





大家好,欢迎阅读这份《智能体(AI+Agent)开发指南》!
在大模型和智能体快速发展的今天,很多朋友希望学习如何从零开始搭建一个属于自己的智能体。本教程的特点是 完全基于国产大模型与火山推理引擎实现,不用翻墙即可上手,非常适合国内开发者快速实践。
通过循序渐进的讲解,你将学会从 环境配置、基础构建、进阶功能到实际案例 的完整流程,逐步掌握智能体开发的核心技能。无论你是初学者还是有经验的工程师,相信这份教程都能为你带来启发。
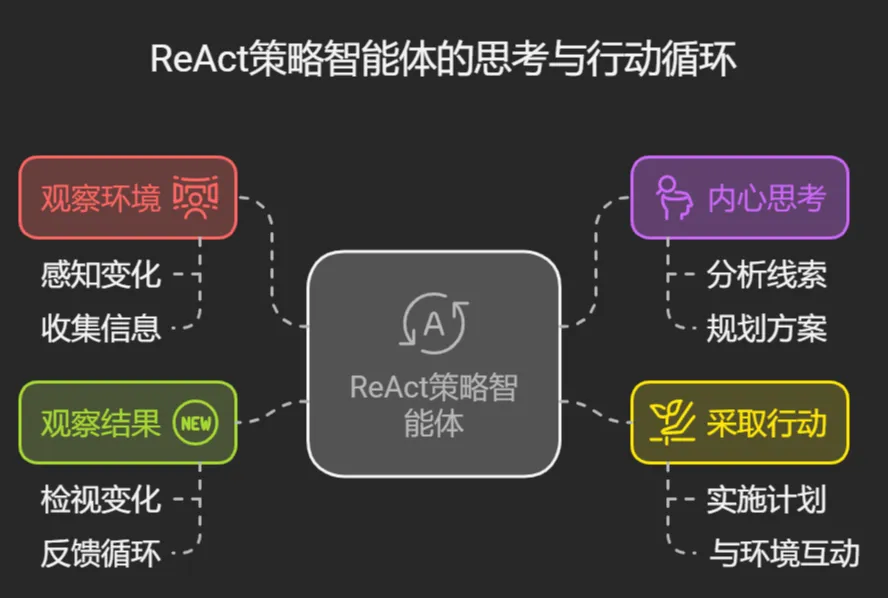
一. Interleaved Decomposition 方法
◦ COT咒语:Let’s think step-by-step
◦ 逐步展开,细化任务
▪ 不采用一次性完整分解,而是让模型在推理过程中,一步一步暴露子任务或中间步骤,以实现更细致、更贴近任务实际情况的动态规划。
◦ 结合语言模型的推理能力驱动分解
▪ 充分利用大模型(LLM)的自然语言推理能力来辅助任务分解过程。
◦ 推理与行动交替进行(Reasoning-Action循环)
▪ 模型交替输出**“思考”(Thought)和“行动”(Action)**,强化任务执行的过程控制能力。这种设计有助于避免模型陷入盲目生成,提高任务规划的正确性和反馈调整能力。
二. Reason and Act
• 背景:语言模型各自的短板
◦ CoT (Chain-of-Thought)
语言模型(LLM)本身非常擅长思考,通过类似“Chain-of-Thought”多步推理一步步得出答案,但是仅凭模型自身的知识推理,往往会出现“想当然”式的幻觉,答案未必符合外部真实情况。
◦ Act Only
模型在每一步只执行简单的动作(Action),从外界获得 Observation,但不具备连贯的思考过程,无法做复杂判断和策略规划,行为盲目、效率低。
◦ 总结
只会推理而没有外部信息来源,或者只会行动但缺乏思维,都限制了大模型在真实复杂任务中的表现。
• 核心想法:让模型一边“想”,一边“干”
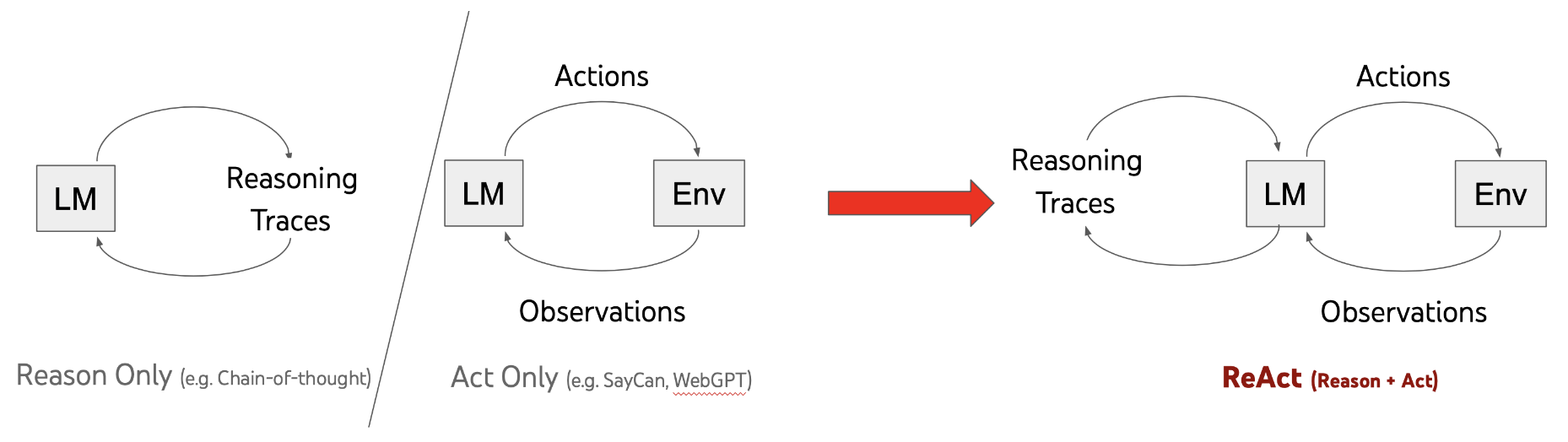
◦ ReAct 的核心理念就是:“思考 + 行动”结合起来,交替使用。
◦ 模型的每一步生成可以是:
▪ Thought(想法):模型的推理过程,比如“我需要查一下这是什么”;
▪ Action(行动):实际的行为,比如“调用搜索工具查资料”;
▪ Observation(观察):看到的结果,比如“搜索结果是…”。
这就像一个人边想边动手查资料,不断迭代,直到得到最终答案。
• 方法细节
1. 输入一个问题,模型先想几步,然后判断是否需要查外部信息;
2. 若需要,就生成一个“行动指令”,比如调用 Wikipedia 搜索;
3. 获取搜索结果后,模型再“思考”,更新策略;
4. 最后输出答案,整个过程像这样循环:
Thought → Action → Observation → Thought → … → Final Answer
5. 这种方式非常自然,也容易调试,因为人类能看到模型是怎么一步步得到答案的。
三. Fucntion call与ReAct的对比
1. LLM原生function call能力
提供function 定义
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather of an location, the user shoud supply a location first",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
}
},
"required": ["location"]
},
}
},
]
messages = [{"role": "user", "content": "How's the weather in Hangzhou?请给出思考过程"}]
调用时增加tools字段(结果返回finish_reason=“tool_calls”)
# openai
response = client.chat.completions.create(
model="deepseek/deepseek-chat/0324",
messages=messages,
tools=tools
)
#网关post请求方式
data = {
