






 本文介绍了S3D(separable 3D convolutions)模型,一种用于视频分类的高效方法。通过将3D卷积分解为时域和空间域分离的卷积,S3D网络在降低模型复杂性的同时提高了性能。实验表明,S3D网络在某些情况下优于I3D网络,并且通过分析权值分布和特征聚类,证明了其有效性和时序信息的重要性。文章还提供了代码分析,详细解释了模型结构和实现。
本文介绍了S3D(separable 3D convolutions)模型,一种用于视频分类的高效方法。通过将3D卷积分解为时域和空间域分离的卷积,S3D网络在降低模型复杂性的同时提高了性能。实验表明,S3D网络在某些情况下优于I3D网络,并且通过分析权值分布和特征聚类,证明了其有效性和时序信息的重要性。文章还提供了代码分析,详细解释了模型结构和实现。
S3D(separable 3D CNN)是ECCV 2018发表的关于视频分类模型,核心思想就是将原来的I3D网络替换为时域和空间域分离进行卷积的S3D网络,相比I3D网络,不仅模型参数量得到大幅减少,而且性能也得到提升。
原文Rethinking Spatiotemporal Feature Learning:Speed-Accuracy Trade-offs in Video Classification
原文
Introduction
第一段,概述视频分类问题和现有数据集Sports-1M [5], Kinetics [6], Something-something [7], ActivityNet [8], Charades [9]
第二段,视频分类关键的三要素:时间,空间和计算经济性(1) how best to represent spatial information (i.e., recognizing the appearances of objects); (2) how best to represent temporal information (i.e., recognizing context, correlation and causation through time); and (3) how best to tradeoff model complexity with speed, both at training and testing time.
第三段,引入I3D网络,性能高但是模型计算经济性差。提出三个问题:
- 是否需要3D网络?
- 是否有必要时空融合提取特征,能否分离操作?
- 如何提高效率和准确度
为了回答问题1,作者基于I3D网络提出了如下一组网络,对比相同框架下3D和2D网络结构。



为了回答问题2,作者提出了时空分离的S3D网络,即卷积核由
k
t
×
k
×
k
k_{t} \times k \times k
kt×k×k替换为
1
×
k
×
k
1 \times k \times k
1×k×k和
k
t
×
1
×
1
k_{t} \times 1 \times 1
kt×1×1两组
为了回答问题3,作者基于前两点的发现,提出了一个a spatio-temporal gating mechanism进一步提高模型的精度,即S3D-G模型
Related work
I3D网络,计算量巨大,前人对问题1的一些尝试(mixed convolutional models),以及分离卷积操作(separable convolutions),特征门控(feature gating)
Experiment Setup
介绍Kinetics和Something-something两个数据集
从256x256 cropped 网络输入 224x224
对Kinetics前60Ksteps学习率0.1, 70K steps lr=0.01, 80K steps lr=0.001
对Something-something 10K lr=0.1
Network surgery
Replacing all 3D convolutions with 2D
分别利用I3D和I2D网络在两个数据集上,采用正序和反序两种方式进行网络训练。结果如下,I2D在正序和反序的表现相近,说明结果与时序相关性不高(主要由静态场景信息提供)。对I3D网络在Something-something数据集上表现差距很大的原因可能是由于Something-something数据集需要fine-grained distinctions between visually similar action categories. (比如Pushing something from left to right” and “Pushing something from right to left)

- 倒叙输入网络说明,时间序列输出对结果预测的重要性
Replacing some 3D convolutions with 2D
主要对比Bottom-Heavy-I3D model和Top-Heavy-I3D models,结果如下发现Top-Heavy-I3D models性能要优越很多,说明替换底层的3D卷积层对网络影响更低,且计算量大幅减少。

Analysis of weight distribution of learned filters
对3d卷积操作中不同时间的权值分布统计,可以看到越底层的卷重中间时刻的方差越大,顶层,不同权重分布方差越大。说明越顶层的3d卷积操作越有意义。

Separating temporal convolution from spatial convolutions
对比S3D与I3D发现性能有所提升


tSNE analysis of the features
利用聚类算法比较模型网络特征提取的效果,上一层可以看出S3D网络的卷积层越顶层的特征分离效果越明显;
横向比较也可以看出S3D网络是特征分离最理想的网络

