



CLIP 模型架起了文本和图像的桥梁,但实际上很少有人会用它来进行文本检索,因为CLIP的文本编码器无法有效的对长文本进行语义建模。
为了解决这一问题,我们推出了 Jina CLIP v1,一个增强版的 OpenAI CLIP 模型,擅长文本-文本、文本-图像、图像-文本、图像-图像四个方向的检索。从现在起,你的 CLIP 模型不仅是图像检索器,更是强大的文本检索器。
在构建多模态 RAG 应用时,你不再需要在不同的向量模型之间切换,一个模型、两种模态、四个搜索方向 都交给 Jina CLIP v1。更关键的是,它还能够处理长达 8K 的输入长度。接下来,就让我们一探这款新模型的精华所在。
示例:用 Jina CLIP 实现零样本实时图像分类CLIP 模型架构
在 2021 年 1 月,OpenAI 推出了开创性的 CLIP 模型,其架构简洁却极具巧思:将一个文本编码器与一个图像编码器结合,在统一的向量空间中输出结果。CLIP 的文本向量与图像向量之间的距离,反映了两者语义关联的紧密程度。
CLIP 这一架构非常适用于跨模态检索和零样本分类任务,通过学习大量的图像和文本对,即使在没有针对性任务训练的情况下,也能理解并分类新的图像。
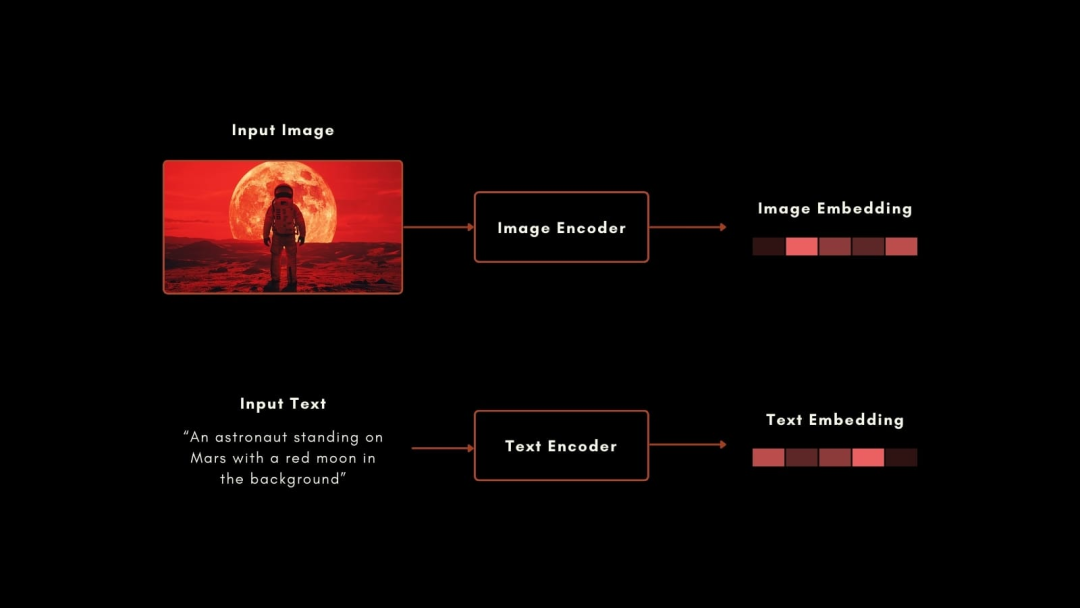
原始 CLIP 模型中的文本编码器是一个定制的神经网络,在图像编码器方面,OpenAI 则使用了一系列 ResNet 和 ViT 模型,再用图像描述进行训练,以生成相似的图像-文本向量。
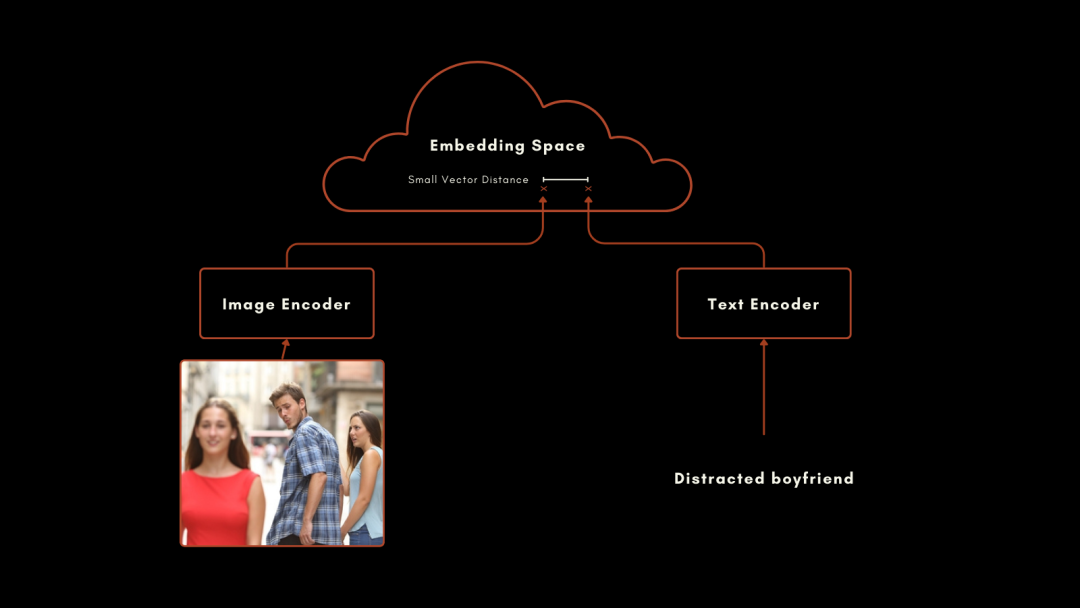
这种方法非常有效,尤其是在零样本分类中的表现。举个例子,即使训练数据中没有标注宇航员的图像,CLIP 仍能凭借对文本和图像相关概念的理解,准确识别宇航员的图片。
然而,OpenAI 的 CLIP 也存在两大短板:
1. 文本输入容量非常有限。最多仅支持 77 个 token 的输入,根据 LongCLIP 的实验,实际上其有效输入不超过 20 个 token。
2. 在纯文本检索中表现不佳。主要原因有两点:首先,CLIP 模型的训练目标是对齐文本和图像,没有针对纯文本检索进行专门优化。其次,CLIP 模型的训练数据主要由相对较短的文本组成,难以泛化到更广阔的文本检索场景。
因此,在大多数应用到 CLIP 模型的实际应用场景中,如果涉及到纯文本检索任务,就需要引入其他专用文本向量模型并行使用,使得 AI 框架的规模和复杂性增加了一倍。
Jina CLIP v1 直接解决了这些痛点,利用了近年来的进展,jina-clip-v1 为涉及所有文本和图像模态组合的任务提供了最先进的性能,一个模型支持两种模态、四个搜索方向,为用户带来前所未有的便捷性和高效性。
Jina CLIP v1 模型架构
Jina CLIP v1 沿用了 OpenAI CLIP 的双编码器架构:两个编码器共同训练,生成在同一向量空间中的输出结果。
