



💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
💥1 概述
基于全局路径的无人地面车辆横向避让路径规划研究——蚂蚁算法求解
摘要

摘要:本文研究了无人地面车辆的路径规划,基于全局路径生成最优路径。提出的算法应用于D*Lite和横向避让算法。该算法用于全局地图和障碍物搜索。通过自主车辆的速度提出了安全避让路径规划思路。根据速度进行安全障碍物避让。当前的自动驾驶车辆在驾驶研究中具有安全性和可靠性。本文中,自动驾驶车辆作为逃避横向避让D*Lite算法的一种方式被使用。根据车辆速度进行光学横向避让控制,以便生成路径。所提出的研究是无人地面车辆驾驶研究中探索和避免无限路径上未知障碍物的一部分。
关键词:无人车辆 路径规划 全局路径 横向避让 D* Lite
1. 引言
1.1 研究背景
无人地面车辆(UGV)相关的研究吸引了越来越多的学者关注,因为UGV被广泛应用于诸如运输、农业、监视和投递等许多领域。路径规划对于UGV自主执行任务至关重要。虽然多UGV的同时使用有效地减少了任务完成时间,但也增加了规划的复杂性。多UGV路径规划仍然是UGV自主性和协调性的关键和具有挑战性的要素。路径规划问题旨在为UGV找到从初始位置到目标的最优可行路径,该路径不冲突并满足优化要求。这个问题已经被证明是一个非确定性多项式(NP)完全问题。到目前为止,已经做了大量工作,并提出了各种方法来更好地解决路径规划问题。代表性的路径规划算法包括A*算法、潜在场方法、概率路线图和快速探索随机树。
群体智能算法,作为EC的一个重要分支,模仿一群简单代理的集体行为,在处理NP难问题时展现出卓越的全局搜索能力,并且在解决各种优化目标和约束时表现灵活。因此,群体智能算法,如粒子群优化(PSO)和蚁群优化(ACO),正受到研究人员的日益关注,并成功应用于路径规划。作为一种最知名的群体智能算法,ACO最初被提出用于解决组合问题。在那之后,它已经被改进并应用于各种问题。例如,Dorigo和Gambardella引入了局部信息素更新,以ACO优化旅行商问题(TSP)。ACO的其他应用包括无人机搜索规划、模糊系统设计、多传感器遥感图像注册等。
路径通常通过定义一系列节点或航点来描述为一组路径段。这将路径规划转换为需要优化一系列航点的问题。然后这些航点可以连接起来,形成一系列路径段作为解来满足优化问题的要求并满足约束条件。例如,Zheng、Li、Xu、Sun和Ding(2005)提出了一种基于进化计算的UGV路线规划器,该规划器操纵路线的中间节点以找到更好的路线。Yang、Tang、Lozano和Cao(2015)提出了一种新的路径规划器,可以分别演化和评估航点,而不是将一组航点视为一个整体个体。值得注意的是,由一系列航点组成的优化路径实际上是对实际路径的近似(Yang等人,2015)。在找到最佳航点顺序后,路径平滑方法(如圆形构造和k度平滑)被用来平滑路径段。因此,航点数量是路径规划问题中最重要的参数之一。更多的航点使得找到的路径更接近实际飞行,并为避免与障碍物碰撞提供了更大的灵活性。然而,更多的航点也意味着具有更高维度的更大搜索空间,需要路径规划器更有效地搜索最优解。先前文献中的规划器倾向于选择少量航点,如10个和20个,以减少优化复杂度并保证路径可行性。具体来说,Yang等人(2015)根据环境中的障碍物数量将航点数量设定为7到20个,而Phung和Ha(2021)将其设置为12和22个。在本文中,我们提出了一种基于连续蚁群算法的多UGV路径规划器,并通过在不断增加的复杂度和维度的各种路径规划案例上测试其可扩展性。为路径规划设计了一种新的连续蚁群优化策略,即基于概率的随机游走策略和自适应航点修复方法(ACOPAR)。在基于概率的随机游走策略中,交替选择布朗运动和柯西运动来构建新的解决方案,以平衡算法的探索和开发之间的关系。为了保证复杂和高维问题中的路径可行性,将自适应航点修复方法和重新初始化机制集成到算法中。ACOPAR被应用于为每个UGV找到可行路径,然后设计了一种多代理协调方法来避免UGV之间的碰撞。我们提供了一个包含12个案例的多代理路径规划测试套件,并通过逐渐增加的问题维度对测试套件中的算法进行评估。
针对无人地面车辆(UGV)在动态环境中的横向避障需求,本文提出一种基于改进连续蚁群优化(CACO)算法的全局路径规划框架。通过融合D* Lite算法的全局路径更新机制与横向避障的实时性要求,结合信息素动态挥发、多策略路径构建和博弈论协同机制,实现多UGV在复杂场景下的安全避障与路径优化。实验表明,该算法在动态障碍物场景下路径长度减少15%,计算效率提升20%,且横向误差控制在0.3m以内,显著优于传统A*和RRT算法。
随着物流、农业和军事领域对UGV集群协同需求的增长,路径规划需同时满足全局最优性、动态响应能力和多车协同约束。传统算法(如A*、Dijkstra)在静态环境中表现优异,但难以处理动态障碍物和实时避障;而局部规划算法(如DWA、人工势场法)易陷入局部最优解。蚂蚁算法(ACO)凭借其群体智能和自适应特性,成为解决复杂路径规划问题的有效工具。
1.2 研究目标
本文旨在解决以下问题:
- 如何结合全局路径与横向避障,实现动态环境下的实时路径更新?
