



最近AI界最火的话题非深度研究Agent(Deep Research Agent)莫属了。OpenAI、Grok、Gemini,还有Qwen都推出了自己的DeepResearch产品,这股热潮的幕后推手就是DeepSeek R1推理模型的横空出世。
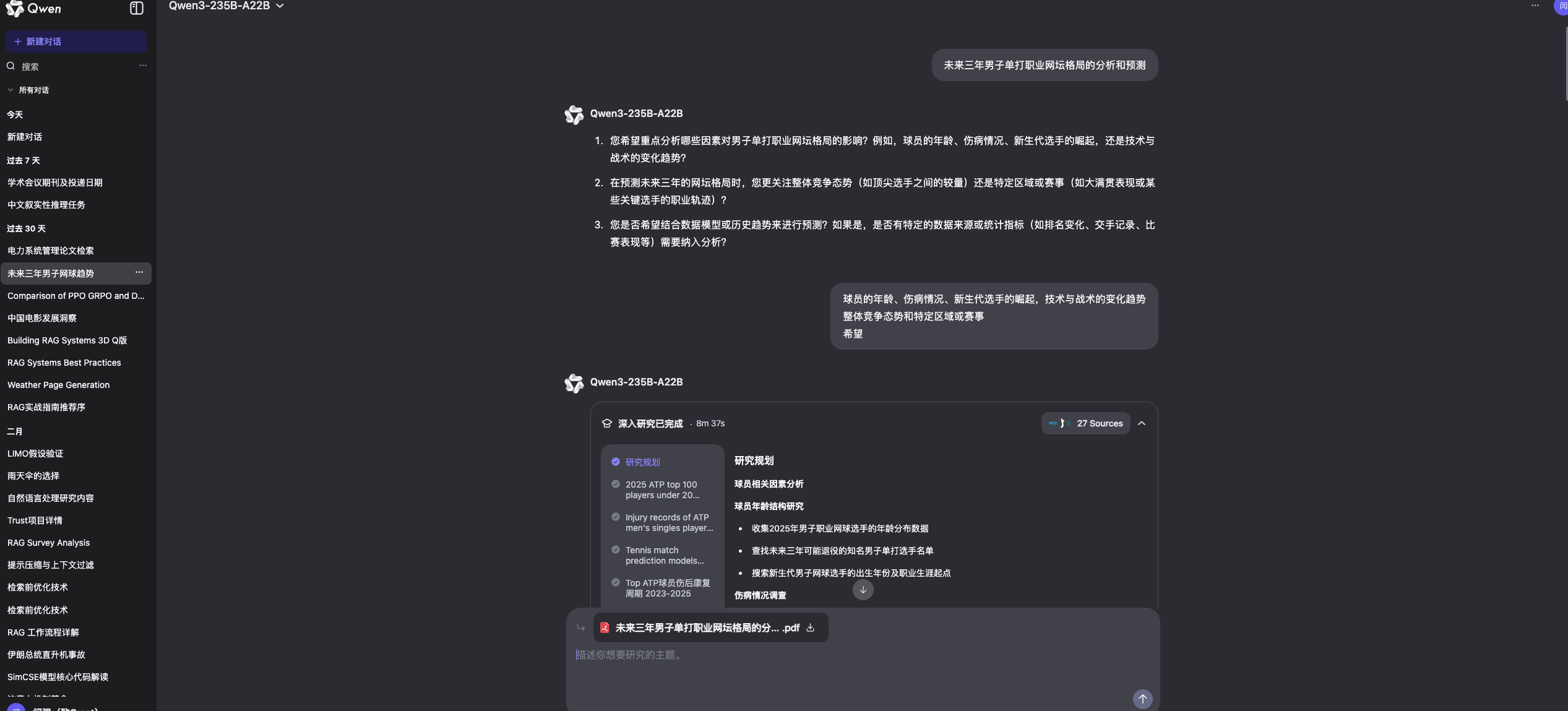
看着这些大厂的产品,是不是也想实现一个小型DeepResearch?前几天笔者看到一个文章,https://www.newsletter.swirlai.com/p/building-deep-research-agent-from,笔者基于这个文章进行完善,实现一个DeepResearch,实现了中文版本以及streamlit应用的创建,这个代码可以帮助我们从底层手撸一个属于自己的深度研究Agent。
修改之后的代码放在这里:https://github.com/yanqiangmiffy/Agent-Tutorials-ZH/tree/main/deep_research_agent
咱们不用任何现成的LLM编排框架,纯手工打造,让大家彻底搞懂这些系统背后的运作原理。这个可以根据自己框架基础来自行选择,DeepResearch关键在于怎么设计深度研究流程。
深度研究Agent到底是个啥?
