




今日任务:
- 打开信贷数据集数据(csv文件、excel文件)
- 查看数据(尺寸信息、查看列名等方法)
- 查看空值
- 众数、中位数填补空值
- 利用循环补全所有列的空值
数据的读取
读取数据:使用pandas库中的read_csv('path')方法读取。
- 注意数据存放的位置,分为绝对路径与相对路径。此外,对于Windows系统,要注意路径的书写方式:使用‘r’;使用反斜杠‘/’;使用双重斜杠‘\\’
- 注意读取时的编码方式,encoding = 'utf-8'等
- 若读取Excel,需先安装openpyxl库
查看数据:了解数据的大概信息。
- data.head(n):读取前n行数据,默认n=5
- data.tail(n):读取倒数n行数据,默认n=5
- type():查看类别,对于data为dataframe类型,每列为series类型;dtypes属性
import pandas as pd
data = pd.read_csv(r"D:\机器学习\Python训练营代码【2025.7.30版本】\data.csv") #读取
data.head() #读前5行
data.tail() #读后5行数据信息的查看
对于DataFrame类型和Series类型,大部分的方法和属性是共享的,因此可以通过对data或某列数据调用属性和方法,对data中的数据信息有更深入的了解:
- info():概览信息,得到列名、非空值、数据类型等信息。
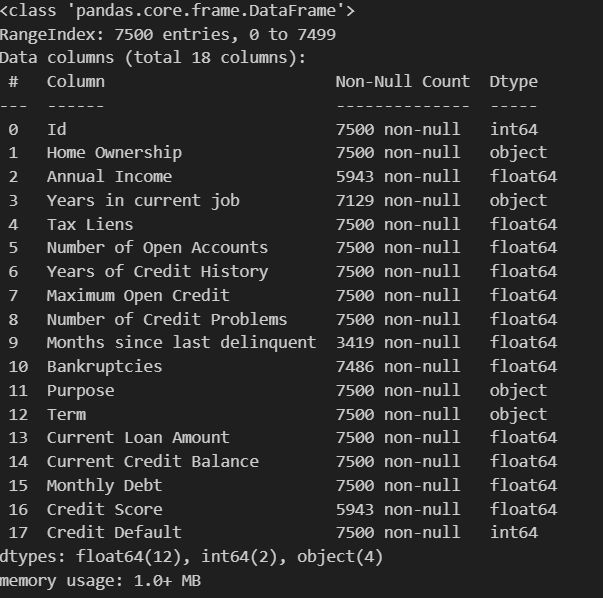
- isnull():查看缺失值,返回布尔矩阵(dataframe),True 即为空值,False为非空值。此外,统计空值时,可使用isnull().sum()。
- describe():数值列的统计信息
- shape:得到(行数,列数)的尺寸信息
- columns:所有列名
- dtypes:data type,查看列数据类型;data.dtypes / data['A'].dtype
data.shape #查看尺寸,(7500,18)
data.columns #查看所有列名
data.info() #得到概览信息
data.describe() #得到统计信息
data.isnull().sum() #统计空值得到的概览信息:
缺失值的填补(单列)
对于缺失值的填补方法一般有统计量填补(均值mean/中位数median/众数mode)、模型预测填补(KNN、随机森林)等。此处以众数、中位数填补为例。
对某列填补缺失值的步骤如下:
- 计算:该列的中位数median()或众数mode()。对于众数,返回多个值,一般取第一个
- 填充:fillna(value,inplace=False)。inplace默认为False,即返回新的,不修改原数据;反之,True即为修改原数据
- 检查:isnull().sum(),是否存在空值
#中位数填充
median_filled = data['Annual Income'].median() #计算中位数
a=data['Annual Income'].fillna(median_filled) #填充,返回新列
a.isnull().sum() #检查#众数填充
mode_filled = data['Annual Income'].mode() #计算众数
mode_filled #众数返回多个频次相同的值
mode_fill = mode_filled[0] #一般选择第一个
b = data['Annual Income'].fillna(mode_fill) #填充
b.isnull().sum() #检查填补所有数值型缺失值(多列)
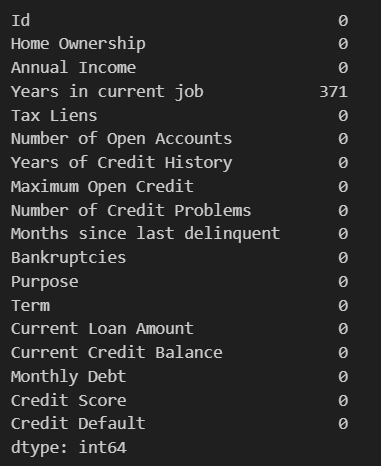
由于对于数值型的缺失值,选择填充方法一致的情况下,每次流程基本相同,故而采用循环的方法实现对所有数值型缺失值的填充。
采用for循环对所有列名进行遍历,利用判断语句进行筛选:(1)需要为数值型的列(2)该列存在缺失值(3)按流程填充(4)检查。虽然df.columns可以直接遍历,但是遍历过程存在修改dataframe,故而将df.columns通过tolist()方法转换为列表形式进行处理。
#循环方法同一方法填充多列
columns_list = data.columns.tolist() #列名转换为列表,方便遍历
columns_list
for column in columns_list: #遍历列名
#筛选条件:数值型且存在空值
if data[column].dtype != 'object' and data[column].isnull().sum()>0:
medians = data[column].median() #计算
data[column].fillna(medians,inplace=True) #填充,修改原数据
data.isnull().sum() #检查最终数值型数据填充结果:

















 1343
1343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