Spatio-temporal feature gating
y
=
σ
(
W
x
+
b
)
⊙
x
y=\sigma(W x+b) \odot x
y=σ(Wx+b)⊙x
x
∈
R
n
x \in \mathcal{R}^{n}
x∈Rnusually learned at final embedding layers close to the logit output
代码
model.py
总的来看S3D模型还是相同简单明了的直通式卷积网络
总体结构分析
本代码基于github pytorch程序。参考的这个代码比较好的是带有pretrained weight文件。原文主要网络基于I3D模型,如下这幅图,并提出了一个S3D的思想。

按照管理先打印看看模型的结构。首先我们对比上一个图重点看看一级(标红字)模块,分别对应上图中的主干模型中的模块。关键点使用使用S3D模块,以及3D temporal separable Inception block,即mixed_*模块替换原来的3d卷积,其他结构保持不变。这里只列出了部分内容。
S3D(
(base): Sequential(
(0): SepConv3d(
(conv_s): Conv3d(3, 64, kernel_size=(1, 7, 7), stride=(1, 2, 2), padding=(0, 3, 3), bias=False)
(bn_s): BatchNorm3d(64, eps=0.001, momentum=0.001, affine=True, track_running_stats=True)
(relu_s): ReLU()
(conv_t): Conv3d(64, 64, kernel_size=(7, 1, 1), stride=(2, 1, 1), padding=(3, 0, 0), bias=False)
(bn_t): BatchNorm3d(64, eps=0.001, momentum=0.001, affine=True, track_running_stats=True)
(relu_t): ReLU()
)
(1): MaxPool3d(kernel_size=(1, 3, 3), stride=(1, 2, 2), padding=(0, 1, 1), dilation=1, ceil_mode=False)
(2): BasicConv3d(
(conv): Conv3d(64, 64, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn): BatchNorm3d(64, eps=0.001, momentum=0.001, affine=True, track_running_stats=True)
(relu): ReLU()
)
(3): SepConv3d(
(conv_s): Conv3d(64, 192, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=False)
(bn_s): BatchNorm3d(192, eps=0.001, momentum=0.001, affine=True, track_running_stats=True)
(relu_s): ReLU()
(conv_t): Conv3d(192, 192, kernel_size=(3, 1, 1), stride=(1, 1, 1), padding=(1, 0, 0), bias=False)
(bn_t): BatchNorm3d(192, eps=0.001, momentum=0.001, affine=True, track_running_stats=True)
(relu_t): ReLU()
)
(4): MaxPool3d(kernel_size=(1, 3, 3), stride=(1, 2, 2), padding=(0, 1, 1), dilation=1, ceil_mode=False)
(5): Mixed_3b(
(branch0): Sequential(
(0): BasicConv3d(
(conv): Conv3d(192, 64, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn): BatchNorm3d(64, eps=0.001, momentum=0.001, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(branch1): Sequential(
(0): BasicConv3d(
(conv): Conv3d(192, 96, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn): BatchNorm3d(96, eps=0.001, momentum=0.001, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): SepConv3d(
(conv_s): Conv3d(96, 128, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=False)
(bn_s): BatchNorm3d(128, eps=0.001, momentum=0.001, affine=True, track_running_stats=True)
(relu_s): ReLU()
(conv_t): Conv3d(128, 128, kernel_size=(3, 1, 1), stride=(1, 1, 1), padding=(1, 0, 0), bias=False)
(bn_t): BatchNorm3d(128, eps=0.001, momentum=0.001, affine=True, track_running_stats=True)
(relu_t): ReLU()
)
)
(branch2): Sequential(
(0): BasicConv3d(
(conv): Conv3d(192, 16, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn): BatchNorm3d(16, eps=0.001, momentum=0.001, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): SepConv3d(
(conv_s): Conv3d(16, 32, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=False)
(bn_s): BatchNorm3d(32, eps=0.001, momentum=0.001, affine=True, track_running_stats=True)
(relu_s): ReLU()
(conv_t): Conv3d(32, 32, kernel_size=(3, 1, 1), stride=(1, 1, 1), padding=(1, 0, 0), bias=False)