在文本编码器方面,我们采用自身的向量模型所使用的 Jina BERT v2 架构,支持高达 8k token 的长文本输入,输出维度为 768,明显优于 CLIP,能够处理更长的文本,并生成更精确的向量。
在图像编码器方面,我们使用了北京智源人工智能研究院的最新模型 EVA-02(https://github.com/baaivision/EVA/tree/master/EVA-02),我们对一系列图像编码器进行了测评,在相似的预训练背景下进行跨模态测试,EVA-02 明显优于其他模型。它的模型大小也与 Jina BERT 架构相当,因此图像和文本处理任务的计算负担大致相同。经过我们的进一步训练,它在图像到图像及跨模态任务中展现出极佳表现。
通过这一全新组合,Jina CLIP v1 取得了以下重大进展:
在跨模态、纯文本、纯图像等所有场景下表现都很卓越,相比 CLIP 模型平均性能提升了 46%。
EVA-02 在图像-文本和纯图像任务中表现出色,Jina AI 的额外训练进一步提升了其纯图像任务的表现。
支持更长的文本输入,最高支持 8k token 输入,可与丰富语义上下文相关联。
Jina CLIP 即使在非跨模态场景中也有出色表现,可以大幅节省用户使用时的空间、计算、代码维护和复杂度。

Jina CLIP v1 在性能上的出色表现,归因于我们创新性的三阶段训练流程。前面提到了 CLIP 模型在纯文本场景下表现不佳的主要原因:
CLIP 专注于捕捉跨模态(图像和文本)的语义关联,对于单个模态(纯文本)之间的细粒度语义建模能力相对较弱。
CLIP 使用的训练数据主要来自网络上的图像-文本对,相比于大规模语料库,训练数据在覆盖面和多样性方面存在局限,这导致模型难以泛化到更广阔的文本检索场景。
因此,我们有针对性地设计了训练方案来改善这一问题,通过两个任务共同优化、以及长文本单项优化的方式进行训练,具体分为三个步骤:
三阶段联合训练流程
第一阶段:对齐图像和文本向量
首先,我们使用带描述的图像数据来对齐图像和文本向量,辅助文本对来进行协同训练。这种训练方法使两模态互相促进,提升短文本的检索能力,同时大幅提升跨模态检索性能。
第二阶段:利用合成数据进行长文本优化
接着,我们引入了由 AI 模型生成的合成数据,主要是长文本图像描述数据,通过增加文本序列长度(至 512)来训练模型。这一阶段重点提升了模型对于长文本的关注和处理能力,进一步优化了文本检索的性能。
第三阶段:难负样本学习
在最后阶段,我们使用包含难负样本的文本三元组,进一步改进文本编码器,学习区分相关文本与不相关文本。同时,为保持文本-图像对齐,我们继续对长图像描述进行训练。此阶段显著提升了纯文本性能,模型的图像-文本的跨模态检索能力则保持稳定。
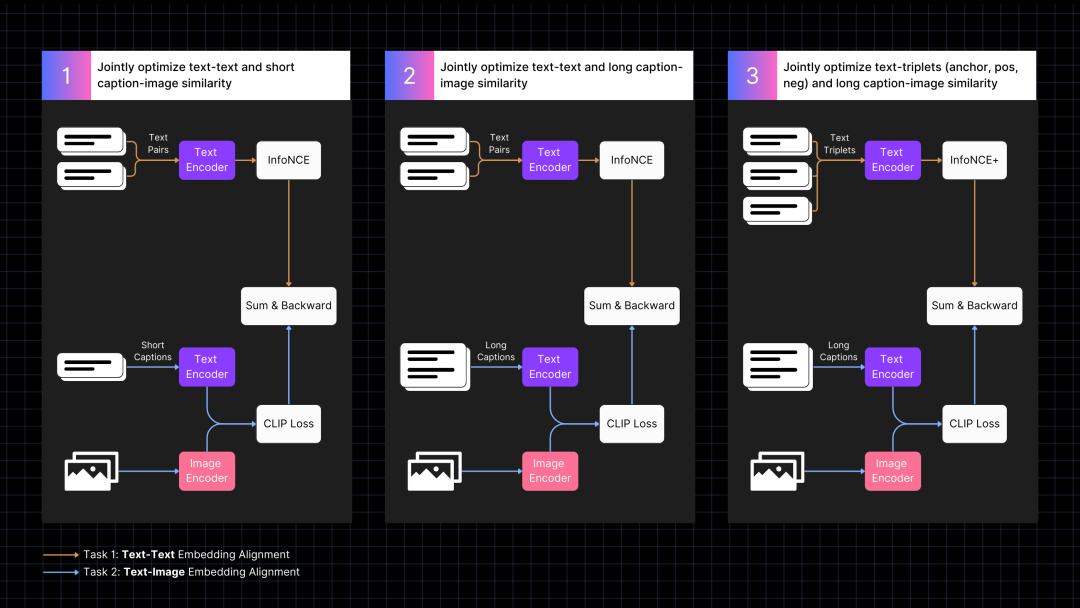