"stream": stream,
"context": context,
"messages": messages,
"tools": tools,
"model": model,
"provider": provider,
"version": version,
"base_llm_arguments": base_llm_arguments,
"extended_llm_arguments": extended_llm_arguments,
"sec_text": sec_text,
"retry_strategy": {
"retry_count": 5,
"timeout": 600
}
}
requests.post(url, headers=headers, json=data, timeout=(300, 3000))
增加了工具调用返回结果再次调用模型(结果返回finish_reason=“stop”)
messages.append(message)
messages.append({"role": "tool", "tool_call_id": tool.id, "content": "24℃"})
完整多轮对话流程
[
{
"role": "user",
"content": "How's the weather in Hangzhou?请给出思考过程"
},
{
"role": "assistant",
"content": "为了回答“杭州的天气如何?”这个问题,我将按照以下步骤进行:\n\n1. **理解问题**:用户询问的是杭州的天气情况。\n2. **获取天气数据**:我需要调用天气查询工具来获取杭州的实时天气信息。\n3. **返回结果**:将查询到的天气信息以清晰的方式呈现给用户。\n\n接下来,我将调用天气查询工具来获取杭州的天气数据。",
"tool_calls": [
{
"id": "call_yopdf2nee6r8blhsz7ulm0tj",
"function": {
"arguments": "{\"location\":\"Hangzhou\"}",
"name": "get_weather"
},
"type": "function",
"index": 0
}
]
},
{
"role": "tool",
"tool_call_id": "call_yopdf2nee6r8blhsz7ulm0tj",
"content": "24℃"
}
]
模型输出,finish_reson=“stop”
{
"role": "assistant",
"content": "杭州当前的天气是24℃,气温适宜。"
}
2. ReAct范式
在实际应用时,用户有时希望自定义输入输出格式或其他约束,此时利用大模型预置的方法会有不兼容的风险,因此需要自己设计prompt和格式约束来完成agent能力应用,system prompt中包含工具描述、输入字段定义、输出格式定义、历史信息以及其他约束。
System Prompt
SYSTEM
Answer the following questions as best you can. Specifically, you have access to the following APIs:
{API_list}
Remember:
Use the following format:
Thought: you should always think about what to do
Action: the action to take, should be search_places
Action Input: the input to the action, and the input parameters should be a
json dict string. Pay attention to the type of parameters
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times, max
7 times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
(2) Provide as much as useful information in your Final Answer.
