




 本项目利用深度学习技术,对狗的图像进行分类,涵盖了数据预处理、模型构建、训练及评估等关键步骤。采用ResNet50网络结构,对dogImages数据集进行处理,包括图像缩放、裁剪、翻转等增强手段,以提高模型泛化能力。
本项目利用深度学习技术,对狗的图像进行分类,涵盖了数据预处理、模型构建、训练及评估等关键步骤。采用ResNet50网络结构,对dogImages数据集进行处理,包括图像缩放、裁剪、翻转等增强手段,以提高模型泛化能力。
dogimage数据集
from sklearn.datasets import load_files
from keras.utils import np_utils
import numpy as np
from glob import glob
import os
from torchvision import datasets
import torch
from PIL import Image
import matplotlib as mpl
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import tensorflow as tf
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
tf.app.flags.DEFINE_integer('is_train', 0, '整数,0代表训练,1代表预测,默认为0')
FLAGS = tf.app.flags.FLAGS
# 设置字符集,防止中文乱码
mpl.rcParams['font.sans-serif'] = [u'simHei']
mpl.rcParams['axes.unicode_minus'] = False
# 定义函数来加载train,test和validation数据集
def load_dataset(path):
data = load_files(path)
dog_files = np.array(data['filenames'])
dog_targets = np_utils.to_categorical(np.array(data['target']), 133)
return dog_files, dog_targets
def explore_data():
# 1、加载数据
train_files, train_targets = load_dataset('../datas/dogImages/dogImages/train')
valid_files, valid_targets = load_dataset('../datas/dogImages/dogImages/valid')
test_files, test_targets = load_dataset('../datas/dogImages/dogImages/test')
# 2、加载狗的品种
dog_names = [item[39:-1] for item in sorted(glob('../datas/dogImages/dogImages/train/*/'))]
# print(dog_names)
# 3、描述性统计
print(train_files)
print('总的狗狗的类别数量:{}'.format(len(dog_names)))
print('总共有图片数量:{}'.format(len(np.hstack([train_files, valid_files, test_files]))))
print('train dog images:{} - Valid dog images:{} - Test dog images:'
'{}'.format(len(train_files), len(valid_files), len(test_files)))
# todo 构建读取数据的迭代器。
train_dir = '../datas/dogImages/dogImages/train'
valid_dir = '../datas/dogImages/dogImages/valid'
test_dir = '../datas/dogImages/dogImages/test'
def data_transform(batch_size=4):
"""
实现:1、缩放 ; 2、裁剪为224*224*3 ;3、随机翻转; 4、随机旋转0-20度;5、标准化
:param batch_size:
:return:
"""
# Normalize([[0.5, 0.5, 0.5], [0.5, 0.5, 0.5]]) 指 mean=0.5, std = 0.5
train_transform = transforms.Compose(
[transforms.Resize(254), transforms.RandomCrop(224), transforms.RandomHorizontalFlip(),
transforms.RandomRotation(20), transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]
)
valid_transform = transforms.Compose(
[transforms.Resize(254), transforms.CenterCrop(224), transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]
)
test_transform = transforms.Compose(
[transforms.Resize(254), transforms.CenterCrop(224), transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]
)
train_data = datasets.ImageFolder(train_dir, transform=train_transform)
valid_data = datasets.ImageFolder(valid_dir, transform=valid_transform)
test_data = datasets.ImageFolder(test_dir, transform=test_transform)
# 使用 image datasets 和 transforms 来定义一个数据加载的迭代器。
train_dataloaders = torch.utils.data.DataLoader(
train_data, batch_size=batch_size, shuffle=True
)
valid_dataloaders = torch.utils.data.DataLoader(
valid_data, batch_size=batch_size, shuffle=True
)
test_dataloaders = torch.utils.data.DataLoader(
test_data, batch_size=batch_size, shuffle=True
)
return train_dataloaders, valid_dataloaders, test_dataloaders
def show_data():
train_dataloaders, valid_dataloaders, test_dataloaders = data_transform(batch_size=2)
for batch_idx, (data, target) in enumerate(train_dataloaders):
batch_images = data.numpy() # [N, C, H, W]
batch_images = np.transpose(batch_images, axes=[0, 2, 3, 1]) # [N, H, W, C]
batch_y = target.numpy()
print(type(batch_images), batch_images.shape,
batch_images.min(), batch_images.max())
print(batch_y, batch_y.shape, type(batch_y[0])) # [ 0 43] (2,) <class 'numpy.int64'>
print('**' * 80)