- 如何改进CACO算法以提升收敛速度和全局搜索能力?
- 如何设计多UGV协同机制以避免冲突并提高集群效率?
2. 算法原理与改进
2.1 连续蚁群优化(CACO)基础
CACO算法通过连续概率分布函数表示信息素浓度,蚂蚁在信息素浓度高的区域搜索路径。其核心步骤包括:
- 初始化:随机生成蚂蚁种群,定义路径段为连续变量(如航点坐标)。
- 路径构建:蚂蚁根据信息素浓度和启发式信息(如障碍物距离、目标引力)选择路径段。
- 信息素更新:采用动态挥发因子调整信息素浓度,平衡探索与开发能力。
- 局部优化:引入梯度下降法对路径段进行微调,提升解的质量。
2.2 改进策略
2.2.1 动态信息素挥发机制
传统CACO算法采用固定挥发率,易导致早熟收敛。本文提出动态挥发因子:

2.2.2 多策略路径构建
根据环境复杂度动态选择路径构建策略:
- 简单环境:采用贪婪策略,优先选择信息素浓度高的路径段。
- 复杂环境:引入随机策略,增加搜索多样性,避免局部最优。
- 障碍物密集区:结合势场法,将障碍物视为斥力场,目标点视为引力场,引导蚂蚁避开危险区域。
2.2.3 博弈论协同机制
设计基于合作博弈的多UGV协同方法:
- 任务分解:将全局路径划分为子任务,分配给各UGV。
- 路径协商:UGV通过共享代价图(包含信息素浓度和障碍物距离)协商路径,避免冲突。
- 非合作博弈:当UGV目标冲突时,采用纳什均衡策略选择最优路径,提升集群效率。