(3) Do not make up anything, and if your Observation has no link, DO
NOT hallucihate one.
Start!
User
How's the weather in Hangzhou?请给出思考过程
模型输出Assistant
Thought: 用户询问了杭州的天气情况。我需要调用天气API来获取杭州的天气信息。
Action: get_weather
Action Input: {"location": "Hangzhou, China"}
调用工具得到Observation,Observation:24℃,这个Observation的处理方式可以自行设计
[
{
"role": "system",
"content": "..."
},
{
"role": "user",
"content": "How's the weather in Hangzhou?请给出思考过程"
},
{
"role": "assistant",
"content": "Thought: The user is asking about the weather in Hangzhou. I need to use the get_weather function to retrieve the current weather information for Hangzhou.\n\nAction: get_weather\nAction Input: {\"location\": \"Hangzhou, China\"}"
},
{
"role": "user",
"content": "Observation: 24℃"
}
]
模型输出Assistant
{
"role": "assistant",
"content": "Thought: I have retrieved the current weather information for Hangzhou. The temperature is 24℃.\n\nFinal Answer: The current weather in Hangzhou is 24℃."
}
四. ReAct进化-CodeAct
https://manus.im/app
1. Manus的执行步骤
• plan过程
• 分步执行过程
• 结果汇总
2. Manus技术原理

Manus其实是把四块积木拼在一起:
算力调度:好比租用云计算的"脑力",需要多少用多少
虚拟机:给每个任务单独开个"房间"干活,就像家里不同房间做不同事不会互相干扰
工具箱(Artifacts):做完任务会留下模板、代码等"工具",下次直接拿来用
AI小分队:内置专门处理编程、分析等场景的AI模型,像公司里不同部门的专家
借鉴CodeAct
3. CodeAct
• 什么是CodeAct?
CodeAct 是一种通用框架,用于让大模型(LLM)通过生成 Python 代码 来作为行动方式与环境交互。它将所有与环境的交互统一为 可执行的 Python 代码,模型通过执行代码获得反馈(如执行结果或错误信息),并根据反馈动态调整下一步操作,从而支持 多轮交互 与 复杂任务处理。
◦ 编写代码并不是最终目标,而是一种通用的方法来解决一般问题。
◦ 由于 LLMs(大语言模型)擅长编写代码,因此让智能体执行与其训练分布最契合的任务是合理的。
◦ 这种方法显著减少了上下文长度,并使复杂操作的组合成为可能。
• CodeAct的优势
◦ 动态执行与反馈调整
集成 Python 解释器,支持代码执行后根据观察结果(如执行输出或错误信息)动态调整或生成新的代码操作,实现多轮交互与任务自适应。
◦ 利用现有软件生态
通过 Python 生态的丰富软件包扩展操作空间,无需为特定任务手工开发工具。同时,借助软件自身的反馈机制(如报错信息),LLM 可自我调试提升任务完成率。
◦ 模型已有代码知识
现代 LLM 预训练中已大量使用代码数据,对编程语言结构有良好掌握,降低采用 CodeAct 的成本,提高代码生成质量与效率。
◦ 天然支持复杂逻辑
相较于 JSON 或结构化文本,代码具备控制流和数据流能力,能够通过变量存储中间结果、复用数据,并通过条件判断、循环等复杂逻辑组合多种工具,实现复杂任务的一步到位执行。
欢迎关注微信公众号:AIWorkshopLab,自动获取完整教程:智能体(AI+Agent)开发指南.pdf。



















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











