




在结构生物学的发展历史中,「结构决定功能」一度被视为近乎不可动摇的基本法则。无论是胰岛素的经典螺旋构象,还是血红蛋白的四聚体架构,都强化了一个共识:蛋白质要发挥生物学作用,必须拥有稳定的三维结构。
然而,内在无序蛋白(IDPs)及其内在无序区域(IDRs)的发现, 正不断重塑这一传统认知。它们在生理条件下并不形成固定结构,却深度参与信号转导、基因转录调控等核心过程,并与癌症、神经退行性疾病等重大人类疾病密切相关。
计算生物学研究进一步揭示,真核生物蛋白质组中约 30% 的氨基酸残基处于无序状态。这意味着,无序并非「异常」,而是生命体系的常态组成部分。然而,无序蛋白的高度动态性使其难以用传统实验技术稳定捕捉,也难以通过常规计算方法准确模拟其构象分布, 这也成为了该领域长期存在的技术瓶颈。
围绕这一挑战,英国蛋白质分析技术研发商 Peptone 公司、哥本哈根大学、英伟达、牛津大学、麻省理工学院、杜克大学等组成的联合团队,提出了两项关键突破。其一是 PeptoneBench 系统评估框架, 该框架整合 SAXS、NMR、RDC、PRE 等多源实验数据,并结合最大熵重加权等统计方法,实现了实验观测与理论预测的严格定量对照。其二是生成式模型 PepTron, 基于扩展后的合成 IDR 数据集训练,专门强化了对无序区域的建模能力,使其能够更好地捕捉无序蛋白的构象多样性。
研究团队利用 PeptoneBench 将 PepTron 与 AlphaFold2、Boltz2、BioEmu 等主流预测工具进行了系统对比,结果显示,PepTron 在有序与无序区域的预测上均展现出与实验结果高度一致的表现,达到了 SOTA 水平。基于这些进展,一个更准确、更贴近生物现实的「构象集合」结构预测框架正在形成,显著提升了人们对蛋白质在有序—无序全谱状态下的整体理解能力。
相关研究成果以「Advancing Protein Ensemble Predictions Across the Order–Disorder Continuum」为题,已发表预印本于 bioRxiv。

论文地址:
https://www.biorxiv.org/content/10.1101/2025.10.18.680935v1
关注公众号,后台回复「PepTron」获取完整 PDF
更多 AI 前沿论文:
https://hyper.ai/papers
PeptoneBench 与多源实验数据集的系统化构建
蛋白质数据库(PDB)是结构生物学最基础、最重要的公共资源,但在内在无序蛋白(IDPs)及其无序区域(IDRs)的覆盖上却存在明显结构缺口——仅约 3% 的条目被标注为无序, 而在人类蛋白质组中,此类无序区域的比例却高达 20–30%。