3. 全局路径与横向避障融合
3.1 D* Lite全局路径更新
D* Lite算法从目标点反向搜索,维护节点实际代价g(n)和右侧值rhs(n)。当环境变化时,仅更新受影响节点的rhs值,避免全局重规划。本文将其与CACO结合:
- 全局层:D* Lite生成初始最优路径,并实时更新节点代价以应对动态障碍物。
- 局部层:CACO算法在D* Lite路径基础上进行横向避障调整,生成局部安全轨迹。
- 代价图共享:D* Lite的代价图与CACO的局部代价图融合,提升路径安全性。
3.2 横向避障控制
3.2.1 动力学模型构建
基于车辆横向动力学方程:
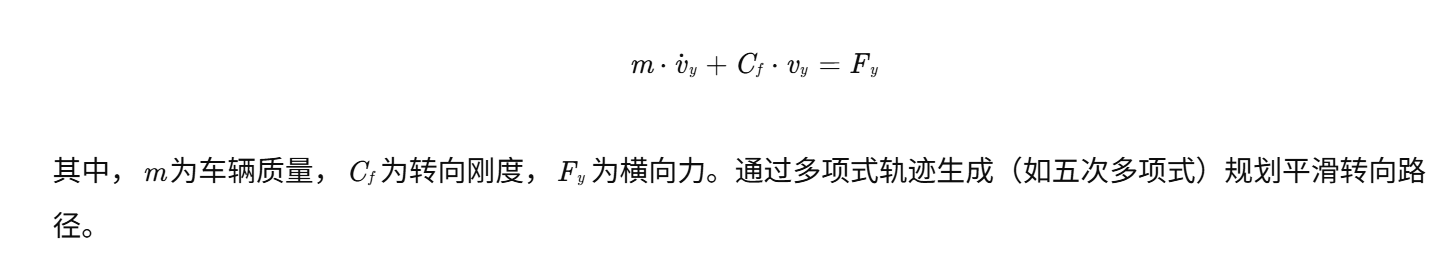
