







一、数据来源分析
1. 明确需求
明确需求明确采集的网站以及数据内容
- 网站 : https://weibo.com/u/3261134763
- 数据:评论相关数据
2. 抓包分析
通过浏览器的开发者工具分析对应的数据位置
- 打开开发者工具
- F12/右键点击检查选择network(网络)
- 刷新网页
- 让本网页的数据内容重新加载一遍
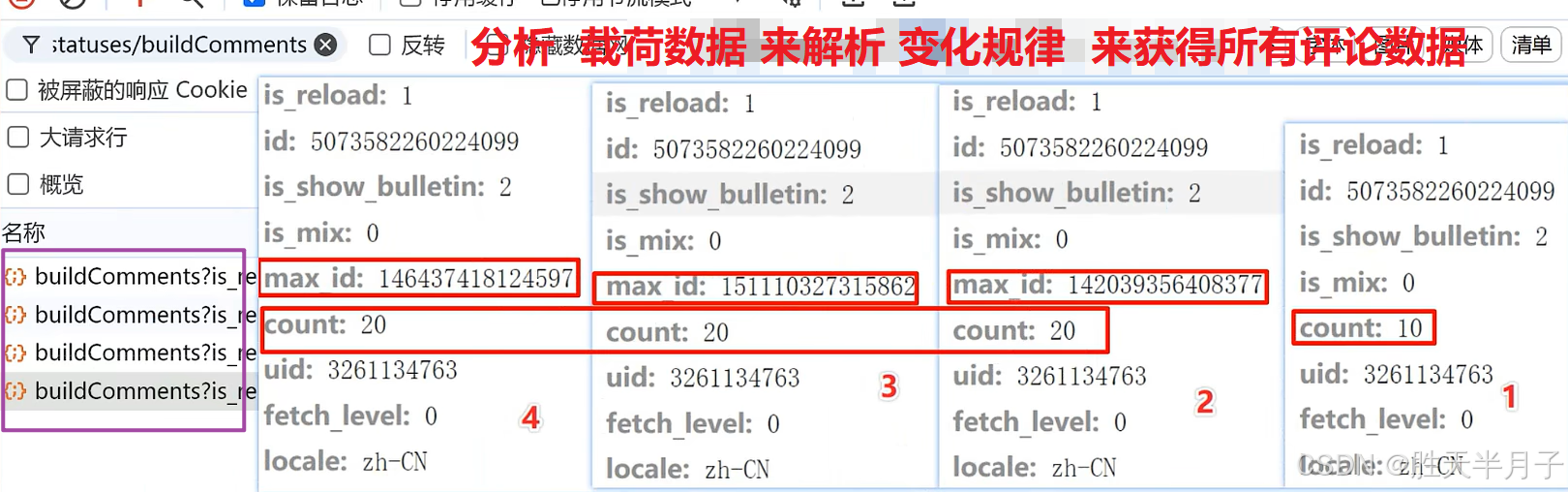
- 通过关键字搜索找到对应的数据位置
- 需要什么 搜索什么
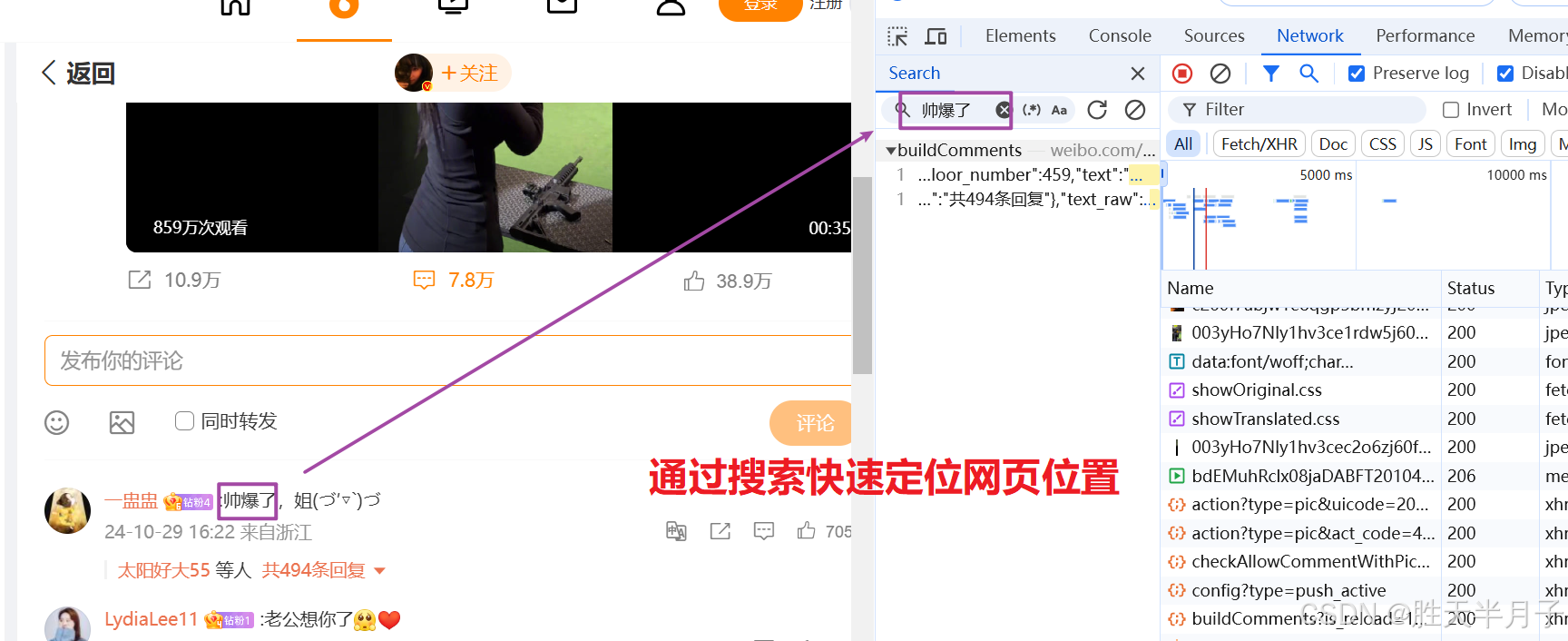
- 需要什么 搜索什么
- 数据包地址
https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=5094848836666976&is_show_bulletin=2&is_mix=0&count=20&type=feed&uid=3261134763&fetch_level=0&locale=zh-CN
二、代码实现步骤
1.发送请求
模拟浏览器对url发送请求
-
模拟浏览器
使用开发者工具中的参数内容 -
请求参数
GET请求查询参数(是直接在链接中就有)
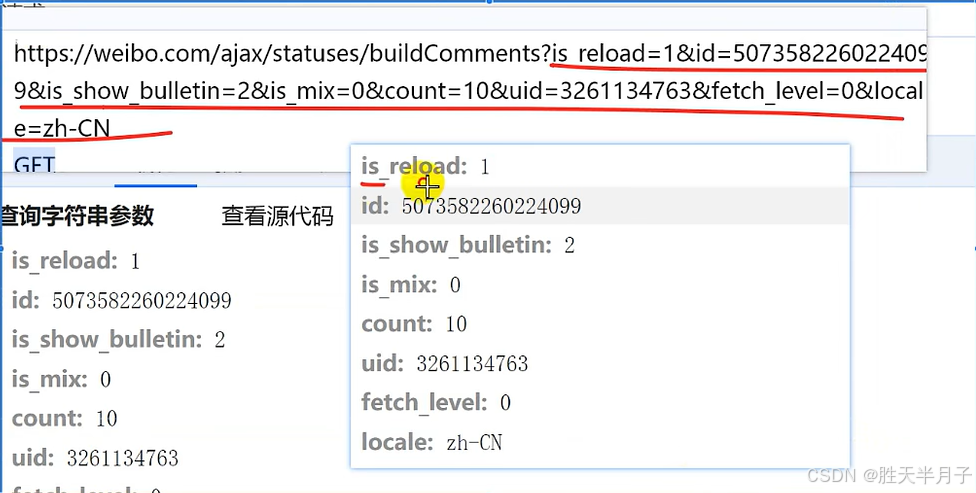
-
a.可以直接通过reqeusts模块get方法请求

-
