




 CUDA是由NVIDIA推出的通用并行计算平台和编程模型,旨在简化GPU编程,提高复杂计算效率。CUDA包括库、API、运行库和数学库等组件,支持DRAM读写优化及片上共享内存,以减少数据传输。CUDA程序由主机端和设备端组成,实现数据并行处理。
CUDA是由NVIDIA推出的通用并行计算平台和编程模型,旨在简化GPU编程,提高复杂计算效率。CUDA包括库、API、运行库和数学库等组件,支持DRAM读写优化及片上共享内存,以减少数据传输。CUDA程序由主机端和设备端组成,实现数据并行处理。
CUDA简介
2006年,NVIDIA公司发布了CUDA(Compute Unified Device Architecture),是一种新的操作GPU计算的硬件和软件架构,是建立在NVIDIA的GPUs上的一个通用并行计算平台和编程模型,它提供了GPU编理的简易接口,基于CUDA编程可以构建基于GPU计算的应用程序,利用GPUs的并行计算引擎来更加高效地解决比较复杂的计算难验。它将GPU视作一个数据并行设备,而且无需把这些计算映射图像API。操作系统的多任务机制可以同时管理CUDA访问GPU和图形程序的运行库,其计算特性支持利用CUDA直观编写GPU核心程序。
CUDA在软件方面组成有:一个CUDA库,一个应用程序编程接口(API)及其运行库(Runtime),两个较高级别的通用数学库,即CUFFT和CUBLAS,CUDA改讲了DRAM的读写灵活性,使得GPU与CPU的机制相吻合。另一方面,CUDA提供了片上(on-chip)共享内存,使得线程之间可以共享数据。应用程序可以利用共享内存来减少DRAM的数据传送,更少的依赖DRAM的内存带宽。
CUDA线程模型
CUDA的架构中引入了主机端(host)和设备(device)的概念。CUDA程序中既包含host程序,又包含device程序。同时,host与device之间可以进行通信,这样它们之间可以进行数据拷贝。
主机(Host):将CPU及系统的内存(内存条)称为主机。
设备(Device):将GPU及GPU本身的显示内存称为设备。
典型的CUDA程序的执行流程如下:
1. 分配host内存,并进行数据初始化;
2. 分配device内存: cudaMalloc(void **devPtr, size_t count);
3. 并从host将数据拷贝到device上:cudaMemcpy(void *dst, void *src, size_t count, cudaMemcpyHostToDevice);
4. 调用CUDA的核函数在device上完成指定的运算:<<<M, T>>>;
M表示kernel launches with a gird of M thread blocks。T表示每个thread block具有T parallel threads。
5. 将device上的运算结果拷贝到host上:cudaMemcpy(void *dst, void *src, size_t count, cudaMemcpyDeviceToHost);
6. 释放device和host上分配的内存:cudaFree(),free()。
CUDA线程层次结构
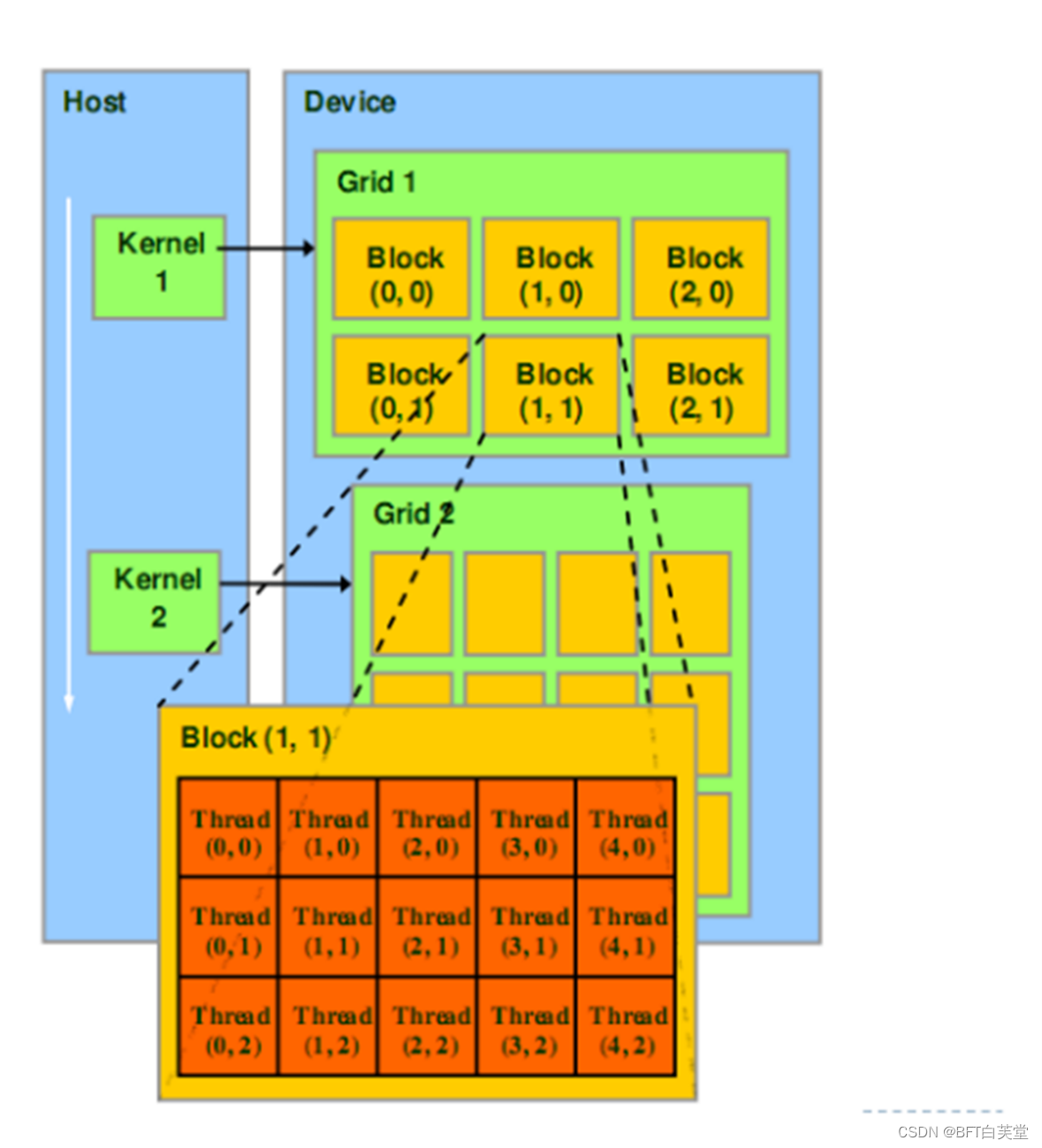
1. 核 kernel
CUDA执行流程中最重要的一个过程是调用CUDA的核函数来执行并行计算,kernel是CUDA中一个重要的概念。在CUDA程序构架中,主机端代码部分在CPU上执行,是普通的C代码;当遇到数据并行处理的部分,CUDA 就会将程序编译成GPU能执行的程序,并传送到GPU,这个程序在CUDA里称做核(kernel)。设备端代码部分在GPU上执行,此代码部分在kernel上编写(.cu文件)。kernel用global符号声明,在调用时需要用<<<grid, block>>>来指定kernel要执行及结构。
CUDA是通过函数类型限定词区别在host和device上的函数,主要的三个函数类型限定词如下:
- global:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用global定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。
- device:在device上执行,单仅可以从device中调用,不可以和global同时用。
- host:在host上执行,仅可以从host上调用,一般省略不写,不可以和global同时用,但可和device同时使用,此时函数会在device和host都编译。
2. 网格 grid
kernel在device上执行时,实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间。grid是线程结构的第一层次。
3. 线程块 block
网格又可以分为很多线程块(block),一个block里面包含很多线程。各block是并行执行的,block间无法通信,也没有执行顺序。block的数量限制为不超过65535(硬件限制)。block是线程结构的第二层次。
grid和block都是定义为dim3类型的变量,dim3可以看成是包含三个无符号整数(x,y,z)成员的结构体变量,在定义时,缺省值初始化为1。grid和block可以灵活地定义为1-dim,2-dim以及3-dim结构。
CUDA中,每一个线程都要执行核函数,每一个线程需要kernel的两个内置坐标变量(blockIdx,threadIdx)来唯一标识,其中blockIdx指明线程所在grid中的位置,threaIdx指明线程所在block中的位置。它们都是dim3类型变量。
4. 线程 thread
一个CUDA的并行程序会被以许多个threads来执行。数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信。
求CUDA中线程索引
可以把网格和线程块都看作一个三维的矩阵。这里假设网格是一个345的三维矩阵, 线程块是一个456的三维矩阵。
gridDim
gridDim.x、gridDim.y、gridDim.z分别表示网格各个维度的大小,所以有
gridDim.x=3
gridDim.y=4
gridDim.z=5
blockDim
blockDim.x、blockDim.y、blockDim.z分别表示线程块中各个维度的大小,所以有
blockDim.x=4
blockDim.y=5
blockDim.z=6
blockIdx
blockIdx.x、blockIdx.y、blockIdx.z分别表示当前线程块所处的线程格的坐标位置
threadIdx
threadIdx.x、threadIdx.y、threadIdx.z分别表示当前线程所处的线程块的坐标位置
网格里面总的线程个数N即可通过下面的公式算出
N = gridDim.x*gridDim.y*gridDim.z*blockDim.x*blockDim.y*blockDim.z
举例:
将所有的线程排成一个序列,序列号为0 , 1 , 2 , … , N ,如何找到当前的序列号?
1. 先找到当前线程位于网格中的哪一个线程块blockId
blockId = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
2. 找到当前线程位于线程块中的哪一个线程threadId
threadId = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
3. 计算一个线程块中一共有多少个线程M
M = blockDim.x*blockDim.y*blockDim.z
4. 求得当前的线程序列号idx
idx = threadId + M*blockId;
本文转载自公众号:BFT智能机器人研究


















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