简单来说,这些DeepResearch就像一个超级勤奋的研究助理,能针对指定主题进行深入研究。它的工作流程一般是这样的:
核心工作步骤
- 研究规划:为最终的研究报告创建大纲
- 任务分解:把大纲拆解成一个个可管理的小任务
- 深度研究执行:针对报告的每个部分进行深入研究,包括推理需要什么数据、利用搜索工具获取信息
- 结果回顾:回过头看看研究过程中生成的数据,看有没有遗漏的地方
- 数据总结:把所有检索到的数据整理成最终的研究报告
听起来很复杂?其实不然,咱们一步步来实现。
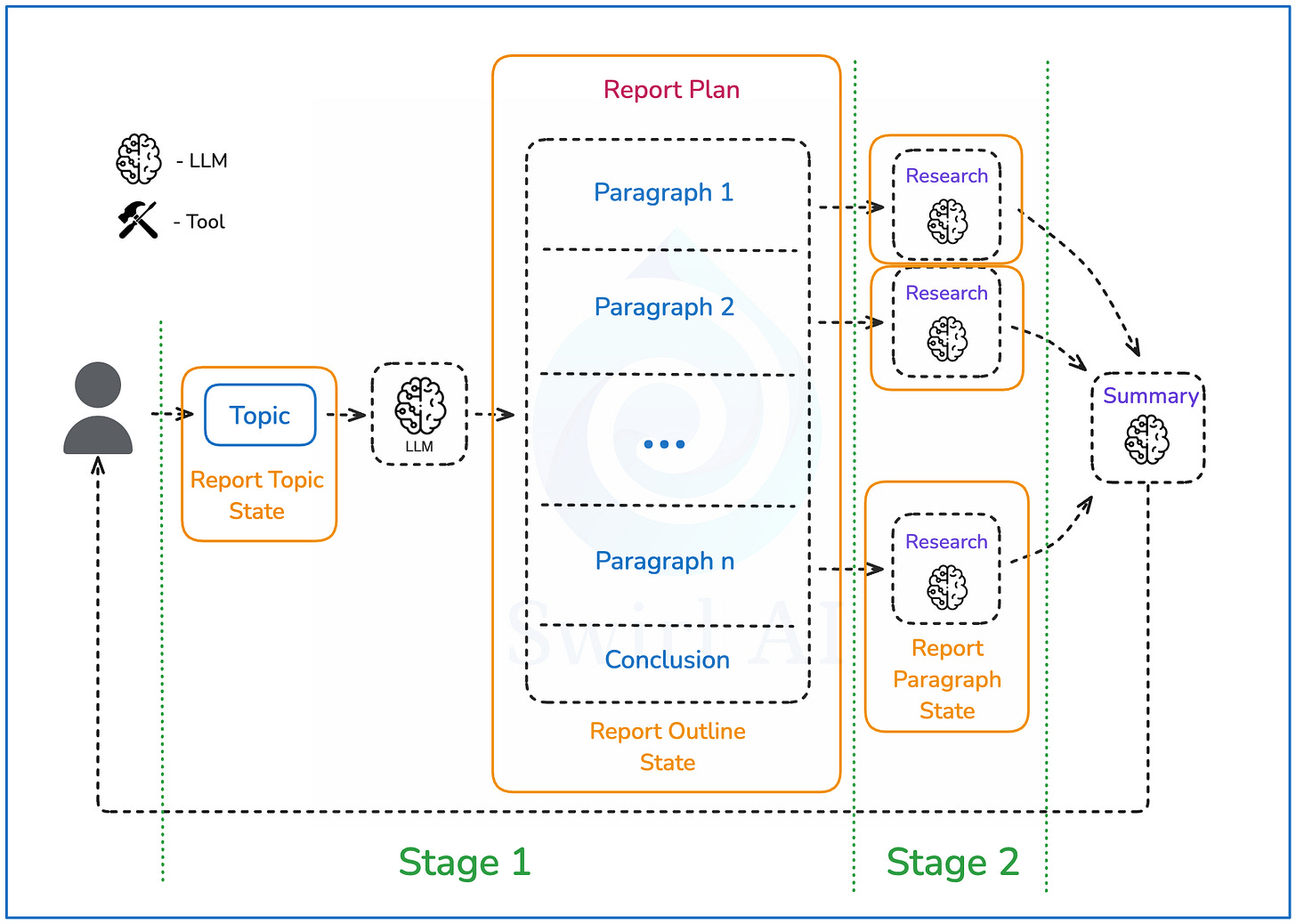
系统架构设计
先来看看咱们要构建的系统长什么样:

整个系统的运行流程是这样的:
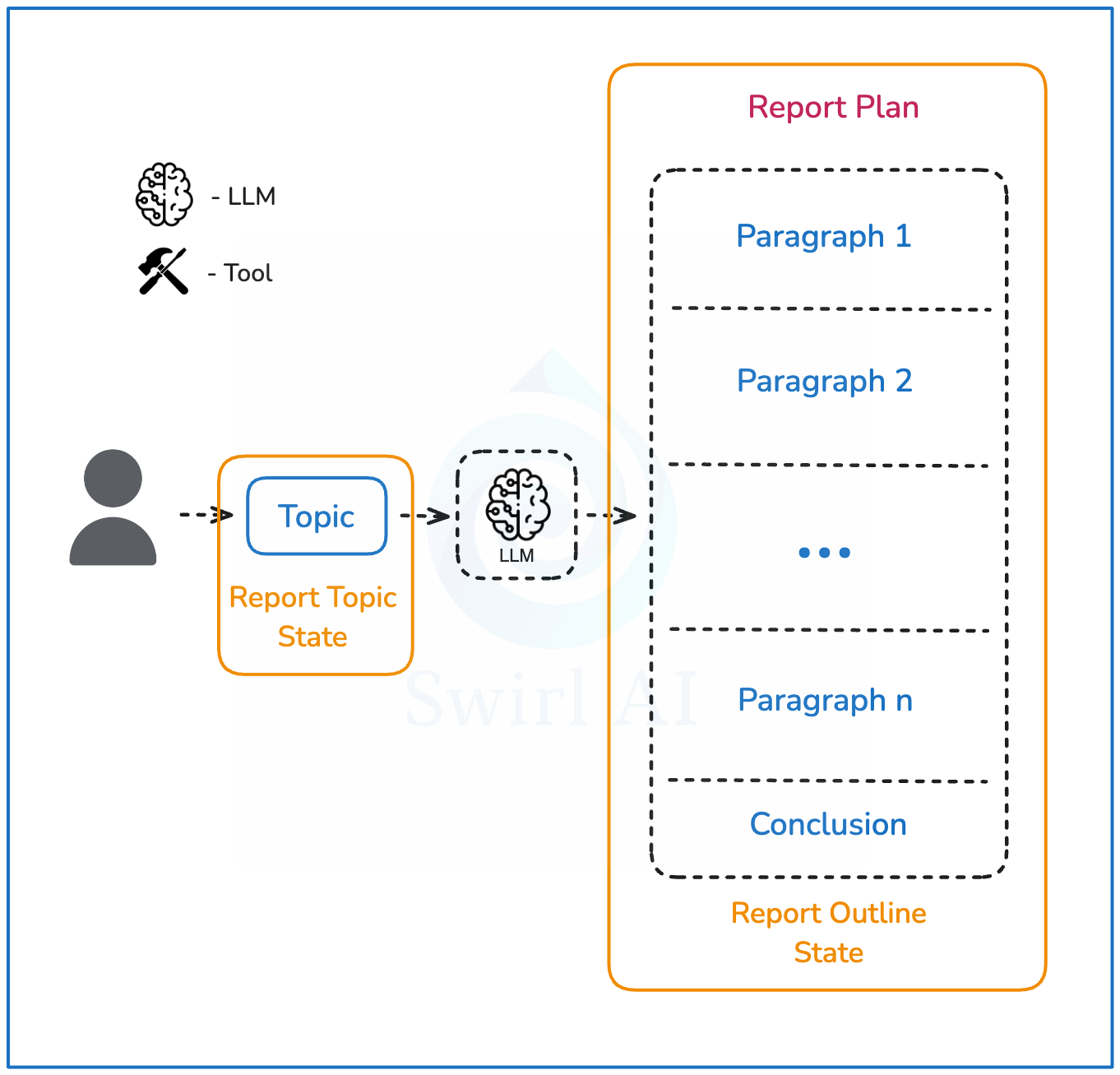
- 用户输入:提供研究的查询或主题
- 生成大纲:LLM根据目标生成最终报告的大纲,限定在一定数量的段落内
- 段落研究:每个段落的描述单独输入研究过程,生成全面的信息
- 信息汇总:所有信息汇总,进行总结,构建包含结论的最终报告
- 格式输出:最终报告以MarkDown格式交付
研究步骤深入解析
重点来了,咱们再仔细看看每个段落的研究步骤:
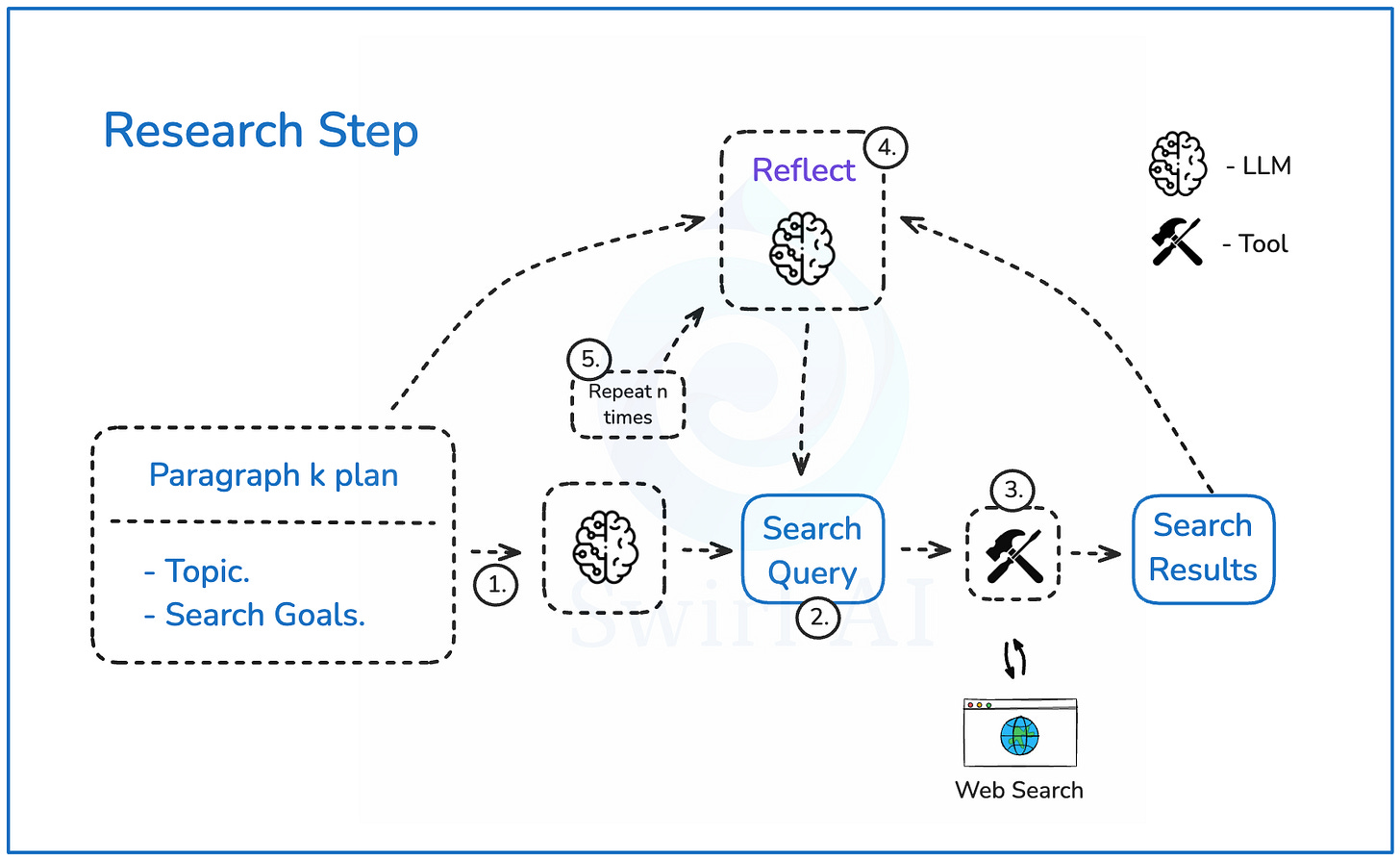
- 构建搜索查询:拿到段落大纲后,让LLM构建网络搜索查询
- 输出查询和推理:LLM输出搜索查询及其推理过程
- 执行网络搜索:根据查询执行网络搜索,检索最相关的结果
- 回顾反思:分析可能遗漏的细节,尝试生成新的搜索查询补充初始结果
- 循环优化:这个过程重复n次,直到获得最佳信息集
开始动手实现
环境准备
首先得安装必要的依赖:
pip install openai