b.额外构建查询参数,请求时候携带查询参数即可
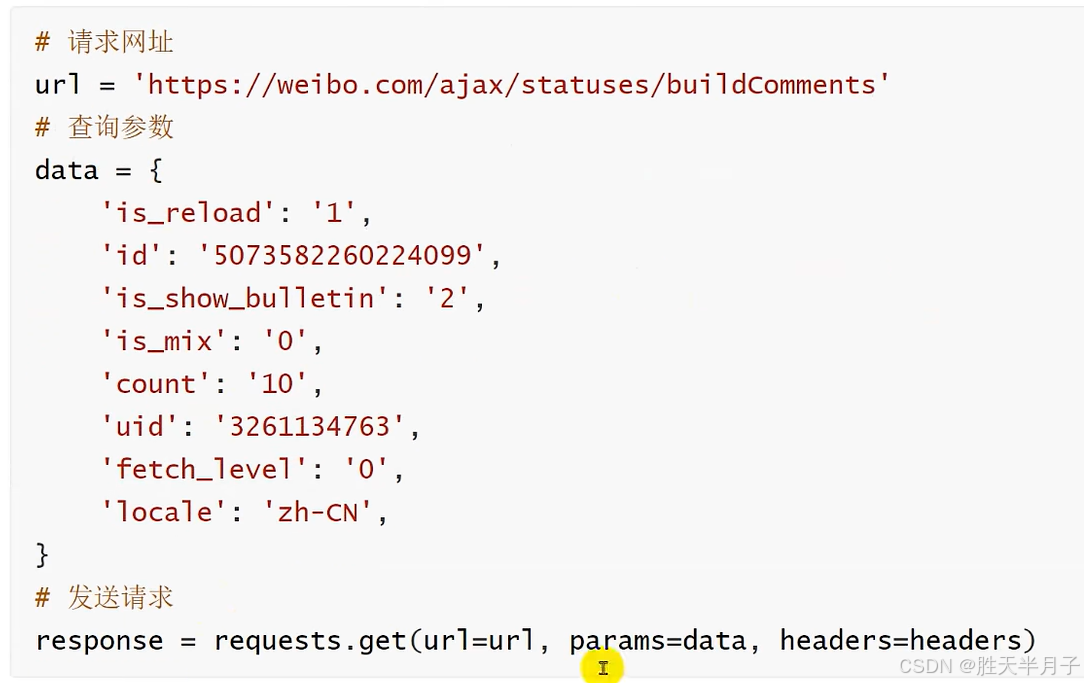
-
2.获取数据
获取服务器返回的响应数据
- 先获取可以看到的
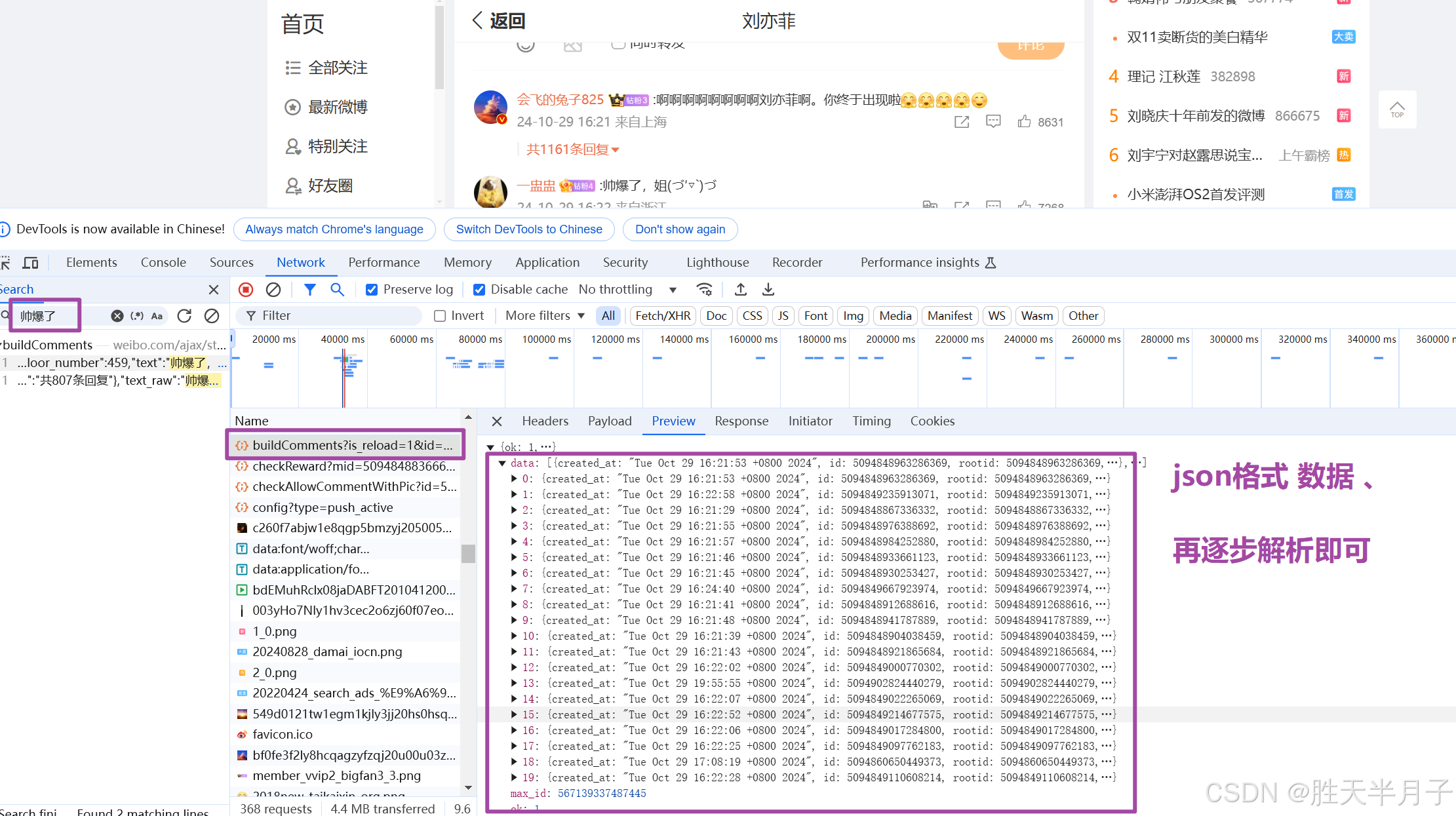
# 发送请求
headers ={
# cookie 常用于检测是否有登录账号
'cookie':'XSRF-TOKEN=wZ8bECpJlgJyRbWSyefxAaDp; SCF=AlZTrvx4aEpcEtUeDb6sIc9mpN0rLfEhGfC97di_e2wRzIMhcDuaF6bGoW2H7ieTyz_scbvU_tjjE-Imn60dbBg.; SUB=_2A25KJp01DeRhGeBG7VEU9S7MyDiIHXVpXZD9rDV8PUNbmtAGLVH7kW9NRhJk6IB8WfV1VqQziyFdnAS3bxt6KRuI; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5Av0xCkDDaiHBZ_nrFgJkx5JpX5KzhUgL.FoqRSoefSK57e0B2dJLoIEDzxEH8Sb-4BEHWBCH8SCHWxC-RBEH8SCHFxC-RSCH8SEHFBbHWxh54ehet; ALF=02_1732934246; WBPSESS=ajNkZa2PhdxrC0PPuU_zQFWFnZvPXbkCDhnBhExo1_W2n6PXRguOlwl2-22iNACZpnAxXZJu9DWzw6KBwWt5mpNMiJUxB0G4cYXXMBg3P6mB78-DWEEcUVbIUx0rCGZexw0aMiAQLntpouyF18cekg==',
# 用户代理 表示浏览器/设备的基本身份信息
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36'
}
# 请求网址
url ='https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=5094848836666976&is_show_bulletin=2&is_mix=0&count=10&uid=3261134763&fetch_level=0&locale=zh-CN'
# 发送请求
response = requests.get(url=url,headers=headers)
# 获取响应json数据
json_data = response.json()
# print(json_data)
# 保存文件
f = open('weibodata.csv','w',encoding='utf-8-sig',newline='')
csvwb = csv.DictWriter(f,fieldnames=['昵称','地区','性别','评论'])
csvwb.writeheader()
# 字典取值
data_list = json_data['data']
for index in data_list:
# print(index)
# 提取性别信息
sex = index['user']['gender']
if sex == 'f':
gender = '女'
elif sex =='m':
gender = '男'
else:
gender = '保密'
# 提取具体内容
dit ={
'昵称':index['user']['screen_name'],
'地区':index['source'].replace('来自',''),
'评论':index['text_raw'],
'性别':gender,
}
print(dit)
csvwb.writerow(dit)
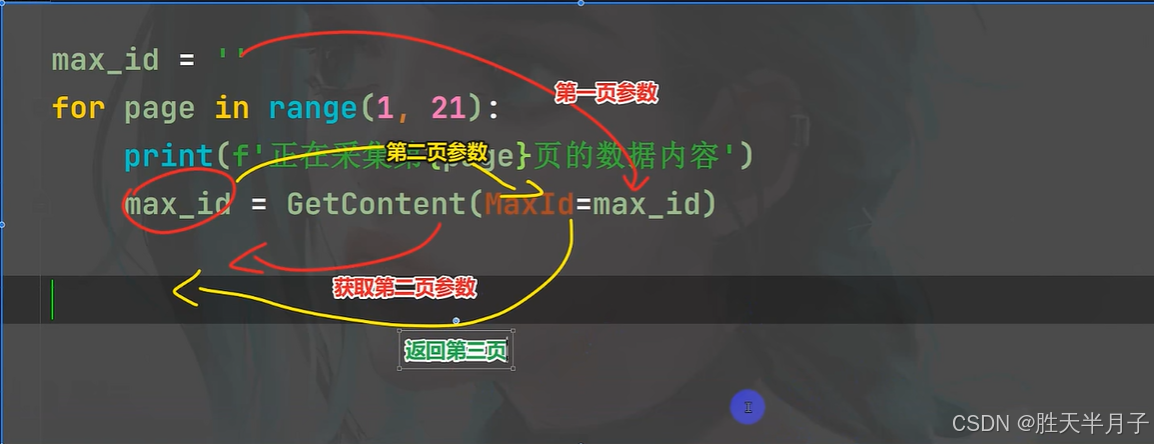
3.解析数据
提取我们需要的数据内容


max_id = ''
for page in range(1,21):
print(f'正在采集第{page}页的数据'%page)
max_id = getcontents(Maxid=max_id)
4.保存数据
提取数据保存到表格文件中
f = open('weibodata.csv','w',encoding='utf-8-sig',newline='')
csvwb = csv.DictWriter(f,fieldnames=['昵称','地区','性别','评论'])