if batch_idx >=2:
break
def show_dog_images():
train_dataloaders, valid_dataloaders, test_dataloaders = data_transform(batch_size=32)
def imshow(img):
img = img / 2 + 0.5
plt.imshow(np.transpose(img, (1, 2, 0)))
# 定义一个迭代器
dataiter = iter(train_dataloaders)
images, labels = dataiter.next()
images = images.numpy()
# 画图
fig = plt.figure(figsize=(25, 4))
for idx in np.arange(20):
ax = fig.add_subplot(2, 20/2, idx+1, xticks=[], yticks=[])
imshow(images[idx])
ax.set_title(labels[idx].item())
plt.show()
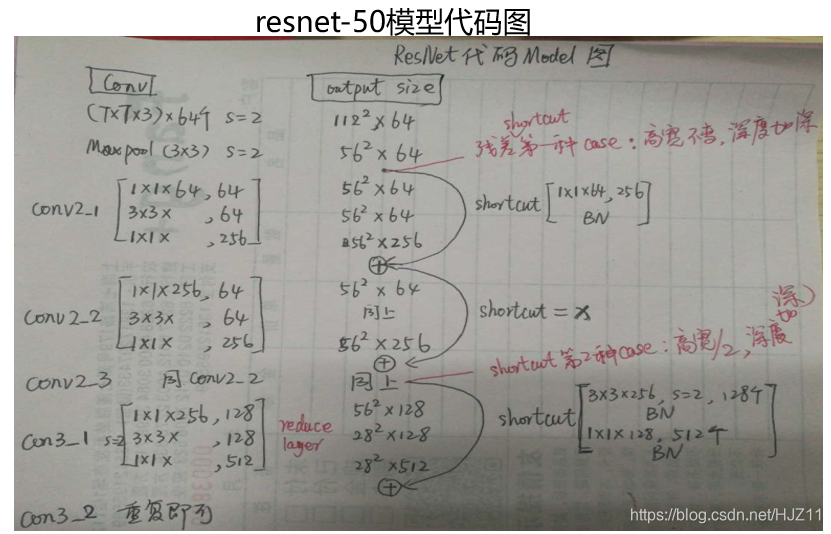
class Tensors:
def __init__(self):
self.input_x = tf.placeholder(tf.float32, shape=[None, 224, 224, 3], name='x')
self.bn_train = tf.placeholder_with_default(True, shape=None, name='bn_train')
self.weight_decay = 1e-3 # L2正则化因子
self.learning_rate = tf.placeholder(tf.float32, shape=None, name='learning_rate')
# 构建模型图
with tf.variable_scope('Network', initializer=tf.truncated_normal_initializer(stddev=0.1)):
with tf.variable_scope('conv1'):
conv1 = tf.layers.conv2d(
self.input_x, 64, kernel_size=3, strides=2, padding='same', activation=tf.nn.relu,
kernel_regularizer=tf.contrib.layers.l2_regularizer(self.weight_decay)
) # [N, 112, 112, 64]
pool1 = tf.layers.max_pooling2d(conv1, pool_size=3, strides=2, padding='same')
# [N, 56, 56, 64]
with tf.variable_scope('conv2'):
conv2 = self.resnet_bottlenect_block(pool1, 64, resize=False, block_strides=1)
conv2 = self.resnet_bottlenect_block(conv2, 64, False)
conv2 = self.resnet_bottlenect_block(conv2, 64, False)
# [N, 56, 56, 256]
with tf.variable_scope('conv3'):
conv3 = self.resnet_bottlenect_block(conv2, 128, resize=True, block_strides=2)
conv3 = self.resnet_bottlenect_block(conv3, 128, False)
conv3 = self.resnet_bottlenect_block(conv3, 128, False)
conv3 = self.resnet_bottlenect_block(conv3, 128, False)
# [N, 28, 28, 512]
with tf.variable_scope('conv4'):
conv4 = self.resnet_bottlenect_block(conv3, 256, resize=True, block_strides=2)
conv4 = self.resnet_bottlenect_block(conv4, 256, False)
conv4 = self.resnet_bottlenect_block(conv4, 256, False)
conv4 = self.resnet_bottlenect_block(conv4, 256, False)
conv4 = self.resnet_bottlenect_block(conv4, 256, False)
conv4 = self.resnet_bottlenect_block(conv4, 256, False)
# [N, 14, 14, 1024]
with tf.variable_scope('conv5'):
conv5 = self.resnet_bottlenect_block(conv4, 512, resize=True, block_strides=2)
conv5 = self.resnet_bottlenect_block(conv5, 512, False)
conv5 = self.resnet_bottlenect_block(conv5, 512, False)
# [N, 7, 7, 2048]
with tf.variable_scope('avg6'):
conv6 = tf.layers.average_pooling2d(
conv5, pool_size=7, strides=1, padding='valid'
) # [N, 1, 1, 2048]
shape = conv6.get_shape()
flatten_shape = shape[1] * shape[2] * shape[3]
conv6 = tf.reshape(conv6, shape=[-1, flatten_shape])
with tf.variable_scope('logits7'):
self.logits = tf.layers.dense(
conv6, units=133, activation=None, name='logits'
)
# 构建损失函数
self.input_y = tf.placeholder(tf.int64, shape=[None], name='y')
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=self.input_y, logits=self.logits
))
# todo 添加正则项损失
l2_loss = tf.losses.get_regularization_loss()
self.loss = loss + l2_loss
# 创建优化器
with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
optimizer = tf.train.GradientDescentOptimizer(self.learning_rate)
self.train_opt = optimizer.minimize(self.loss)
# 计算准确率
correct_pred = tf.equal(tf.argmax(self.logits, 1), self.input_y)
self.accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
def resnet_bottlenect_block(self, x, std_filter, resize=False, block_strides=1):
"""
实现残差网络的瓶颈结构
:param x: 输入
:param std_filter: 标准滤波器的概述。
:param resize: 是否决定下采样的 布尔值
:param block_strides: 和 resize成对的。 若resize=True 那么 block_strides=2, 反之为1.