咱们用的是DeepSeek-R1(6710亿参数)的非蒸馏版。如果访问不了这个版本,可以先加入等候列表,或者切换到更小的蒸馏版。
设置好环境变量SAMBANOVA_API_KEY,然后试试能不能正常调用:
import os
import openai
client = openai.OpenAI(
api_key=os.environ.get("SAMBANOVA_API_KEY"),
base_url="https://preview.snova.ai/v1",
)
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content":"You are a helpful assistant"},
{"role":"user","content":"Tell me something interesting about human species"}],
temperature=1
)
print(response.choices[0].message.content)
运行后会看到类似的输出:
<think>Okay, so I'm trying to ... <REDACTED>
</think>
The human species is distinguished by the remarkable cognitive abilities...
注意到那个<think>标签了吗?这是推理模型的思考过程,很有趣,但咱们的系统只需要最终结果。来写个简单的函数把它去掉:
def remove_reasoning_from_output(output):
return output.split("</think>")[-1].strip()
第一步:定义状态结构
Agent在运行过程中需要维护一个状态,这个状态会随着系统的运行不断演变。咱们先来定义一下:
用Python的dataclass来实现会很清晰:
from dataclasses import dataclass, field
from typing import List
@dataclass
class Search:
url: str = ""
content: str = ""
@dataclass
class Research:
search_history: List[Search] = field(default_factory=list)
latest_summary: str = ""
reflection_iteration: int = 0
@dataclass
class Paragraph:
title: str = ""
content: str = ""
research: Research = field(default_factory=Research)
@dataclass
class State:
report_title: str = ""
paragraphs: List[Paragraph] = field(default_factory=list)
这个状态结构包含了:
search_history:存储所有搜索结果,包含url和contentlatest_summary:结合所有搜索历史的段落总结reflection_iteration:跟踪当前的回顾迭代次数
第二步:创建报告大纲
经过大量实验,笔者发现下面这个Prompt能让DeepSeek-R1持续生成格式良好的输出:
import json
output_schema_report_structure = {
"type": "array",
"items": {
"type":"object",
"properties": {
"title": {"type": "string"},
"content": {"type": "string"}
}
}
}
SYSTEM_PROMPT_REPORT_STRUCTURE = f"""
你是一个深度研究助手。给定一个查询,规划一份报告的结构和应包含的段落。
确保段落的顺序合理。
大纲生成后,你将获得工具,针对每个section进行网络搜索和回顾。
请使用以下JSON Schema定义的格式输出JSON对象:
<OUTPUT JSON SCHEMA>
{json.dumps(output_schema_report_structure, indent=2)}
</OUTPUT JSON SCHEMA>
title和content属性将用于后续的深度研究。
确保输出是一个JSON对象,符合上述定义的JSON Schema。
只返回JSON对象,不包含任何解释或其他文本。
"""
测试一下:
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content":SYSTEM_PROMPT_REPORT_STRUCTURE},
{"role":"user","content":"Tell me something interesting about human species"}],
temperature=1
)
print(response.choices[0].message.content)
会得到类似这样的输出:
[
{
"title": "Introduction to Human Adaptability",
"content": "Humans possess a unique capacity for adaptability..."