(bn_t): BatchNorm3d(32, eps=0.001, momentum=0.001, affine=True, track_running_stats=True)
(relu_t): ReLU()
)
)
(branch3): Sequential(
(0): MaxPool3d(kernel_size=(3, 3, 3), stride=1, padding=1, dilation=1, ceil_mode=False)
(1): BasicConv3d(
(conv): Conv3d(192, 32, kernel_size=(1, 1, 1), stride=(1, 1, 1), bias=False)
(bn): BatchNorm3d(32, eps=0.001, momentum=0.001, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
)
BasicConv3d & SepConv3d
还是从最小的模块开始实现,这个模块运用最多的两个基本单元就是 BasicConv3d 和 SepConv3d。
BasicConv3d中包括了 nn.Conv3d, nn.BatchNorm3d, nn.ReLU三组操作。
SepConv3d对应将卷积核由
k
t
×
k
×
k
k_{t} \times k \times k
kt×k×k替换为
1
×
k
×
k
1 \times k \times k
1×k×k和
k
t
×
1
×
1
k_{t} \times 1 \times 1
kt×1×1两组
class BasicConv3d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride, padding=0):
super(BasicConv3d, self).__init__()
self.conv = nn.Conv3d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, bias=False)
self.bn = nn.BatchNorm3d(out_planes, eps=1e-3, momentum=0.001, affine=True)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class SepConv3d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride, padding=0):
super(SepConv3d, self).__init__()
self.conv_s = nn.Conv3d(in_planes, out_planes, kernel_size=(1,kernel_size,kernel_size), stride=(1,stride,stride), padding=(0,padding,padding), bias=False)
self.bn_s = nn.BatchNorm3d(out_planes, eps=1e-3, momentum=0.001, affine=True)
self.relu_s = nn.ReLU()
self.conv_t = nn.Conv3d(out_planes, out_planes, kernel_size=(kernel_size,1,1), stride=(stride,1,1), padding=(padding,0,0), bias=False)
self.bn_t = nn.BatchNorm3d(out_planes, eps=1e-3, momentum=0.001, affine=True)
self.relu_t = nn.ReLU()
def forward(self, x):
x = self.conv_s(x)
x = self.bn_s(x)
x = self.relu_s(x)
x = self.conv_t(x)
x = self.bn_t(x)
x = self.relu_t(x)
return x
Mixed_*
由于是参考的3D temporal separable Inception block,结构上具有inception 的特点。
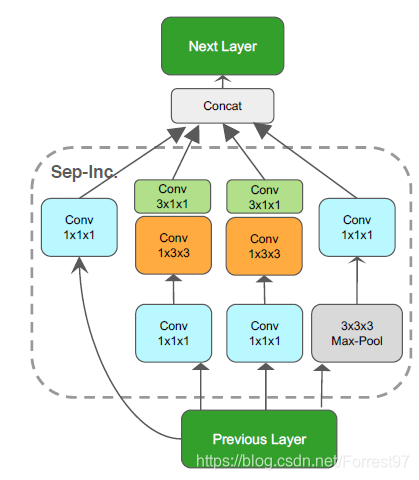
我们以其中第一个Mixed_3b模块为例,其中包括四个分支,分别采取上图中的四组不同的卷积操作后,再进行拼接形成模块输出。
class Mixed_3b(nn.Module):
def __init__(self):
super(Mixed_3b, self).__init__()
self.branch0 = nn.Sequential(
BasicConv3d(192, 64, kernel_size=1, stride=1),
)
self.branch1 = nn.Sequential(
BasicConv3d(192, 96, kernel_size=1, stride=1),
SepConv3d(96, 128, kernel_size=3, stride=1, padding=1),
)
self.branch2 = nn.Sequential(
BasicConv3d(192, 16, kernel_size=1, stride=1),
SepConv3d(16, 32, kernel_size=3, stride=1, padding=1),
)
self.branch3 = nn.Sequential(
nn.MaxPool3d(kernel_size=(3,3,3), stride=1, padding=1),
BasicConv3d(192, 32, kernel_size=1, stride=1),
)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
out = torch.cat((x0, x1, x2, x3), 1)
return out
模型主干
有基本的网络模块,接下来只需要按照图中的总体框架将模块按照特定的参数进行堆叠上即可。是不是正如之前所说的其实很简单呀。
class S3D(nn.Module):
def __init__(self, num_class):
super(S3D, self).__init__()
self.base = nn.Sequential(
SepConv3d(3, 64, kernel_size=7, stride=2, padding=3),
nn.MaxPool3d(kernel_size=(1,3,3), stride=(1,2,2), padding=(0,1,1)),
BasicConv3d(64, 64, kernel_size=1, stride=1),
SepConv3d(64, 192, kernel_size=3, stride=1, padding=1),
nn.MaxPool3d(kernel_size=(1,3,3), stride=(1,2,2), padding=(0,1,1)),
