




核心问题
在家庭、厨房等人类日常动态环境中,机械臂需在快速变化、部分可观测的场景下实现无碰撞运动,传统全局规划方法(如A*、RRT)依赖完整环境信息,在动态障碍场景中执行速度慢,难以实时调整轨迹;局部反应式方法(如 RMP、几何结构)虽能应对动态障碍,却缺乏全局场景感知,在杂乱环境中易陷入局部极小值;现有神经运动策略(如 MπNets、NeuralMP)则存在泛化能力弱或依赖测试时优化牺牲实时性的问题。
为此,卡内基梅隆大学团队提出深度反应策略(DRP),该策略以点云为直接输入,通过 “IMPACT(基于Transformer的端到端神经运动策略,经大规模模拟轨迹预训练获得全局规划能力)+ 师生微调(融合几何结构控制器修正碰撞误差,提升静态避障精度)+DCP-RMP(动态最近点反应模块,实时调整目标以增强动态障碍躲避能力)” 的三阶方案,解决了动态环境下机械臂运动规划的 “泛化性 - 实时性 - 安全性” 三角难题,最终研究人员使用FrankaResearch3机械臂在模拟与真实场景中均实现复杂场景下的高效无碰撞目标到达,成功率全面超越传统规划方法与现有神经策略。

图1:研究人员提出了深度反应策略(DRP),这是一种基于点云的运动策略,能够在各种复杂和动态的环境中执行反应式、无碰撞的目标达成任务。
验证方法与框架
DRP 以 “预训练 - 微调 - 推理增强” 三阶框架实现性能闭环,各阶段核心逻辑如下:
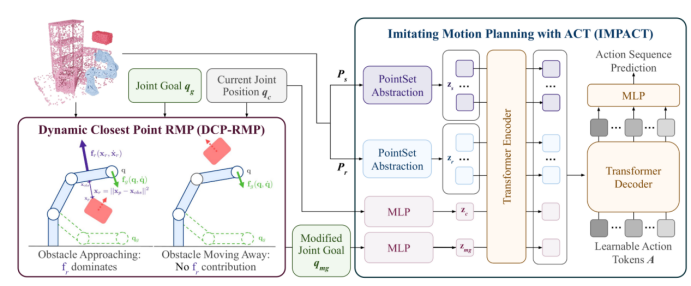
1:深度反应策略 (DRP) 是一种专为动态真实环境设计的视觉运动神经运动策略。首先,局部反应式 DCP-RMP 模块会调整关节目标,以应对局部场景中快速移动的动态障碍物。然后,基于 Transformer 的闭环运动规划策略 IMPACT 将场景点云、修改后的关节目标和当前机器人关节位置作为输入,输出动作序列,供机器人实时执行。
大规模运动预训练:用GPU 加速规划器 cuRobo 生成 1000万条多样化模拟轨迹,基于Transformer架构构建IMPACT,以 “场景点云 + 机器人点云 + 关节位姿” 为输入,通过MSE损失对齐专家轨迹,完成基础规划能力训练。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1983
1983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









