




目录
1 场景
后端完成项目部定的leakage power指标,但是在PTPX仿真动态功耗时,发现clcok tree动态功耗在block内部甚至整芯片中占比很大。公司项目部给出指标,希望大大降低clock tree动态功耗在整芯片功耗的占比。
首先我们先明白正常意义上的clock tree功耗包括从root点到寄存器CP端所有经过的cell的翻转功耗,包括clock 反相器/clock gate/其余clock逻辑cell/寄存器CP端的翻转功耗。
寄存器和clock逻辑cell是设计写好的,后端优化不了,所以只能从clock 反相器来优化,具体就是优化clock 反相器的个数和强度。
问题来了,为什么clock tree功耗会这么高呢?因为clock tree上的cell的翻转率远高于数据路径,并且clock 反相器DCCKND8/D12/D16等以及寄存器,本身的电流就大,功耗就高。
SDC create_clock创建 master clock点, create_generated_clock创建slave clock点。在CTS阶段,SDC转换为spec(时钟树规范文件)之后,create_clock创建的skew_group会包含create_generated_clock创建的skew_group,于是出现如下图所示的现象,所有slave clock点下面的寄存器都会被master clock所balance delay。
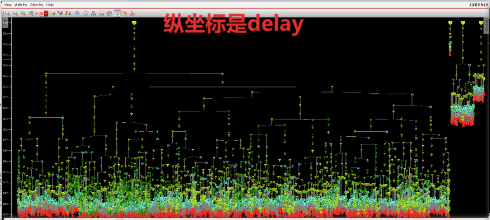
如图所示的时钟树完全可以满足timing要求,但是clock tree水分太多,包含了太多没有必要的clock 反相器cell。我们的目标是满足timing要求的情况下,去除水分,构建一个最少数量的clock cell的低功耗时钟树。
2 从芯片后端部门角度去构建低功耗clock tree
2.1 优化个数
方法核心:去除balance cell,又名去除兜圈子cell
方法特色:不用从物理版图下手,直接从clock debug窗口下手,通过修改spec完成
2.1.1 评估标准
1.balance cell数量和分布 **cdb** **cwb**(只要是包含*cwb* *cdb*的INV,一定是兜圈子cell,非传输cell)
2. clock cell数量
3. INV级数
4. latency
宗旨:latency尽量短
翻译:sinks该balance的balance,不该balance的INV级数/latancy尽量短,并且在应该balance的skew_groups中看能否继续优化关键路径长度2.1.2 方法
1. 观察:在clock tree debug窗口观察balance cell的分布(允许clock tree尾端也就是sinks前几级有分布,其余的都需观察分析)
2. 进一步观察:寻找关键路径(lantency最长但是无balance cell)
3. 优化:修改spec
1. 将关键路径的sinks点从skew_groups去除
&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 89
89





 到【灌水乐园】发言
到【灌水乐园】发言