csvwb.writeheader() # 写入列名 代码就是这么写的
csvwb.writerow(dit)
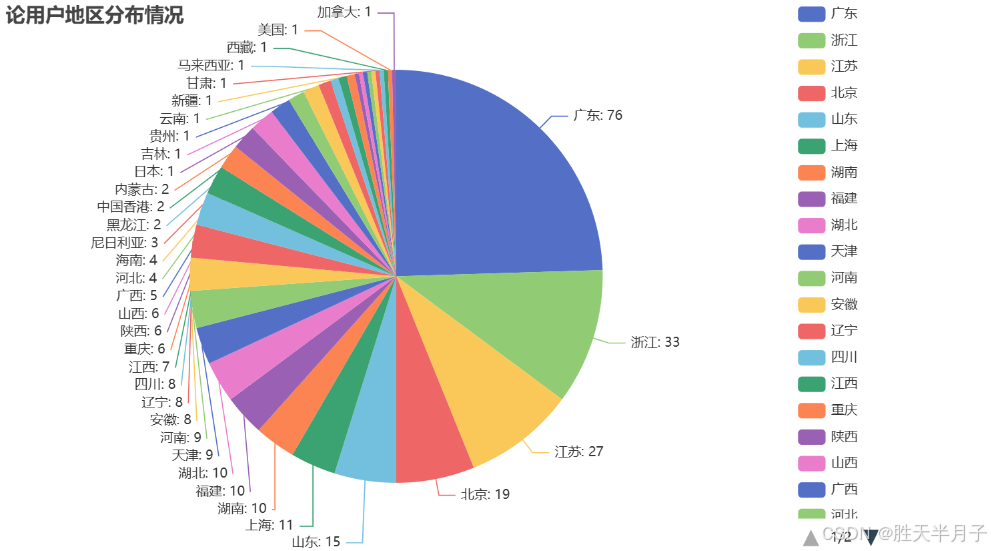
5. 数据可视化-pyecharts
x = wb['地区'].value_counts().index.tolist()
y = wb['地区'].value_counts().tolist()
c = (
Pie()
.add(
"",
[
list(z)
for z in zip(
# 传入数据内容
x,
y,
)
],
center=["40%", "50%"],
)
.set_global_opts(
# 设置可视化标题
title_opts=opts.TitleOpts(title="论用户地区分布情况"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# 使用 render 方法将图表渲染到 "pie_scroll_legend.html" 文件中
# .render("pie_scroll_legend.html")
)
c.render_notebook()


















 2192
2192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











