





大家好,欢迎阅读这份《智能体(AI+Agent)开发指南》!
在大模型和智能体快速发展的今天,很多朋友希望学习如何从零开始搭建一个属于自己的智能体。本教程的特点是 完全基于国产大模型与火山推理引擎实现,不用翻墙即可上手,非常适合国内开发者快速实践。
通过循序渐进的讲解,你将学会从 环境配置、基础构建、进阶功能到实际案例 的完整流程,逐步掌握智能体开发的核心技能。无论你是初学者还是有经验的工程师,相信这份教程都能为你带来启发。
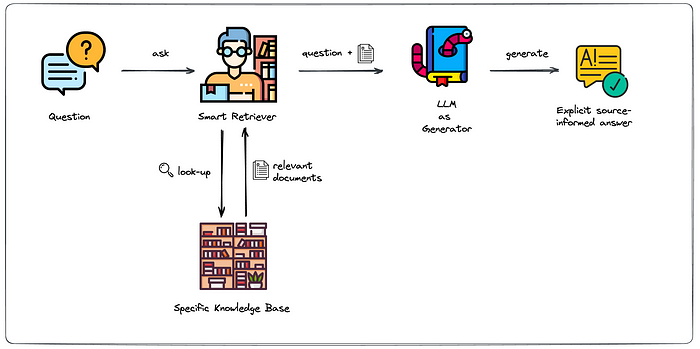
检索增强生成(RAG)是一种将文档检索与生成相结合的技术,允许LLM实时访问外部数据 。它融合了检索模型和生成模型的优势,为自然语言处理(NLP)领域设定了新的基准 。
一. RAG的核心机制
◦ 知识编码与存储:RAG系统首先将外部知识源(如文档、文章或FAQ)摄取进来 。大型文档通常被分割成更小、更易于管理的块,以提高检索的粒度和效率 。然后,每个文本块(有时是其他数据类型)通过嵌入模型处理,将其转换为高维向量嵌入,捕捉其语义含义。语义相似的概念在向量空间中将具有更接近的向量 。这些生成的向量嵌入,连同其对应的文本块和潜在的元数据,被存储在专门为高效存储和索引这些高维向量而设计的向量数据库中 。
◦ 查询嵌入与相似性搜索:当用户向LLM驱动的应用程序提出问题或查询时,该查询也会通过相同的嵌入模型转换为向量嵌入,生成用户意图的向量表示 。然后,该查询向量用于在向量数据库中执行相似性搜索。数据库利用高效的索引技术(如近似最近邻ANN)根据距离度量(如余弦相似度、欧几里得距离)快速定位与查询向量最相似的存储向量嵌入 。
◦ 上下文检索与增强生成:与最相似向量嵌入关联的文本块从向量数据库中检索出来 。这些检索到的文本块作为上下文添加到原始用户查询中,并作为提示输入LLM 。提示工程技术常用于指导LLM如何利用所提供的上下文 。LLM随后利用其预训练知识和检索到的上下文信息来生成更准确、相关和有依据的响应 。这种对向量数据库中特定知识的访问使得LLM能够提供超出其通用训练数据的答案,并根据用户的查询和可用信息进行定制 。
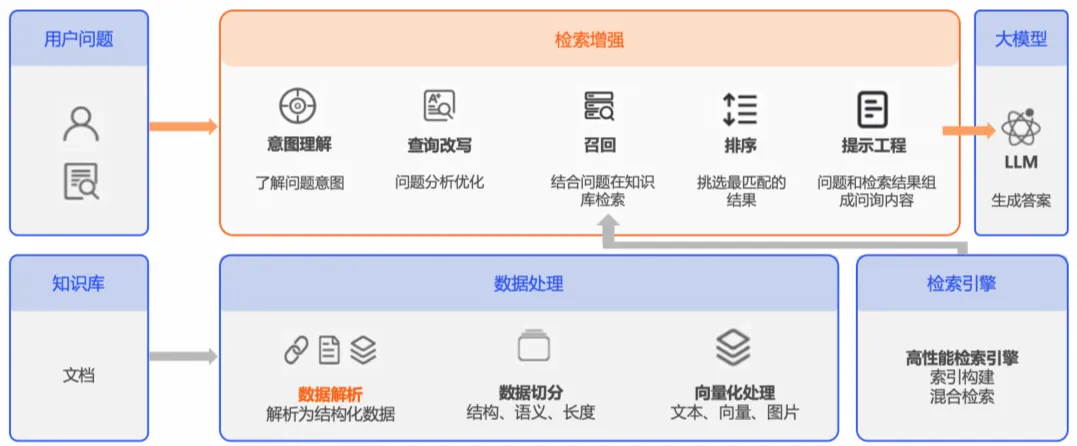
二. RAG的优势
RAG通过实时访问最新信息、提供动态上下文、减轻幻觉并生成准确输出,显著提高了LLM的性能和可靠性 。它还通过用单一微调取代传统任务特定模型训练的需求,实现了资源效率和计算节省 。
完整版中有RAG实践,敬请期待…
欢迎关注微信公众号:AIWorkshopLab,自动获取完整教程:智能体(AI+Agent)开发指南.pdf。



















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











