





一. vLLM简介
vLLM 是一个高效的推理和部署框架,专为大规模语言模型(LLM)优化。它采用 PagedAttention 技术,显著提高 GPU 显存利用率,支持高吞吐量推理。vLLM 兼容 Hugging Face Transformers 和 OpenAI API 接口,便于集成现有模型。其高效的 KV 缓存管理减少重复计算,适用于流式生成、批量处理和多用户推理场景。vLLM 还支持 FlashAttention,可进一步提升推理速度。相比传统推理框架,vLLM 具备更低的延迟和更高的并发能力,适用于部署 GPT-4 级别的大模型。
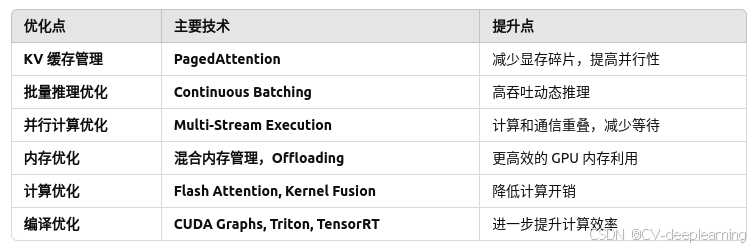
vLLM 通过这些优化,实现了 高吞吐量、低延迟、大模型推理加速,尤其适用于 多用户并发推理 和 大模型部署。
二. vLLM部署Qwen2.5 vl多模态大模型实战
- 要准备Qwen2.5 vl多模态大模型和对应的环境,可参考:
多模态大模型Qwen2.5 vl本地部署指南 - 安装vLLM
pip install vllm==0.7.3
- 测试代码
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
from qwen_vl_utils import process_vision_info
class QwenVLModel:
def __init__(self, model_path="./Qwen2.5-VL-7B-Instruct"):
self.model_path = model_path
self.llm = LLM(
model=self.model_path,
limit_mm_per_prompt={"image": 1, "video": 1},
tensor_parallel_size=1, # 设置为1以减少GPU内存使用
gpu_memory_utilization=0.9, # 控制GPU内存使用率
max_model_len=2048, # 限制最大序列长度
# quantization="awq", # 使用AWQ量化来减少内存使用
)
self.sampling_params = SamplingParams(
temperature=0.1,
top_p=0.001,
repetition_penalty=1.05,
max_tokens=512,
stop_token_ids=[],
)
self.processor = AutoProcessor.from_pretrained(self.model_path)
def generate(self, messages):
prompt = self.processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
image_inputs, video_inputs = process_vision_info(messages)
mm_data = {}
if image_inputs is not None:
mm_data["image"] = image_inputs
if video_inputs is not None:
mm_data["video"] = video_inputs
llm_inputs = {
"prompt": prompt,
"multi_modal_data": mm_data,
}
outputs = self.llm.generate([llm_inputs], sampling_params=self.sampling_params)
return outputs[0].outputs[0].text
if __name__ == "__main__":
from tqdm import tqdm
img_path = "/home/xxx/xxx/workspace/Qwen2.5/test.jpg"
prompt_str = "提取图片中的关键信息(包含身份证号码),输出的键值对尽量用中文输出,并以json形式输出"
image_messages = [
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": [
{
"type": "image",
"image": img_path,
"min_pixels": 256 * 28 * 28,
"max_pixels": 1280 * 28 * 28,
},
{"type": "text", "text": prompt_str},
],
},
]
model = QwenVLModel()
output_text = model.generate(image_messages)
print(output_text)
输出结果:
{
"银行名称": "招商银行",
"卡号": "5236498888888888",
"持卡人姓名": "XIAO ZHAO",
"银行卡类型": "MasterCard"
}




















 1779
1779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