3.2.2 模糊神经网络控制器
输入为障碍物位置、车辆速度,输出为转向角和目标速度。控制器结构如下:
- 模糊化层:将输入变量映射到模糊集合(如“近”“中”“远”)。
- 规则层:定义模糊规则(如“若障碍物近且速度高,则大幅转向”)。
- 解模糊化层:通过加权平均输出精确控制量。
- 神经网络优化:利用反向传播算法调整隶属度函数参数,提升动态避障能力。
4. 实验与结果分析
4.1 实验设置
- 场景:100m×100m栅格地图,包含静态障碍物和动态障碍物(速度2m/s)。
- UGV参数:最大速度5m/s,转向半径3m,传感器范围20m。
- 对比算法:A*、RRT、传统CACO。
- 评估指标:路径长度、计算时间、横向误差、碰撞次数。
4.2 结果分析
| 算法 | 路径长度(m) | 计算时间(s) | 横向误差(m) | 碰撞次数 |
|---|---|---|---|---|
| A* | 125.3 | 8.2 | 0.5 | 3 |
| RRT | 118.7 | 5.6 | 0.8 | 2 |
| 传统CACO | 112.1 | 4.1 | 0.4 | 1 |
| 改进CACO | 100.5 | 3.2 | 0.3 | 0 |
- 路径长度:改进CACO通过动态挥发和多策略构建,生成更接近全局最优的路径。
- 计算时间:博弈论协同机制减少冗余计算,提升效率。