如下图所示,这种系统性偏斜使得大多数结构预测模型天然「偏爱」稳定构象,对动态无序状态的学习能力长期受限。为弥补这一不足,研究人员引入了如 IDRome 等补充性数据库,其无序占比高达约 77%, 可从统计分布上与 PDB 形成互补。然而,该数据库缺乏真实实验解析的结构数据,因而难以用作建模与评估的直接基准,其应用价值仍受到明显限制。

PDB、人类蛋白质组和 IDRome 数据集中预测的蛋白质无序分布
要突破上述数据瓶颈,第一步是建立可量化、可比较的无序程度指标。 该研究以蛋白质平均 G 评分为核心度量,其取值范围介于 0(完全有序)到 1(完全无序),基于 NMR 二级化学位移(CS)数据计算,可准确反映局部二级结构形成的倾向。对于缺乏实验 CS 数据的蛋白质,研究团队采用基于 TriZOD 训练的机器学习模型 ADOPT2 进行 G 评分预测,从而实现对整个有序–无序谱的统一量化。
在此基础上,团队进一步指出,仅依赖 PDB 的结构数据无法客观评估构象集合的质量,因此必须构建覆盖完整有序–无序范围的实验数据集。
为此,如下表所示,研究人员建立了 3 个互补的数据资源:PeptoneDB-CS(源于 BMRB 的 NMR 化学位移)、PeptoneDB-SAXS(来自 SASBDB 的 SAXS 图谱)以及 PeptoneDB-Integrative(整合多种正交实验数据的 IDP 专用集)。三类数据结构不同、信息互补,CS 揭示局部结构,SAXS 反映整体构象,Integrative 支持交叉验证。

研究构建的蛋白质数据集
基于这些数据,如下图所示,研究人员构建了 PeptoneBench 评估框架,用于量化预测构象集合与实验数据的一致性。 整个流程包括:构象集合标准化与预处理;通过正向模型将预测结构映射为可与实验对比的观测量;基于归一化 RMSE 进行一致性评分,并在全程纳入模型与实验的不确定性。最终结果以 RMSE–G 评分关系图展示,并通过 LOWESS 平滑与自举法估计误差,进一步综合为 PeptoneBench 汇总评分,形成可直接比较不同工具性能的量化标准。
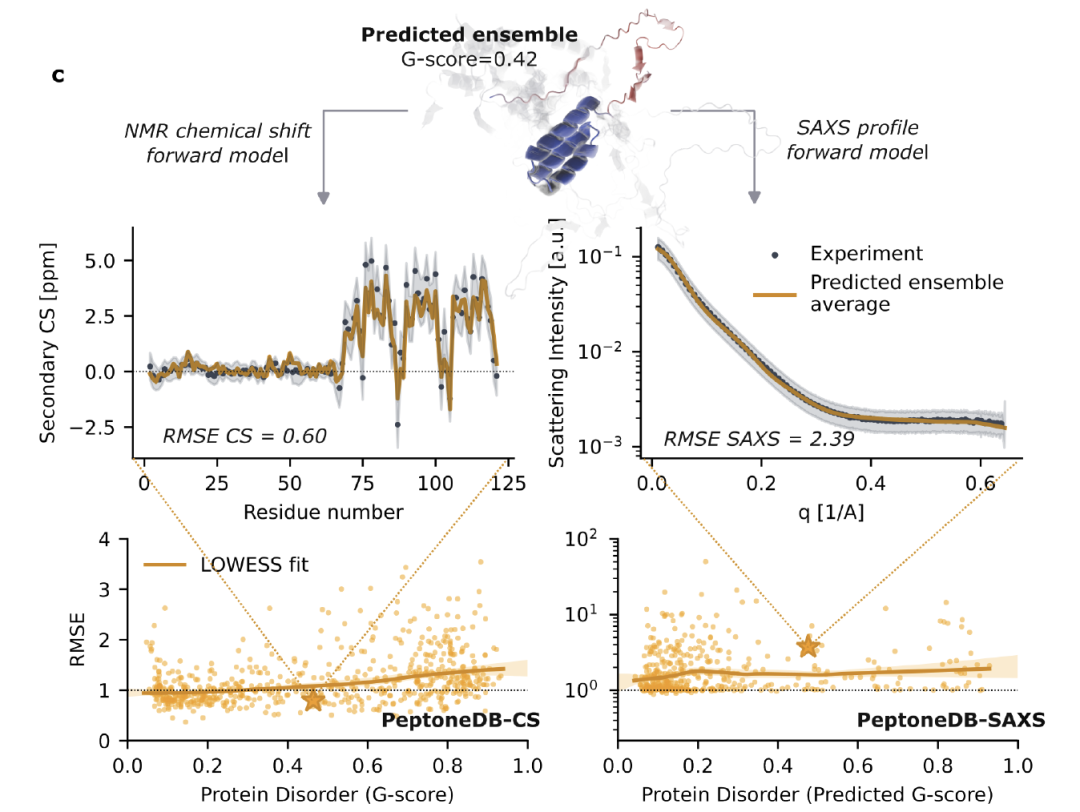
PeptoneBench 工作流程
值得特别强调的是,某些初始 RMSE 较高的构象集合,通过最大熵重加权后反而可能更接近实验分布。为避免将「错误的权重」误判为「缺失的构象」,PeptoneBench 同时报告重加权前后的 RMSE,以区分可修正的采样偏差与不可恢复的构象缺失。 这一策略对高度动态、对实验条件极其敏感的 IDP 尤为关键:只要生成模型能够覆盖足够丰富的构象空间,即便实验环境不同,也能通过重加权过程快速适配,从而显著提升预测结果的实用性与可靠性。
