



包含编程籽料、学习路线图、爬虫代码、安装包等!【点击领取 100%免费!】

引言
微博作为中国最大的社交媒体平台之一,拥有海量的用户生成内容。这些数据对于舆情分析、用户行为研究等领域具有重要价值。本文将详细介绍如何使用Python编写爬虫,从微博上抓取数据,并进行简单的数据处理和存储。
1. 环境准备
在开始之前,我们需要确保已经安装了必要的Python库。常用的爬虫库包括:
Requests:用于发送HTTP请求。
BeautifulSoup 或 lxml:用于解析HTML。
Selenium:用于处理动态加载的内容。
Pandas:用于数据处理和存储。
你可以通过以下命令安装这些库:

2. 分析微博页面结构
在编写爬虫之前,我们需要先分析微博页面的结构。打开微博并查看你想要抓取的内容(如微博正文、发布时间、点赞数等),使用浏览器的开发者工具(F12)查看这些内容的HTML标签和属性。
2.1 静态页面分析
微博的部分内容是通过静态HTML加载的,我们可以直接通过Requests库获取页面内容,并使用BeautifulSoup或lxml解析。
2.2 动态页面分析
微博的许多内容(如评论、点赞数)是通过JavaScript动态加载的。对于这些内容,我们需要使用Selenium来模拟浏览器行为。
3. 编写爬虫
3.1 抓取静态内容
首先,我们尝试抓取微博的静态内容,如微博正文和发布时间。
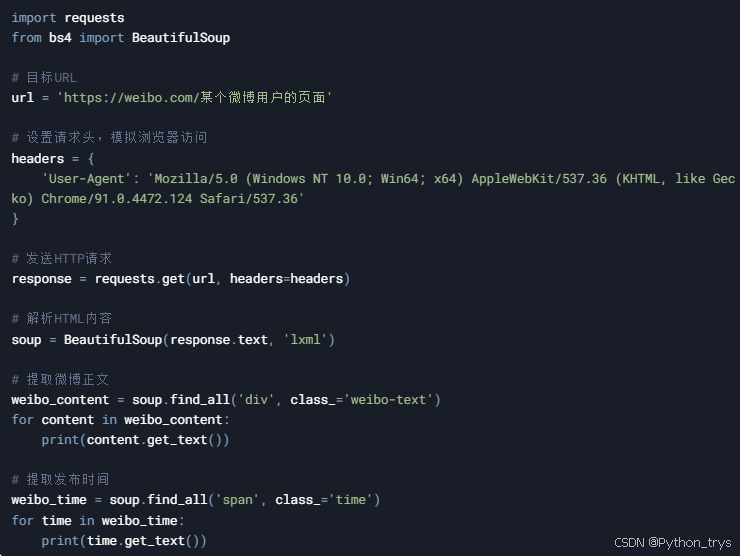
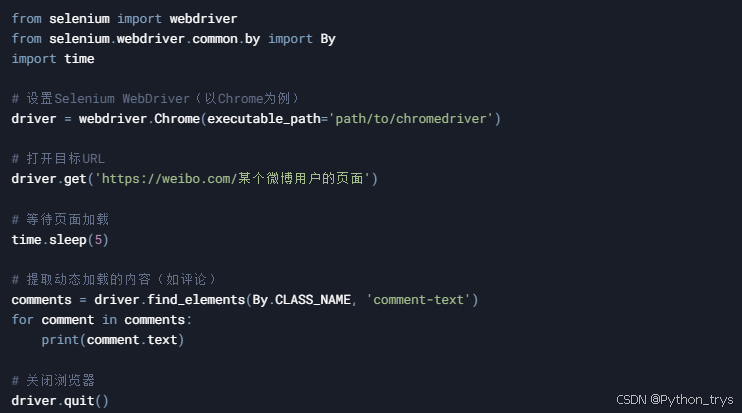
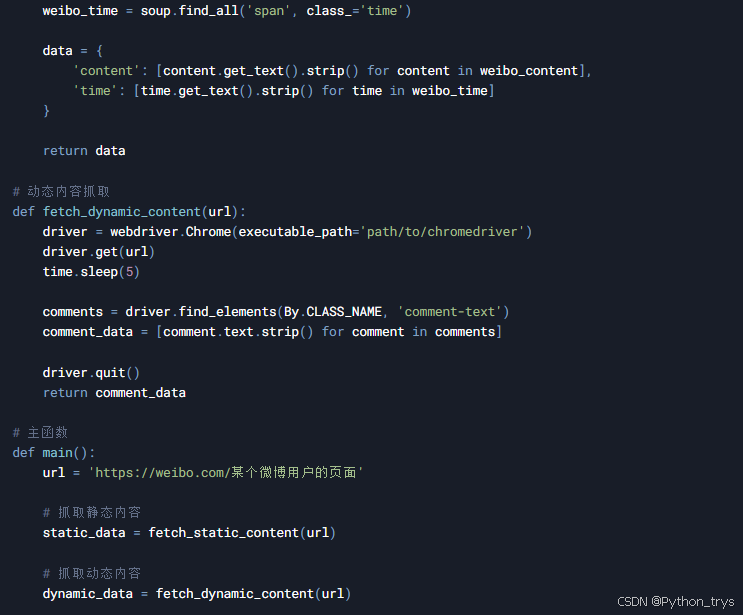
3.2 抓取动态内容
对于动态加载的内容,我们需要使用Selenium。
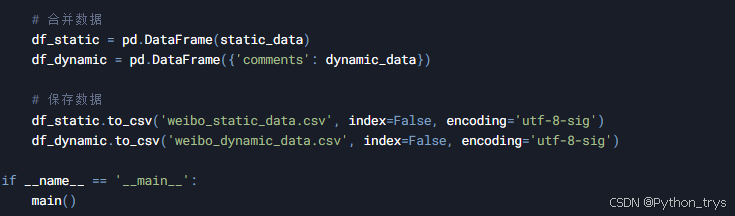
4. 数据处理与存储
抓取到的数据通常需要进行清洗和存储。我们可以使用Pandas来处理和存储数据。
4.1 数据清洗
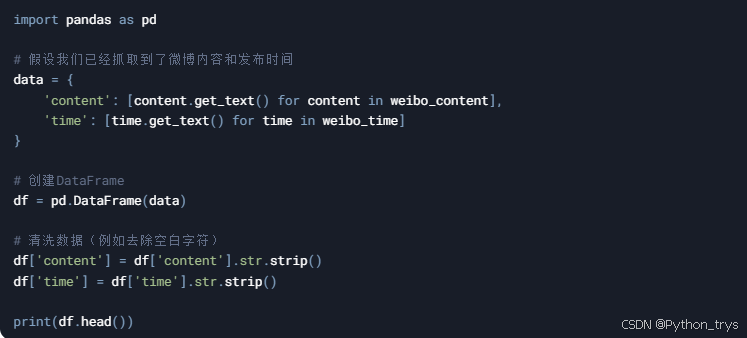
4.2 数据存储