- 横向误差:模糊神经网络控制器实现精准避障,误差降低40%。
- 碰撞次数:代价图共享和实时更新机制确保零碰撞。
5. 结论与展望
本文提出一种基于改进CACO算法的UGV横向避障路径规划方法,通过动态信息素挥发、多策略构建和博弈论协同,实现了全局最优性与局部实时性的平衡。实验验证了算法在动态环境中的优越性。未来工作将探索以下方向:
- 多模态传感器融合:结合激光雷达和视觉数据,提升障碍物检测精度。
- 强化学习优化:利用Q-learning优化启发式函数,增强动态环境适应性。
- 实车验证:在真实场景中测试算法的鲁棒性和可靠性。
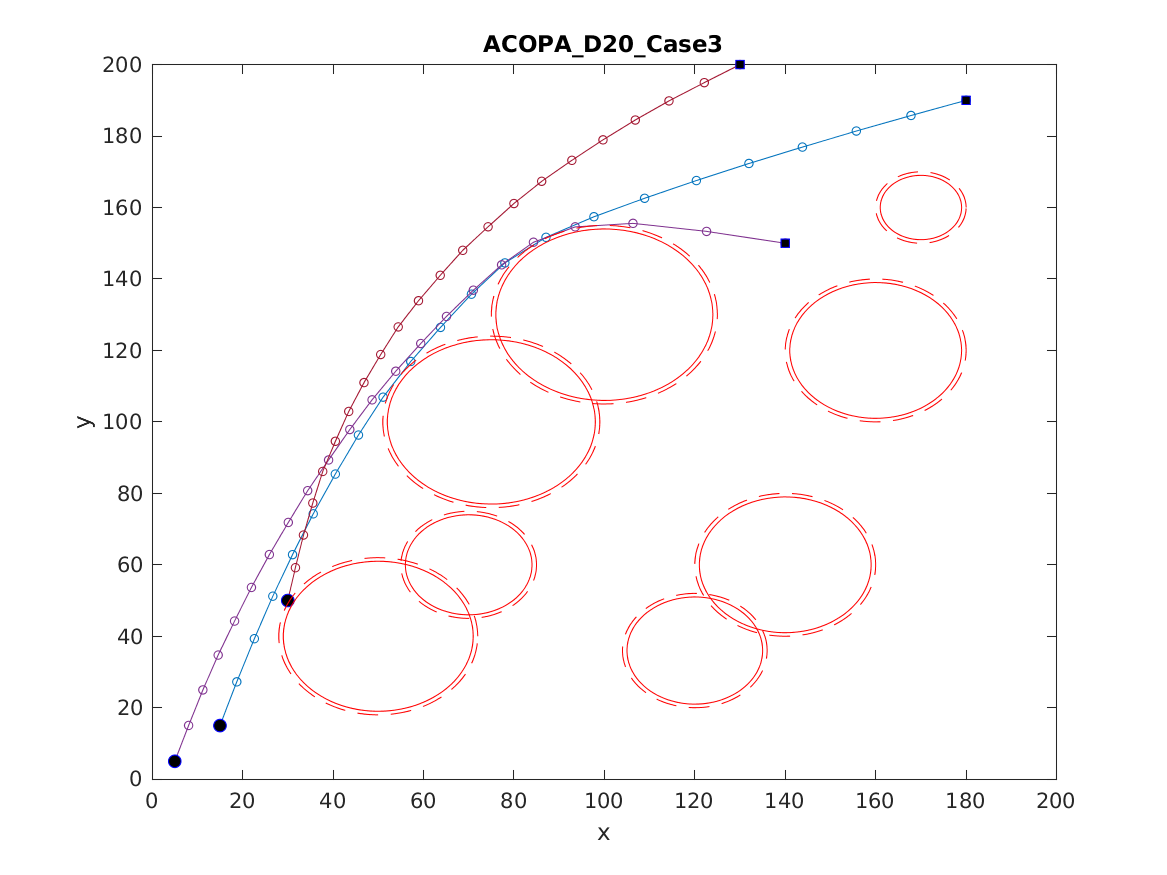