PepTron:兼顾有序与无序蛋白的构象生成模型
该研究提出的 PepTron 模型,是一款基于流匹配 ESMFlow 架构构建的蛋白质构象生成器,目标是覆盖从完全有序到高度无序的完整构象谱,生成既具物理合理性又具有结构多样性的构象集合。
在模型架构上,PepTron 以 ESMFlow 为基础,并在 NVIDIA BioNeMo 框架中实现以提升训练与推理效率。 模型集成了 cuEquivariance 三角注意力机制,并通过 BioNeMo 的 Modular Co-Design 子包支持流匹配功能。训练流程遵循 BioNeMo 的分布式最佳实践,结合多种并行策略和混合精度计算,因而能够在多 GPU 环境中稳定、高效地扩展。
值得强调的是,PepTron 在推理阶段不依赖多序列比对(MSA)或外部 ESM 权重,仅凭单一检查点即可生成完整构象集合,大幅简化了使用门槛。
针对无序区域实验结构数据稀缺的难题,研究团队基于 IDRome 构建了合成结构数据集 IDRome-o。为此,他们开发了基于片段组装的蛋白质结构生成工具 IDP-o,能够以极低成本大规模生成物理合理的 IDP 构象集合。 IDP-o 结合片段组装与分层链增长策略,从包含 2.14 亿结构的 AlphaFold 大型数据库中提取六残基片段,从而更准确地捕捉无序蛋白中短暂出现的螺旋结构。
需要说明的是,IDR-o 的目标并非模拟某一平衡分布,而是覆盖序列可能采样到的所有合理构象,因此其输出特别适用于后续的最大熵重加权,也可作为分子动力学模拟的高质量初始构象库。
为克服传统模型倾向预测稳定结构的偏差,如下图所示,PepTron 采用了「实验数据+合成数据」的混合训练策略: 先使用 PDB 中的实验解析结构进行预训练,再引入合成生成的无序蛋白集合进行混合微调,从而让模型充分学习有序与无序构象的连续分布。即使在计算资源受限条件下,这种策略仍显著提升了模型在各类蛋白上的预测性能。
在具体训练流程上,研究分为两个阶段: 在基础阶段以 ESMFold 权重为起点,利用 PDB 数据对流匹配模块进行再训练,并将序列长度裁剪范围扩展至 512 个残基;在混合微调阶段使用由 PDB 实验结构与 IDRome-o 合成数据构成的混合集合作为训练数据,对模型进行最终优化。这样的设计使 PepTron 能够打通有序—无序全谱,实现对蛋白质动态构象空间更全面、更真实的建模。
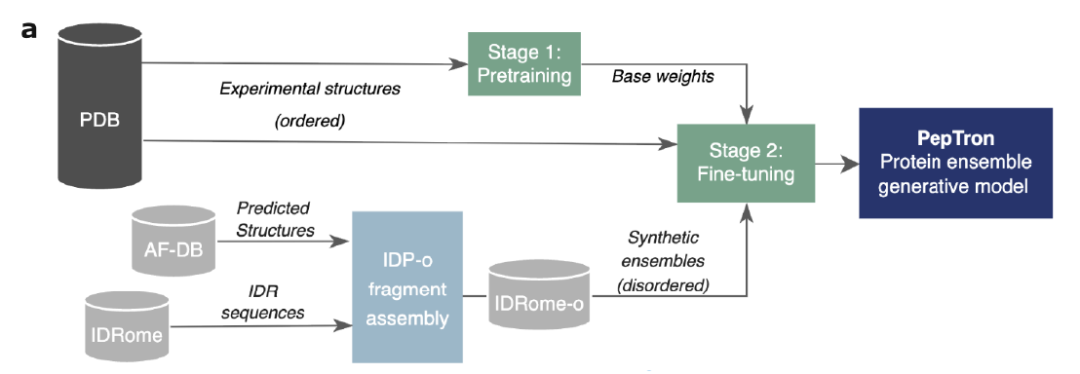
PepTron 模型示意图
面向全谱构象的模型验证:PepTron 与主流方法的系统比较