},
{
"title": "Conclusion: The Role of Adaptability in Human Survival",
"content": "Adaptability has been a cornerstone of human survival..."
}
]
输出周围那些json标签对咱们来说有点碍事,写个函数清理一下:
def clean_json_tags(text):
return text.replace("```json\n", "").replace("\n```", "")
然后就可以把结果转换成Python字典,填充到全局状态里:
STATE = State()
report_structure = json.loads(clean_json_tags(remove_reasoning_from_output(response.choices[0].message.content)))
for paragraph in report_structure:
STATE.paragraphs.append(Paragraph(title=paragraph["title"], content=paragraph["content"]))
第三步:网络搜索工具
咱们用Tavily来做网络搜索。先去这里申请个API token。
应该是每个月有1000次免费搜索,用来我们实验足够了
搜索工具函数很简单:
import os
from tavily import TavilyClient
def tavily_search(query, include_raw_content=True, max_results=5):
tavily_client = TavilyClient(api_key=os.getenv("TAVILY_API_KEY"))
return tavily_client.search(query,
include_raw_content=include_raw_content,
max_results=max_results)
每次调用会返回最多max_results个搜索结果,包括:
- 搜索结果的标题
- 搜索结果的URL
- 内容的摘要
- 如果可能的话,页面的完整内容
拿到搜索结果后,咱们需要更新全局状态。写个便捷函数:
def update_state_with_search_results(search_results, idx_paragraph, state):
for search_result in search_results["results"]:
search = Search(url=search_result["url"], content=search_result["raw_content"])
state.paragraphs[idx_paragraph].research.search_history.append(search)
return state
第四步:规划搜索
为了规划第一次搜索,这个Prompt效果不错:
input_schema_first_search = {
"type": "object",
"properties": {
"title": {"type": "string"},
"content": {"type": "string"}
}
}
output_schema_first_search = {
"type": "object",
"properties": {
"search_query": {"type": "string"},
"reasoning": {"type": "string"}
}
}
SYSTEM_PROMPT_FIRST_SEARCH = f"""
你是一个深度研究助手。你将获得报告中的一个段落及其标题和期望的内容。
你可以使用一个网络搜索工具,该工具接受'search_query'作为参数。
你的任务是思考该主题,并提供最合适的网络搜索查询,以丰富你现有的知识。
请使用JSON格式输出。
只返回JSON对象,不包含任何解释或其他文本。
"""
测试一下:
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content":SYSTEM_PROMPT_FIRST_SEARCH},
{"role":"user","content":json.dumps(STATE.paragraphs[0])}],
temperature=1
)
print(response.choices[0].message.content)
会得到类似这样的搜索查询:
{"search_query": "Homo sapiens characteristics basic biological traits cognitive abilities behavioral traits"}
直接拿这个查询去搜索:
tavily_search("Homo sapiens characteristics basic biological traits cognitive abilities behavioral traits")
第五步:第一次总结
第一次总结跟后面的回顾步骤不太一样,因为这时候还没有任何内容可以回顾。这个Prompt比较好用:
input_schema_first_summary = {
"type": "object",
"properties": {
"title": {"type": "string"},
"content": {"type": "string"},
"search_query": {"type": "string"},
"search_results": {
"type": "array",
"items": {"type": "string"}
}
}
}
output_schema_first_summary = {
"type": "object",
"properties": {
"paragraph_latest_state": {"type": "string"}
}
}
SYSTEM_PROMPT_FIRST_SUMMARY = f"""
你是一个深度研究助手。你将获得搜索查询、搜索结果以及你正在研究的报告段落。
你的任务是作为一名研究员,根据搜索结果撰写段落,使其符合段落的主题,并适当组织结构以便包含在报告中。
请使用JSON格式输出。
只返回JSON对象,不包含任何解释或其他文本。
"""
构建输入数据:
search_results = tavily_search("Homo sapiens characteristics basic biological traits cognitive abilities behavioral traits")
input = {
"title": "Introduction to Human Adaptability",
"content": "Humans possess a unique capacity for adaptability...",
"search_query": "Homo sapiens characteristics basic biological traits cognitive abilities behavioral traits",
"search_results": [result["raw_content"][0:20000] for result in search_results["results"] if result["raw_content"]]
}
运行总结:
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content": SYSTEM_PROMPT_FIRST_SUMMARY},
{"role":"user","content":json.dumps(input)}],
temperature=1
)
print(remove_reasoning_from_output(response.choices[0].message.content))
会得到一个详细的段落总结,这就是咱们要用来更新STATE.paragraphs[0].research.latest_summary字段的内容。
第六步:回顾反思
现在有了段落内容的最新状态,咱们可以利用它来改进内容。让LLM回顾一下文本,看看有没有遗漏的地方:
input_schema_reflection = {
"type": "object",
"properties": {
"title": {"type": "string"},
"content": {"type": "string"},
"paragraph_latest_state": {"type": "string"}
}
}
output_schema_reflection = {
"type": "object",
"properties": {
"search_query": {"type": "string"},
"reasoning": {"type": "string"}
}
}
SYSTEM_PROMPT_REFLECTION = f"""
你是一个深度研究助手,负责为研究报告构建全面的段落。
你将获得段落标题和规划的内容摘要,以及你已经创建的段落的最新状态。
你可以使用一个网络搜索工具,该工具接受'search_query'作为参数。
你的任务是回顾当前段落文本的状态,思考是否遗漏了主题的关键方面,
并提供最合适的网络搜索查询,以补充最新状态。
请使用JSON格式输出。
只返回JSON对象,不包含任何解释或其他文本。
"""
构建输入并运行:
input = {
"paragraph_latest_state": "Homo sapiens, the species to which modern humans belong...",
"title": "Introduction",