:return:
"""
# todo 如果该层是每个卷积模块的第一层,需要对图片进行下采样。(这里执行的是 对shortcut进行下采样)
if resize:
right = tf.layers.conv2d(
x, filters=std_filter, kernel_size=3, strides=block_strides, padding='same',
use_bias=False
)
right = tf.layers.batch_normalization(right, training=self.bn_train)
else:
right = x
# 实现残差模块
# 1*1 卷积
left = tf.layers.conv2d(
x, filters=std_filter, kernel_size=1, strides=1, padding='same', use_bias=False,
kernel_regularizer=tf.contrib.layers.l2_regularizer(self.weight_decay)
)
left = tf.layers.batch_normalization(left, training=self.bn_train)
left = tf.nn.relu(left)
# 3*3 卷积
left = tf.layers.conv2d(
left, filters=std_filter, kernel_size=3, strides=block_strides, padding='same', use_bias=False,
kernel_regularizer=tf.contrib.layers.l2_regularizer(self.weight_decay)
)
left = tf.layers.batch_normalization(left, training=self.bn_train)
left = tf.nn.relu(left)
# 1*1卷积 (linear)
left = tf.layers.conv2d(
left, filters=std_filter*4, kernel_size=1, strides=1, padding='same', use_bias=False,
kernel_regularizer=tf.contrib.layers.l2_regularizer(self.weight_decay)
)
left = tf.layers.batch_normalization(left, training=self.bn_train)
# 做一个判断,如果shortcut的深度 不是4*std_filters,那么使用1*1卷积加深深度。
if right.shape[-1].value != std_filter*4:
right = tf.layers.conv2d(
right, filters=std_filter*4, kernel_size=1, strides=1, padding='same',
use_bias=False
)
right = tf.layers.batch_normalization(right, training=self.bn_train)
res_block_out = tf.add(left, right)
return tf.nn.relu(res_block_out)
def train():
# 超参数设置
epochs = 10
lr = 0.001
print_every_step = 2
save_every_epoch = 5
batch_size = 2
checkpoint_dir = './model/resnet50'
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
graph = tf.Graph()
with graph.as_default():
tensor = Tensors() # 构建模型图
saver = tf.train.Saver(max_to_keep=1)
with tf.Session(graph=graph) as sess:
sess.run(tf.global_variables_initializer())
# 读入数据。
train_dataloaders, valid_dataloaders, test_dataloaders = data_transform(batch_size=batch_size)
for e in range(1, epochs):
for batch_idx, (data, target) in enumerate(train_dataloaders):
batch_images = data.numpy() # [N, C, H, W]
batch_images = np.transpose(batch_images, axes=[0, 2, 3, 1]) # [N, H, W, C]
batch_y = target.numpy()
feed = {tensor.input_x: batch_images, tensor.input_y: batch_y,
tensor.learning_rate: lr}
# 执行模型训练
sess.run(tensor.train_opt, feed_dict=feed)
if batch_idx % print_every_step ==0:
train_loss, train_acc = sess.run([tensor.loss, tensor.accuracy], feed)
print('Epochs:{} - Step:{} - Train loss:{:.5f} - Train acc:{:.5f}'.format(
e, batch_idx, train_loss, train_acc
))
# 模型持久化
if e % save_every_epoch ==0:
files = 'model.ckpt'
save_files = os.path.join(checkpoint_dir, files)
saver.save(sess, save_path=save_files)
print('saved model to files:{}'.format(save_files))
# 模型验证
val_avg_loss, val_avg_acc = [], []
for data, target in valid_dataloaders:
batch_images = data.numpy() # [N, C, H, W]
batch_images = np.transpose(batch_images, axes=[0, 2, 3, 1]) # [N, H, W, C]
batch_y = target.numpy()
valid_feed = {tensor.input_x: batch_images, tensor.input_y: batch_y,
tensor.bn_train: False}
val_loss, val_acc = sess.run([tensor.loss, tensor.accuracy], valid_feed)
val_avg_loss.append(val_loss); val_avg_acc.append(val_acc)
print('Epochs:{} - Valid loss:{} - Valid Acc:{}'.format(
e, np.mean(val_avg_loss), np.mean(val_avg_acc)
))
if __name__ == '__main__':
# explore_data()
# show_data()
# show_dog_images()
train()


















 3555
3555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