Mixed_3b(),
Mixed_3c(),
nn.MaxPool3d(kernel_size=(3,3,3), stride=(2,2,2), padding=(1,1,1)),
Mixed_4b(),
Mixed_4c(),
Mixed_4d(),
Mixed_4e(),
Mixed_4f(),
nn.MaxPool3d(kernel_size=(2,2,2), stride=(2,2,2), padding=(0,0,0)),
Mixed_5b(),
Mixed_5c(),
)
self.fc = nn.Sequential(nn.Conv3d(1024, num_class, kernel_size=1, stride=1, bias=True),)
def forward(self, x):
y = self.base(x)
y = F.avg_pool3d(y, (2, y.size(3), y.size(4)), stride=1)
y = self.fc(y)
y = y.view(y.size(0), y.size(1), y.size(2))
logits = torch.mean(y, 2)
return logits
main.py
大家可以下载权重后进行测试,科学上午不方便的同学可以从网盘上下载
链接:https://pan.baidu.com/s/1sNdJ7zvF-Io23kOy6-UVpA
提取码:xd1x
import os
import numpy as np
import cv2
import torch
from model import S3D
def main():
''' Output the top 5 Kinetics classes predicted by the model '''
path_sample = './sample'
file_weight = './S3D_kinetics400.pt'
class_names = [c.strip() for c in open('./label_map.txt')]
num_class = 400
model = S3D(num_class)
print(model)
# load the weight file and copy the parameters
if os.path.isfile(file_weight):
print ('loading weight file')
weight_dict = torch.load(file_weight)
model_dict = model.state_dict()
for name, param in weight_dict.items():
if 'module' in name:
name = '.'.join(name.split('.')[1:])
if name in model_dict:
if param.size() == model_dict[name].size():
model_dict[name].copy_(param)
else:
print (' size? ' + name, param.size(), model_dict[name].size())
else:
print (' name? ' + name)
print (' loaded')
else:
print ('weight file?')
model = model.cuda()
torch.backends.cudnn.benchmark = False
model.eval()
list_frames = [f for f in os.listdir(path_sample) if os.path.isfile(os.path.join(path_sample, f))]
list_frames.sort()
# read all the frames of sample clip
snippet = []
for frame in list_frames:
img = cv2.imread(os.path.join(path_sample, frame))
img = img[...,::-1]
snippet.append(img)
clip = transform(snippet)
with torch.no_grad():
logits = model(clip.cuda()).cpu().data[0]
preds = torch.softmax(logits, 0).numpy()
sorted_indices = np.argsort(preds)[::-1][:5]
print ('\nTop 5 classes ... with probability')
for idx in sorted_indices:
print (class_names[idx], '...', preds[idx])
def transform(snippet):
''' stack & noralization '''
snippet = np.concatenate(snippet, axis=-1)
snippet = torch.from_numpy(snippet).permute(2, 0, 1).contiguous().float()
snippet = snippet.mul_(2.).sub_(255).div(255)
return snippet.view(1,-1,3,snippet.size(1),snippet.size(2)).permute(0,2,1,3,4)
if __name__ == '__main__':
main()
这里想对torch 动态图模型的输入尺寸说明两点:
CNN网络参数只与卷积核的尺寸,以及相邻特征层的层数有关,因此理论和实际操作,网络可以对不同尺寸的图像输入进行特征提取。- 同时由于模型最后使用了logits = torch.mean(y, 2)对时域维度的信号取平均,所以网络输入的画面帧数可以是任意大于16的数(网络中有4组stride=2的操作)
100画面输入预测结果
Top 5 classes … with probability
riding a bike … 0.9911095
biking through snow … 0.0060706125
riding mountain bike … 0.0017217693
riding unicycle … 0.0008350074
motorcycling … 0.00024636489
16帧画面输入预测结果
Top 5 classes … with probability
riding a bike … 0.9764031
riding unicycle … 0.014563507
biking through snow … 0.00781723
motorcycling … 0.0007634801
riding mountain bike … 0.00043132144

















 4230
4230




 到【灌水乐园】发言
到【灌水乐园】发言