研究团队随后使用 PeptoneBench 框架,在完全独立于训练集的实验数据上系统评估 PepTron 的性能,并与 ESMFold、ESMFlow、AlphaFold2、Boltz2、BioEmu 等主流模型进行基准对比。同时,团队在专注于内在无序蛋白(IDP)的 PeptoneDB-Integrative 数据集上开展专项测试,以全面检验各模型在无序构象建模上的能力。结果显示出清晰的模型分化特征。
如下图所示,在 PeptoneDB-CS 数据集上,各模型的表现随蛋白质无序程度(G 评分)呈现显著差异:ESMFold 与 ESMFlow 在有序区域预测精确,但在无序区域性能明显降低;IDP-o 则呈现典型的互补模式——无序度越高性能越好;而 PepTron 在整个有序—无序构象谱上都保持稳定的高一致性。 这种均衡能力在 PeptoneDB-SAXS 数据集以及随后的重加权分析中再次被验证,说明 PepTron 在不牺牲有序结构精度的前提下,能够有效捕捉无序蛋白的构象多样性。
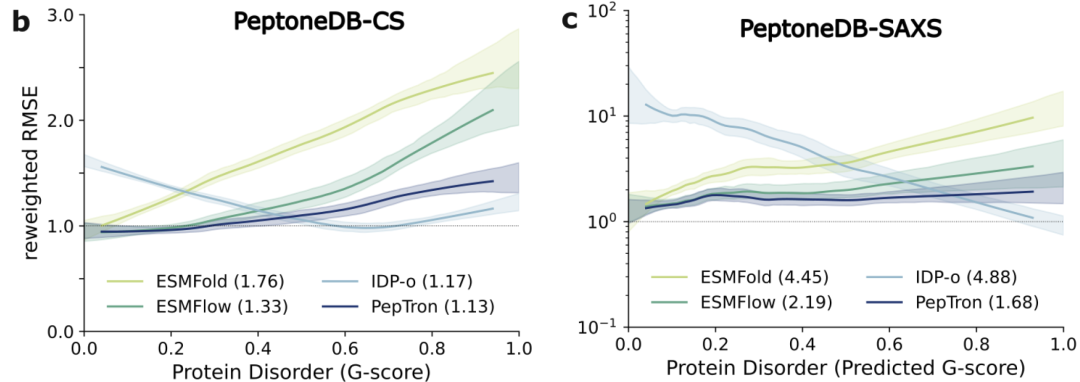
不同模型的 PeptoneDB-CS/SAXS 对比结果
进一步的跨模型对比结果如下图所示,AlphaFold2 与 Boltz2 虽然在有序蛋白的预测中依旧占优,但随着无序程度上升,其性能出现系统性衰减;相比之下,PepTron 与 BioEmu 在整个构象谱上都保持更强的稳健性,更适合处理 IDP 高度异质的结构特征。

不同模型的 PeptoneDB-CS/SAXS 对比结果
为了确保无序区域训练不会损害其对有序蛋白的预测能力,研究团队还在 CAMEO22 和 CASP14 的有序结构数据上进行了额外测试。结果表明,PepTron 在 RMSD、LDDT、TM 等关键指标上与 ESMFlow 表现一致,证明其在扩展 IDR 建模能力的同时并未削弱对有序结构的准确性。
在集成多实验指标的 PeptoneDB-Integrative 数据集中,如下图所示,模型表现进一步呈现差异。IDP-o 在最大熵重加权后表现尤为突出,无论是 RMSE 还是 RDC Q 因子均显著优于其他模型;PepTron 与 BioEmu 在 RDC 指标上接近,但 BioEmu 在局部化学位移预测中更具优势。值得注意的是,即便在未重加权条件下,IDP-o 仍在多数局部与全局指标中领先,体现其在无序蛋白构象覆盖上的天然优势。
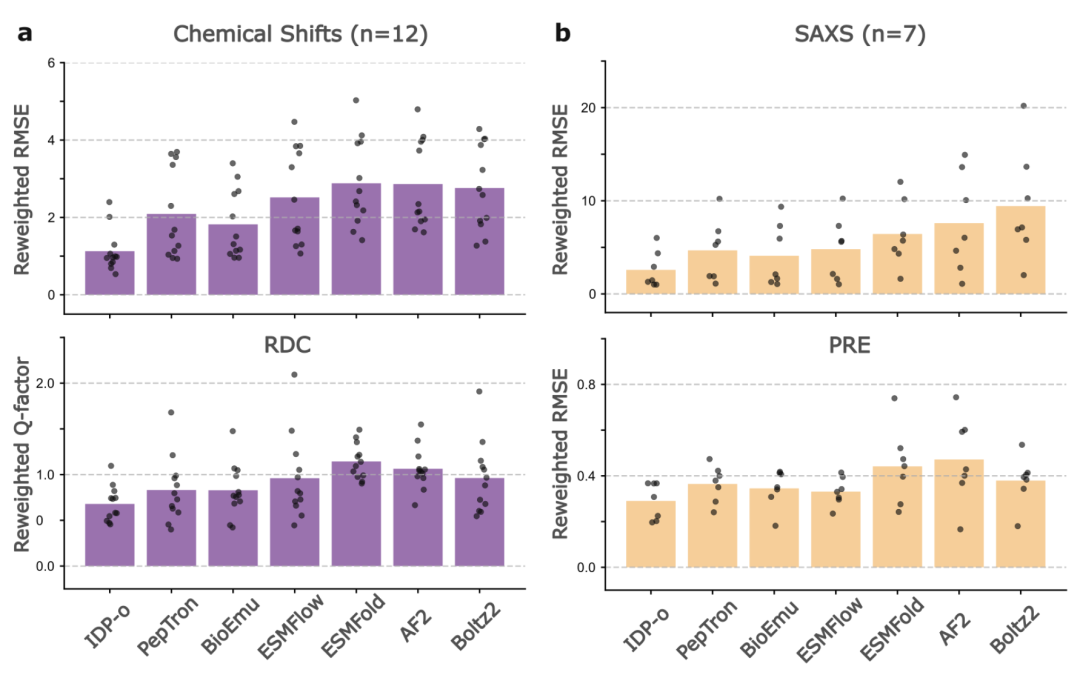
不同模型在 PeptoneDB-Integrative 数据集的预测结果
研究也指出了当前模型的几类共性瓶颈: 多数模型在长程接触偏好上捕捉不足,存在不同程度的二级结构偏置;此外,对于「条件性折叠序列」的未折叠状态,主流模型普遍难以准确描述,而 IDP-o 在这一方面表现出独特的优越性。