通过上述策略,我们实现了文本和图像两种模态的共同进化,使模型在所有检索场景中均能发挥出色表现。有关训练和模型架构的详细信息,请参阅我们的论文:《Jina CLIP: Your CLIP Model Is Also Your Text Retriever》https://arxiv.org/abs/2405.20204。
多模态向量的新前沿
我们评估了 Jina CLIP v1 在纯文本、纯图像以及跨模态任务中的表现。我们使用 MTEB 检索基准来评估其文本性能;在纯图像任务中,采用 CIFAR-100 基准测试;在跨模态任务方面,选择了包含在 CLIP 基准中的 Flickr8k、Flickr30K 和 MSCOCO Captions 数据集进行评估。
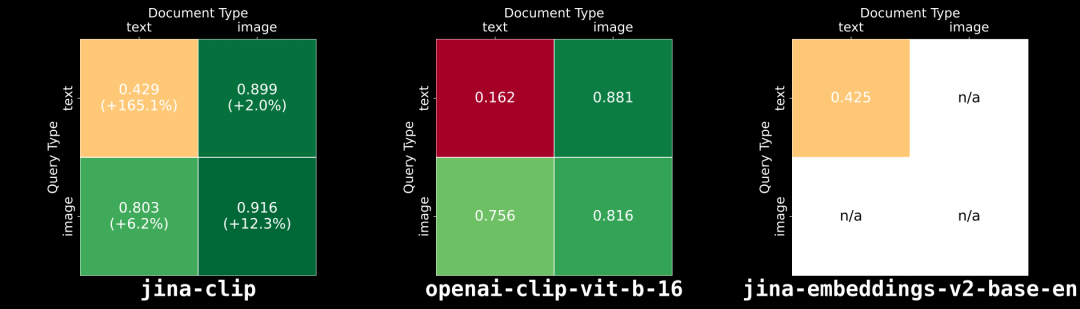
结果如上图所示:jina-clip-v1 在所有类别中均优于 OpenAI 的原始 CLIP,尤其是在纯文本提升了 165.1%,纯图像检索方面提升了 12.3%,平均来看性能提升了 46%。
如何上手 API
您可以轻松地通过 Jina Embeddings API 将 Jina CLIP v1 集成到您的应用中。
下面的代码示例展示了如何通过 Python 中的 requests 包调用 API 来获取文本和图像的向量,它将文本字符串和图像的 URL 传递给 Jina AI 服务器,并返回两者的编码。
☝️ 记得将 <YOUR_JINA_AI_API_KEY> 替换为已激活的 Jina API 密钥。你可以在 Jina Embeddings 网页获取包含一百万免费 tokens 的试用密钥。
import requests
import numpy as np
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
url = 'https://api.jina.ai/v1/embeddings'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer <YOUR_JINA_AI_API_KEY>'
}
data = {
'input': [
{"text": "Bridge close-shot"},
{"url": "https://fastly.picsum.photos/id/84/1280/848.jpg?hmac=YFRYDI4UsfbeTzI8ZakNOR98wVU7a-9a2tGF542539s"}],
'model': 'jina-clip-v1',
'encoding_type': 'float'
}
response = requests.post(url, headers=headers, json=data)
