




研究背景
在移动操作机器人领域,近年来的研究重点逐渐从实验室环境转向真实世界应用场景。传统移动操作机器人在面对家庭、办公室等非结构化日常环境时,暴露出诸多难题。
面临控制复杂性高(如基座与手臂协调困难)、泛化能力弱(对新物体和场景适应性差)、数据效率低(需大量演示数据)等难题。
为此,斯坦福大学和剑桥大学研究团队提出HOMER 框架,通过结合基于运动学的全身控制器(处理基座与手臂协调)和混合模仿学习策略(切换长距离绝对姿态与精细操作相对姿态预测),并整合视觉语言模型提升泛化能力。
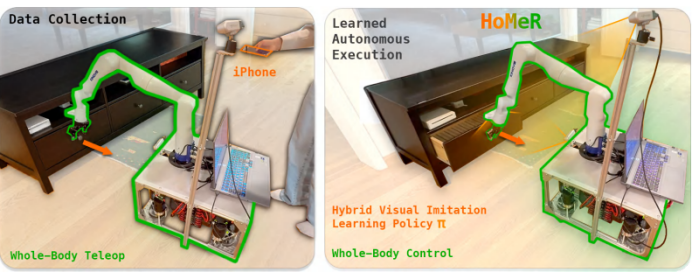
图1:左图:演示者通过全身iPhone 远程操作,利用移动机械臂在真实家庭环境中收集数据。右图:HOMER 从这些收集到的演示数据中,学习到一种混合模仿学习策略,该策略会在用于抵达目标的绝对动作与用于精细操作的相对动作之间进行切换。一个全身控制器将这些末端执行器指令映射为手臂和基座的关节指令,以执行操作。
研究方法与实验框架
HOMER 框架的核心由三部分构成:
全身控制器(WBC):基于运动学,将末端执行器的目标姿态映射为移动基座和机械臂的关节位置命令,通过优化目标函数(包括末端执行器姿态跟踪、关节姿态保持接近中性位置、基座运动阻尼等)和约束条件(关节速度、位置限制及碰撞避免),实现协调运动。
从形式上看,WBC是一个映射W:SE(3)→R3+N,它能将期望的末端执行器位姿 xee∈SE(3) 转换为移动基座和机械臂的关节位置指令 q∈R3+N。研究人员实现了一个基于迭代逆运动学(IK)的求解器,该求解器的目标是找到使位姿误差最小的 q。为了计算能让末端执行器朝 xee 移动的速度,将位姿误差定义为体坐标系下的扭转:eee=log
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2160
2160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