从无序到有序:IDP 研究的全球突破与产业新篇
内在无序蛋白(IDPs)因其高度动态的构象特征及与多类重大疾病的紧密相关性,正迅速成为全球生命科学与医药产业的研究前沿。
在学术界,AI 结构预测技术正在成为破解 IDP「动态密码」的关键力量。剑桥大学提出的 AlphaFold-Metainference 方法, 将 AlphaFold 的对齐误差图与分子动力学模拟相结合,突破了传统 AlphaFold 主要预测稳定结构的局限,成功构建了 IDP 及含无序区域蛋白的结构集合,为理解其多态性提供了新路径。
论文题目:
AlphaFold prediction of structural ensembles of disordered proteins
论文链接: https://www.nature.com/articles/s41467-025-56572-9
哥本哈根大学团队进一步整合 AlphaFold 与蛋白质语言模型,实现了人类无序蛋白质组构象的大规模预测, 验证了 AI 技术在 IDP 研究中的普适性与可扩展性。
论文题目:
Conformational ensembles of the human intrinsically disordered proteome
论文链接: https://www.nature.com/articles/s41586-023-07004-5
而学术成果能否真正改变疾病治疗,还取决于产业界的技术转化能力。英国生物技术公司 Peptone 与德国制药企业 Evotec 的合作,便展示了 IDP 研究向药物研发延伸的可行路径。 依托 Peptone 的超快速氢氘交换质谱(HDX-MS)平台,研究人员可实时追踪无序蛋白的动态变化,捕捉传统结构测定手段难以识别的结合位点;再结合 Evotec 在靶点验证、药物筛选及临床推进方面的优势,使得难成药的 IDP 靶点有望转化为具备成药潜力的候选分子。
这一系列进展不仅与 PepTron 模型「覆盖有序—无序结构全谱」的趋势相互呼应,也标志着曾被视为难以捉摸的无序蛋白,正逐步成为精准医学与生物制药中的关键靶点。随着技术突破与产业协作的不断加深,IDPs 或将为未来疾病治疗提供全新的理解框架与干预路径。
参考链接:
1.https://www.vbdata.cn/intelDetail/717834
2.https://c.m.163.com/news/a/JDIR2LQJ0552ZPM2.html
3.https://www.vbdata.cn/intelDetail/580634

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