"content": "The human species, Homo sapiens, is one of the most unique..."
}
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content": SYSTEM_PROMPT_REFLECTION},
{"role":"user","content":json.dumps(input)}],
temperature=1
)
print(remove_reasoning_from_output(response.choices[0].message.content))
会得到新的搜索查询,比如:
{
"search_query": "Recent research on Homo sapiens evolution, interaction with other human species, and factors contributing to their success",
"reasoning": "The current paragraph provides a good overview..."
}
第七步:利用回顾搜索结果丰富内容
拿到回顾步骤的搜索查询后:
search_results = tavily_search("Recent research on Homo sapiens evolution, interaction with other human species, and factors contributing to their success")
更新段落的搜索状态:
update_state_with_search_results(search_results, idx_paragraph, state)
然后把步骤6和7在循环中运行指定次数,完成回顾步骤。
第八步:总结并生成报告
对每个段落都重复步骤4-7。所有段落的最终状态都准备好后,就可以把它们整合在一起了。用LLM生成一份格式优美的MarkDown文档:
input_schema_report_formatting = {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": {"type": "string"},
"paragraph_latest_state": {"type": "string"}
}
}
}
SYSTEM_PROMPT_REPORT_FORMATTING = f"""
你是一个深度研究助手。你已经完成了研究并构建了报告中所有段落的最终版本。
你的任务是将报告良好地格式化并以MarkDown格式返回。
如果报告中没有结论段落,请根据其他段落的最新状态在报告末尾添加一个结论。
"""
运行最终的报告生成:
report_data = [{"title": paragraph.title, "paragraph_latest_state": paragraph.research.latest_summary} for paragraph in STATE.paragraphs]
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content": SYSTEM_PROMPT_REPORT_FORMATTING},
{"role":"user","content":json.dumps(report_data)}],
temperature=1
)
print(remove_reasoning_from_output(response.choices[0].message.content))
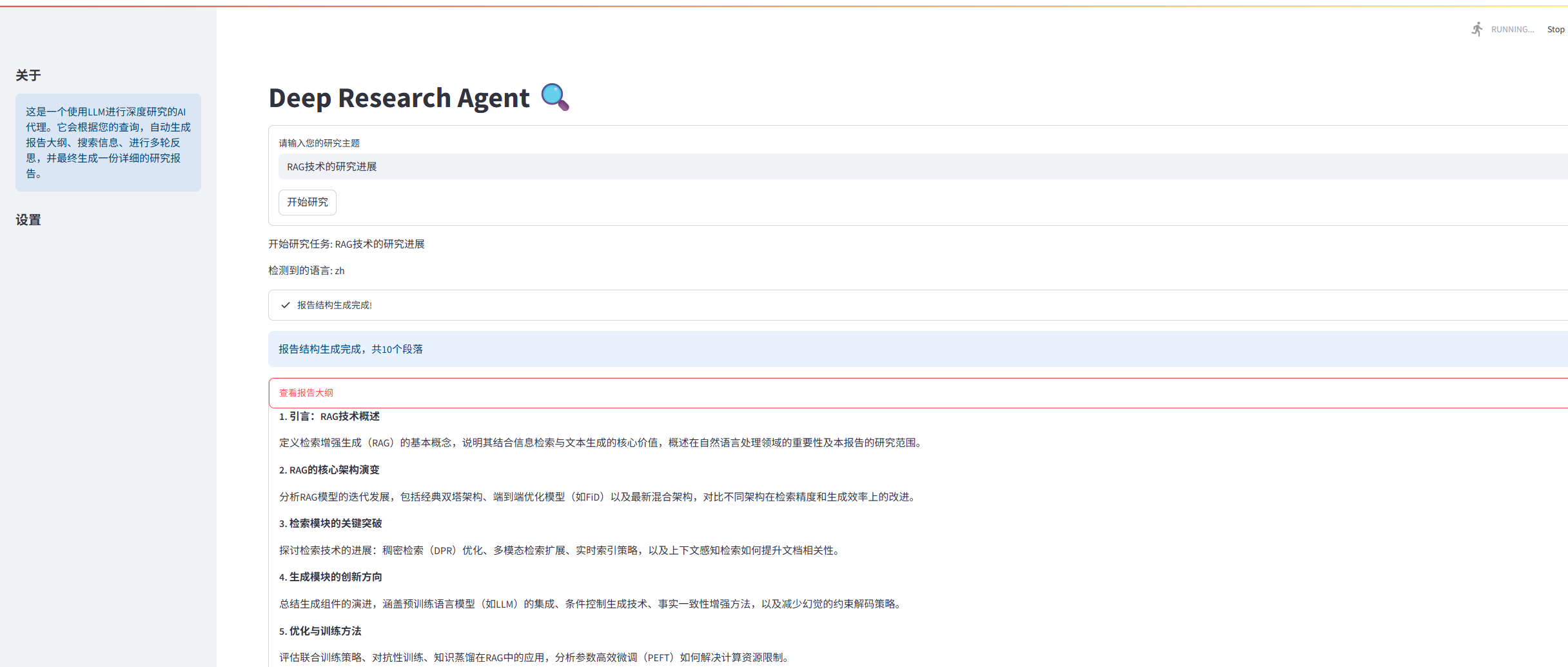
大功告成!现在就有了一份针对指定主题的深度研究报告。
总结与改进方向
恭喜!咱们成功地从零开始实现了一个深度研究Agent。不过,还有很多地方可以优化:
当前系统的局限性
- JSON输出稳定性:让系统稳定生成格式良好的JSON输出并不容易,推理模型在结构化输出方面通常表现不太稳定
- 模型选择策略:考虑到上述情况,在系统流程中为不同任务使用不同的模型可能更合理
- 搜索优化:搜索网页和对检索结果进行排序的方式还有很大改进空间
未来改进方向
- 动态回顾次数:让LLM自己决定是否还需要更多次回顾,而不是固定次数
- 参考文献系统:返回搜索时使用的链接,在报告的每个段落中提供参考文献
- 多模态支持:加入图片、表格等多媒体内容的处理能力
- 实时更新:支持对已生成报告的实时更新和修正
通过这个项目,咱们不仅搞懂了深度研究Agent的底层原理,还亲手实现了一个完整的系统。虽然和大厂的产品相比还有差距,但这个基础框架已经很不错了。
接下来可以根据自己的需求继续优化,比如加入更多的搜索源、优化Prompt策略、或者集成到自己的应用中。AI时代,动手能力永远是最宝贵的技能!
零基础如何高效学习大模型?
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









