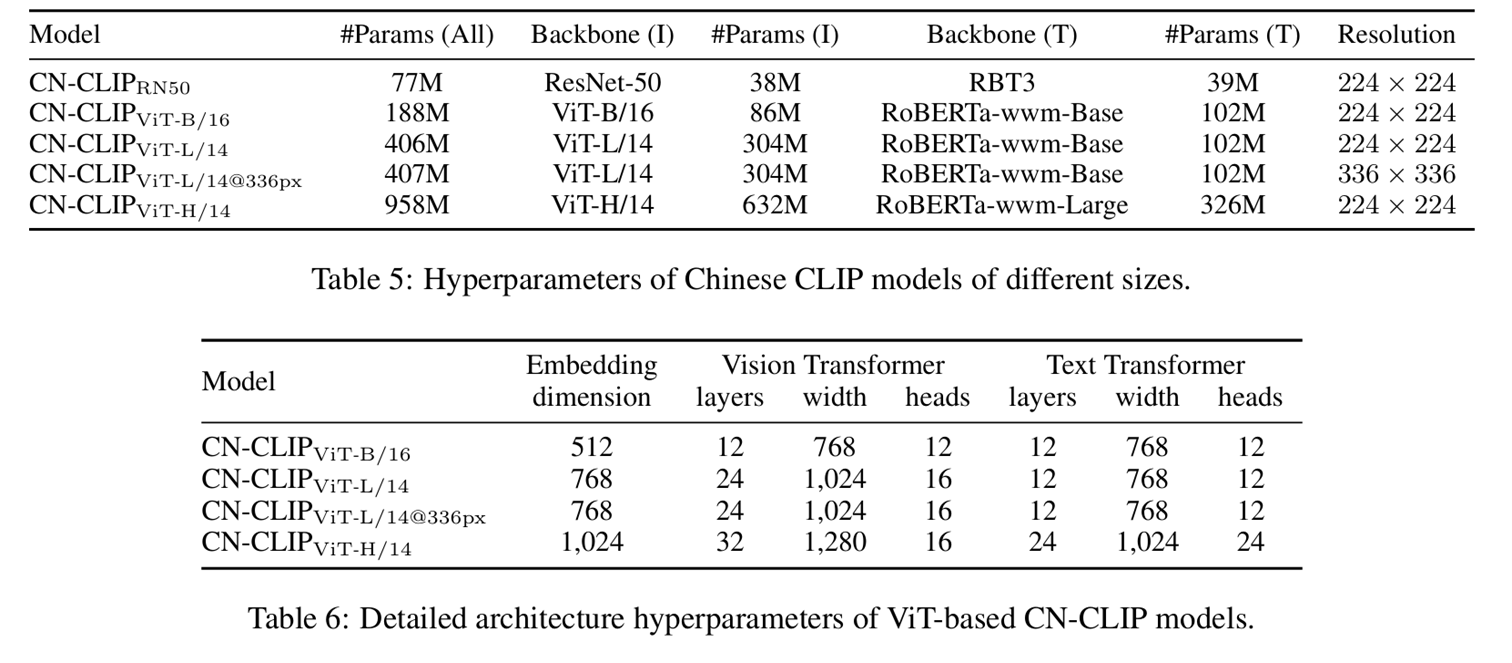

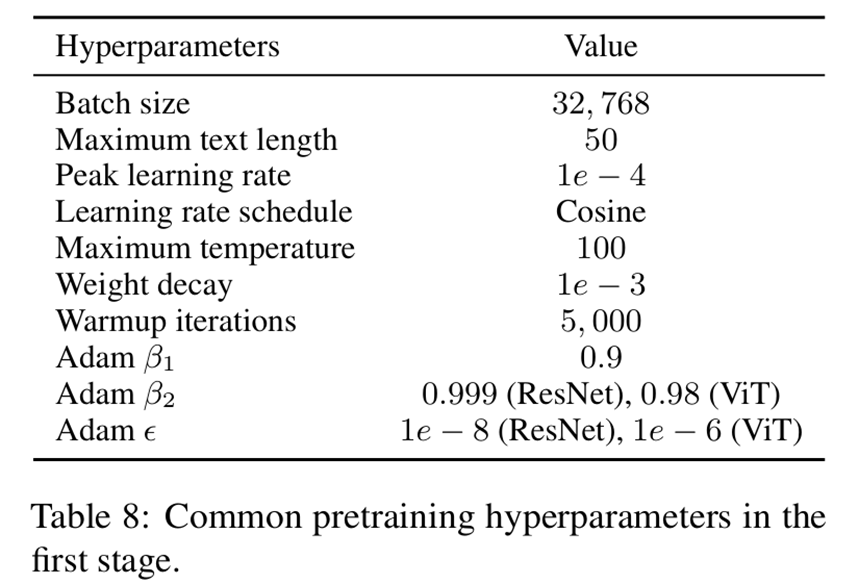
CN-CLIP预训练技术细节
初始化策略



















 3555
3555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