sim = cos_sim(np.array(response.json()['data'][0]['embedding']), np.array(response.json()['data'][1]['embedding']))
print(f"Cosine text<->image: {sim}")主流 LLM 框架集成
Jina CLIP v1 已与 LlamaIndex 和 LangChain 等热门框架集成:
在 LlamaIndex 中: 通过 MultimodalEmbedding 基类使用 JinaEmbedding,并调用 get_image_embeddings 或 get_text_embeddings。
在 LangChain 中: 使用 JinaEmbeddings,并调用 embed_images 或 embed_documents。
定价
文本和图像输入的费用按 token 消耗计算。
对于英语文本,平均每个单词需要 1.1 个 token。
对于图像,则 224x224 像素块数量计算,每块 1,000 tokens,不足一块的按一块计算。
我们还为企业用户提供包含个性化咨询、定制解决方案、优先支持等增值服务。
在 Hugging Face 上开源
Jina AI 一直积极推动开源社区发展,因此,我们在 Hugging Face 上开源了 Jina CLIP v1 模型,采用 Apache 2.0 许可证,欢迎大家下载使用。
你可以在 Hugging Face 的 jina-clip-v1 模型页面上找到示例代码,用于在你自己的系统或云部署中下载并运行此模型。
jinaai/jina-clip-v1 · Hugging Face:https://huggingface.co/jinaai/jina-clip-v1
总结
作为我们在多模态向量检索的力作,Jina CLIP v1 性能显著超越了 OpenAI 的 CLIP,尤其在纯文本和纯图像检索任务中有显著改进。它成功克服了 CLIP 在单一模态建模方面的不足,真正实现了文本、图像两种模态的高效融合,统一了跨模态检索任务。
对于应用开发者来说,现在你只需部署一个模型实例,即可同时支持文本-文本、文本-图像、图像-文本和图像-图像四种检索方向,无需针对不同的检索任务分别使用专门的模型。显著降低了模型管理和部署的复杂度,减少了维护和计算开销。
由于资源限制,该模型目前仅支持英文文本。我们正努力扩展其对更多语言的支持。
有关 Jina CLIP v1 模型的更多信息,请访问我们的网站 https://jina.ai/embeddings。如需讨论具体用例和其他 Jina AI 产品,请通过小助手 jinaai01 与我们联系。


















 115
115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