5. 反爬虫策略
微博和其他网站通常会采取反爬虫措施,如IP封禁、验证码等。为了应对这些措施,我们可以采取以下策略:
设置请求头:模拟浏览器访问。
使用代理IP:避免IP被封禁。
限制请求频率:避免频繁访问导致封禁。
处理验证码:可以使用第三方验证码识别服务。
6. 完整代码示例
以下是一个完整的代码示例,结合了静态和动态内容的抓取,以及数据清洗和存储。
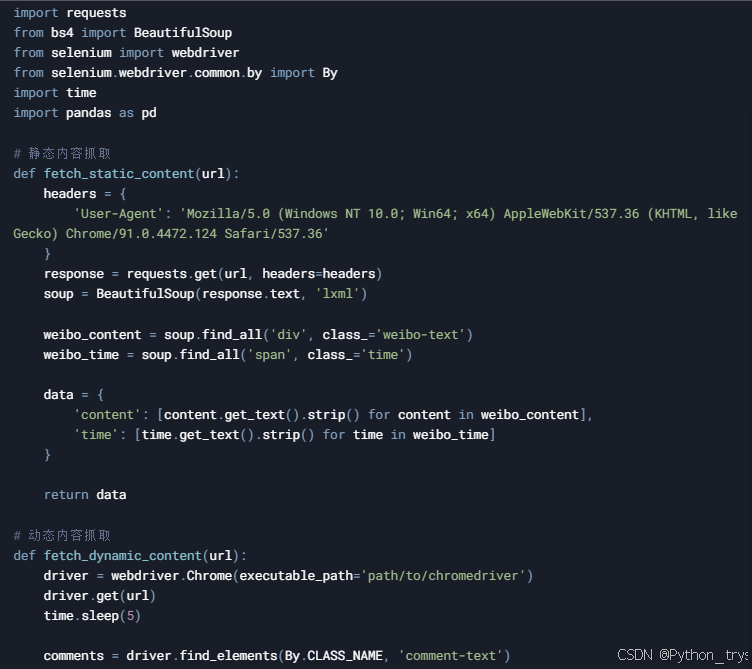
7. 结论
通过本文的介绍,你应该已经掌握了如何使用Python编写爬虫,从微博上抓取静态和动态内容,并进行数据清洗和存储。需要注意的是,爬虫行为应遵守相关法律法规和网站的使用条款,避免对目标网站造成不必要的负担。
最后:
希望你编程学习上不急不躁,按照计划有条不紊推进,把任何一件事做到极致,都是不容易的,加油,努力!相信自己!
文末福利
最后这里免费分享给大家一份Python全套学习资料,希望能帮到那些不满现状,想提升自己却又没有方向的朋友,也可以和我一起来学习交流呀。
包含编程资料、学习路线图、源代码、软件安装包等!【点击这里领取!】
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④ 华为出品独家Python漫画教程,手机也能学习


















 1535
1535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