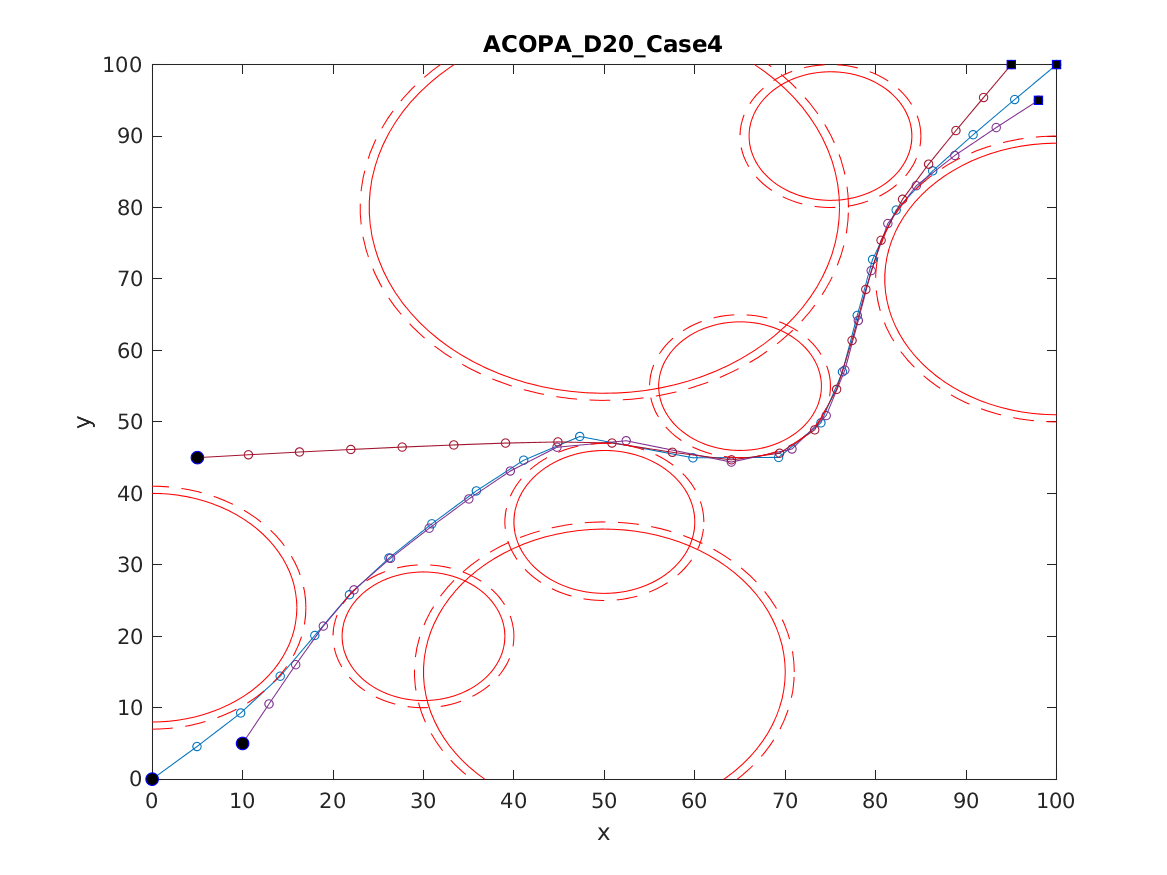
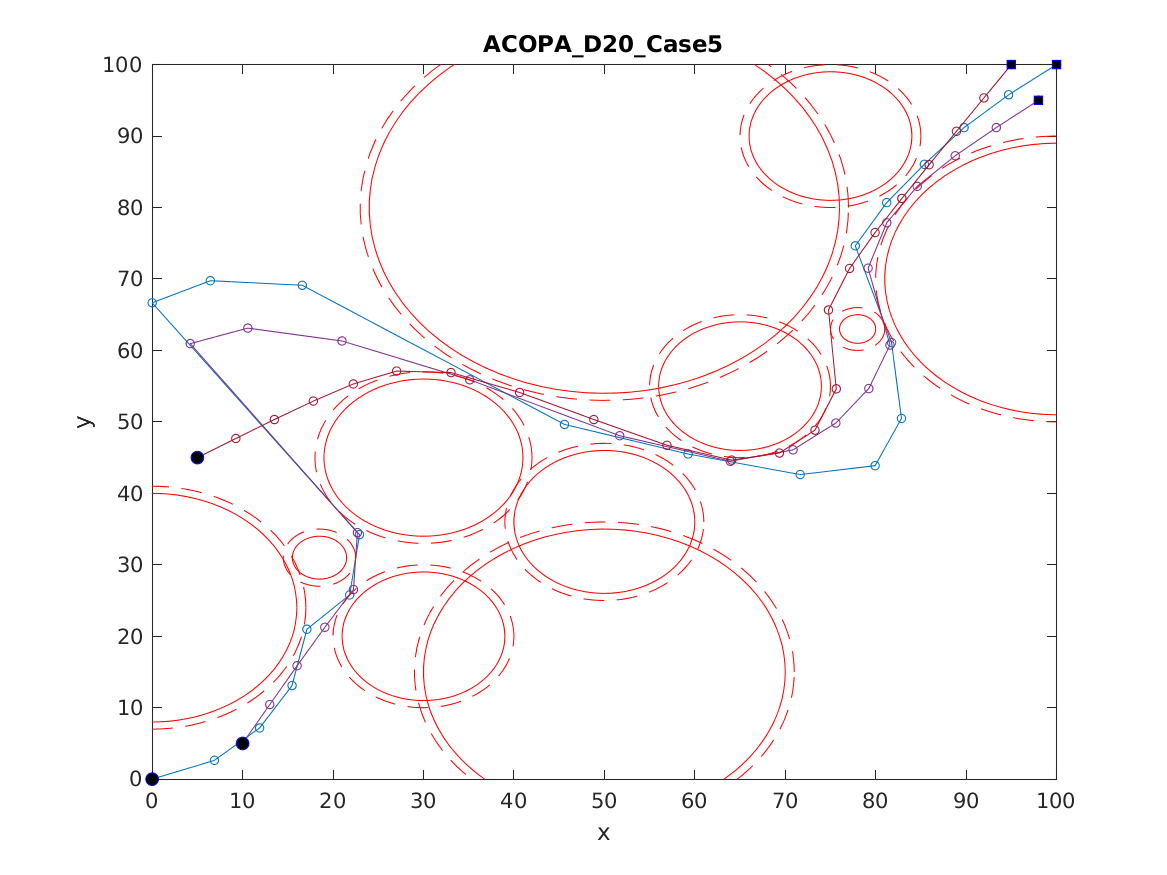
📚2 运行结果
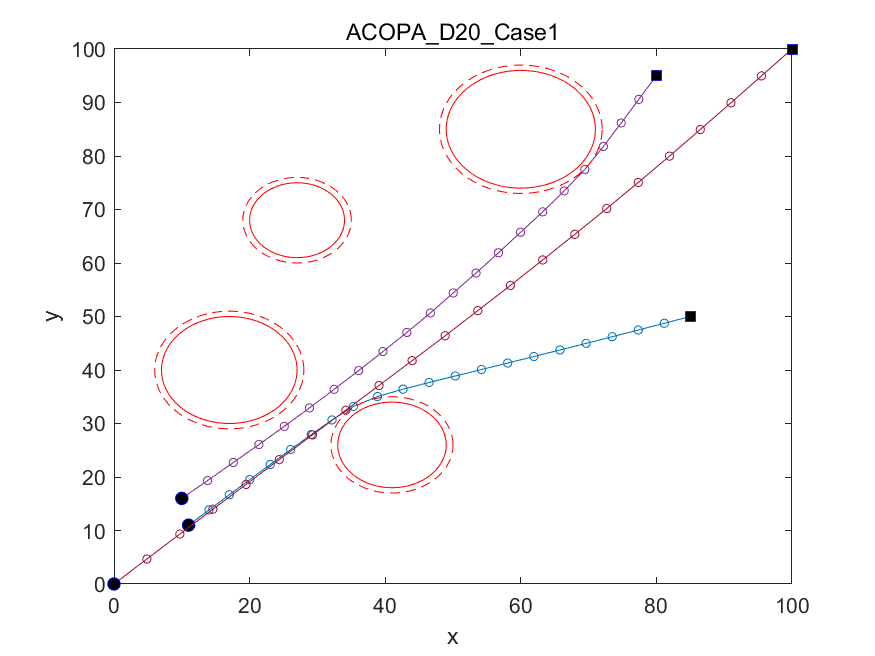
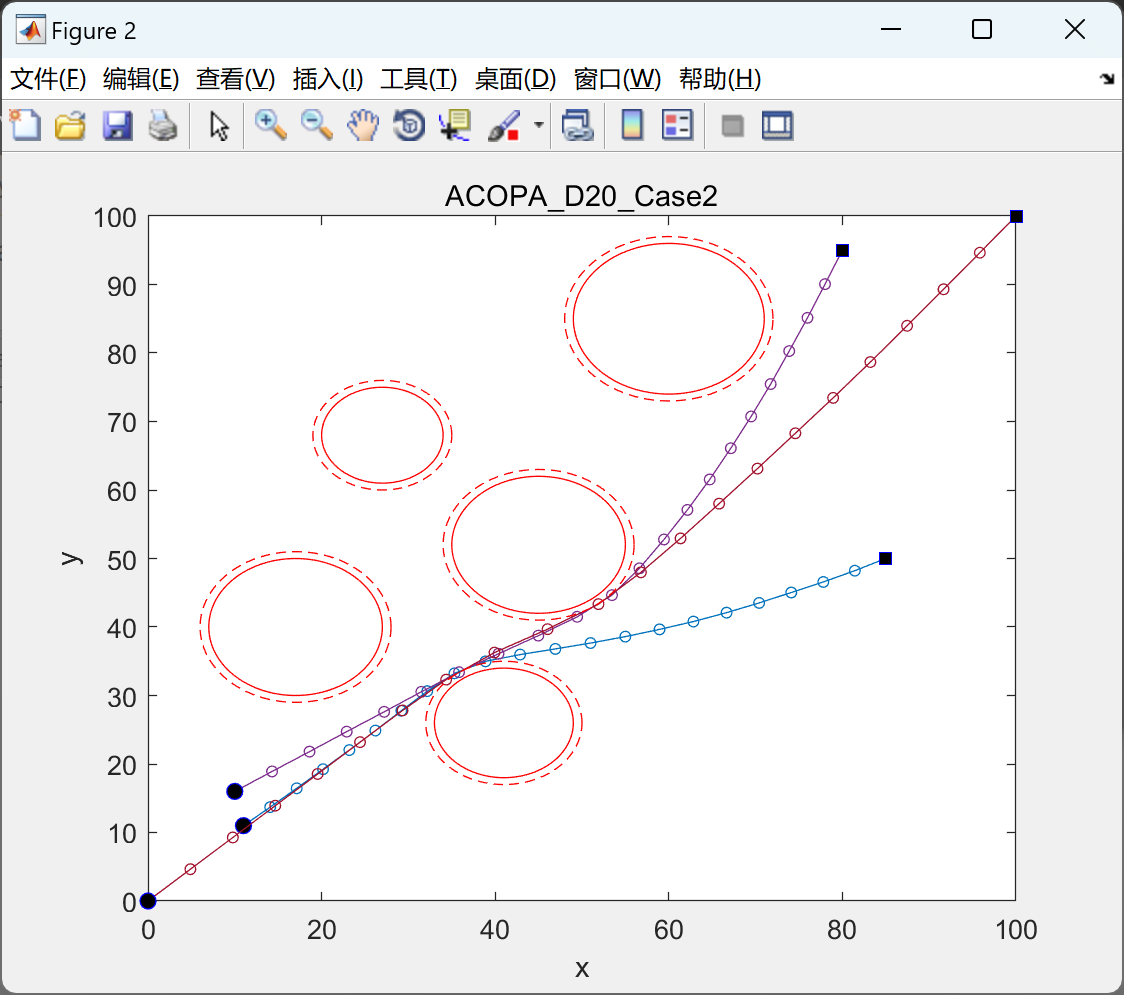
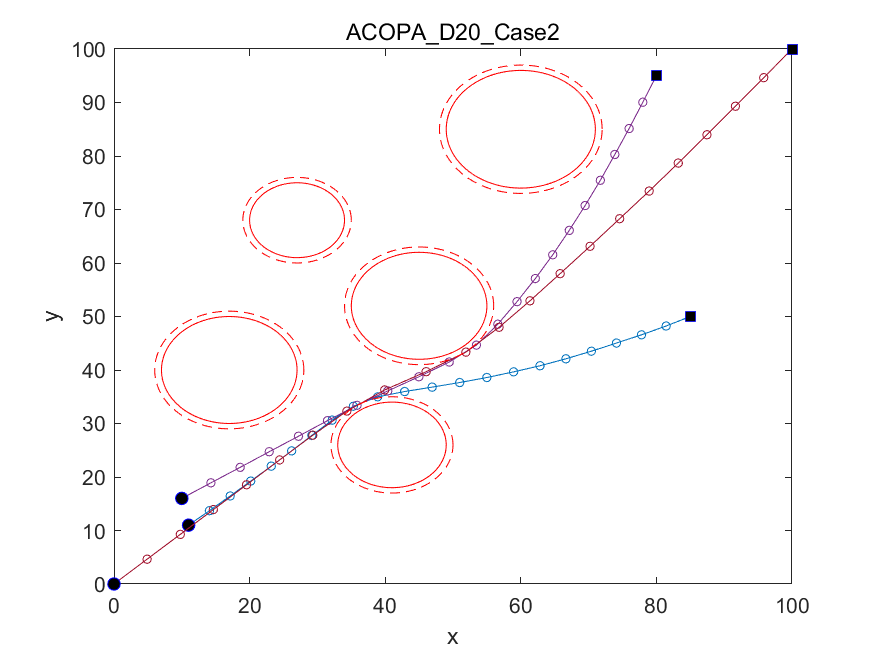
以下结果图去掉Matlab图框。
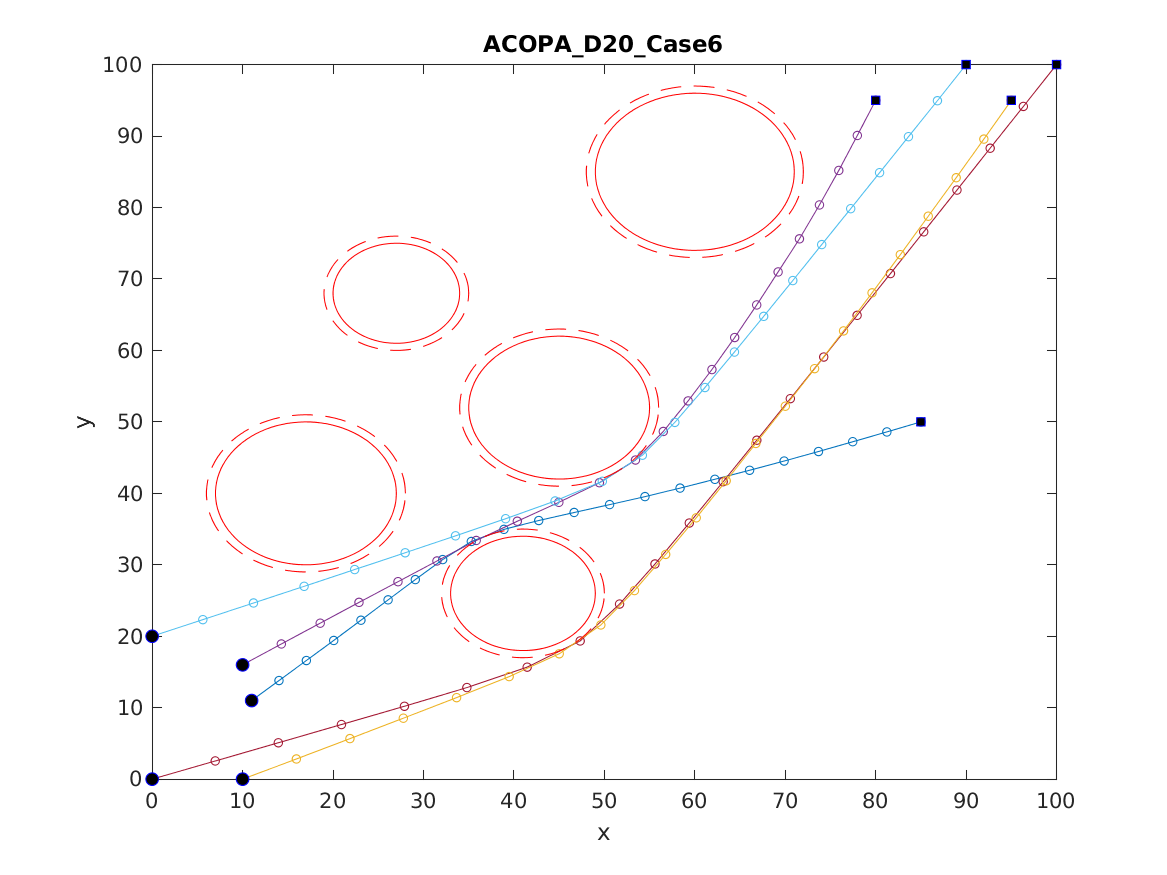
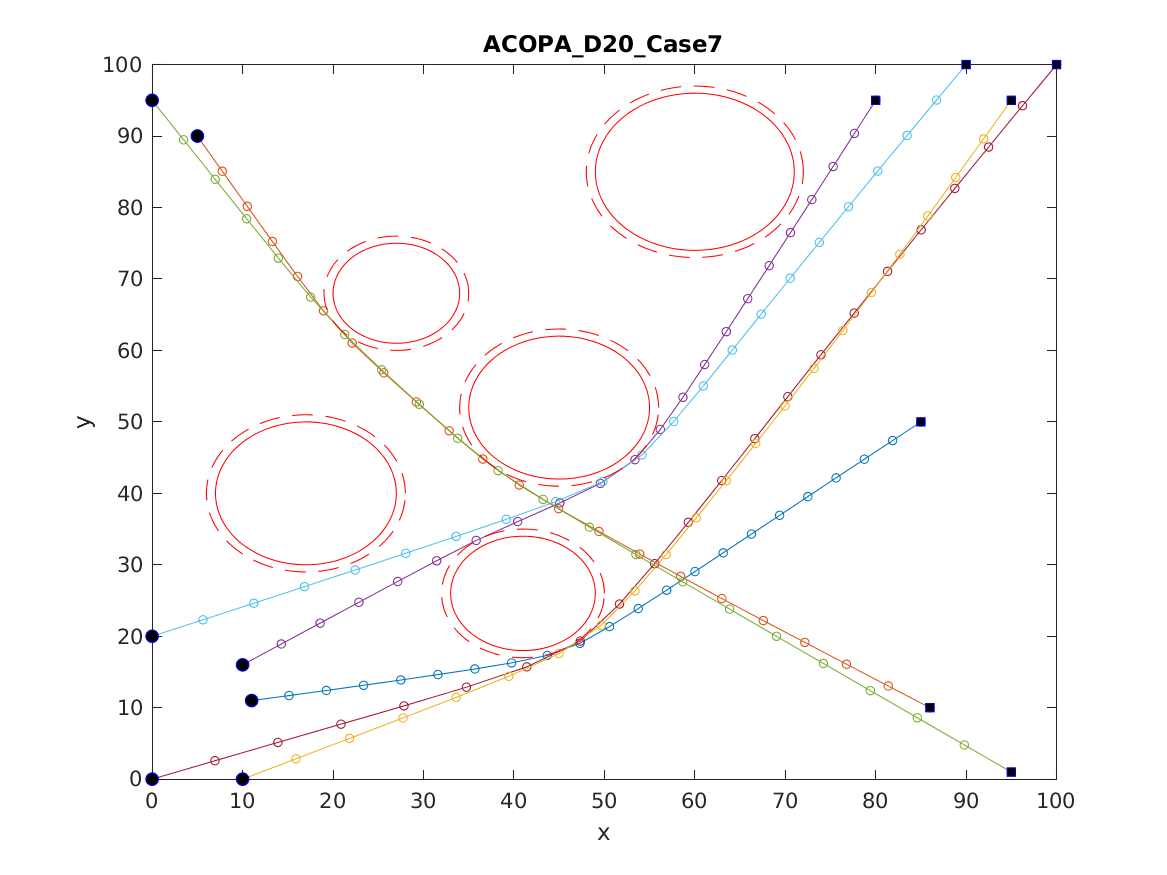
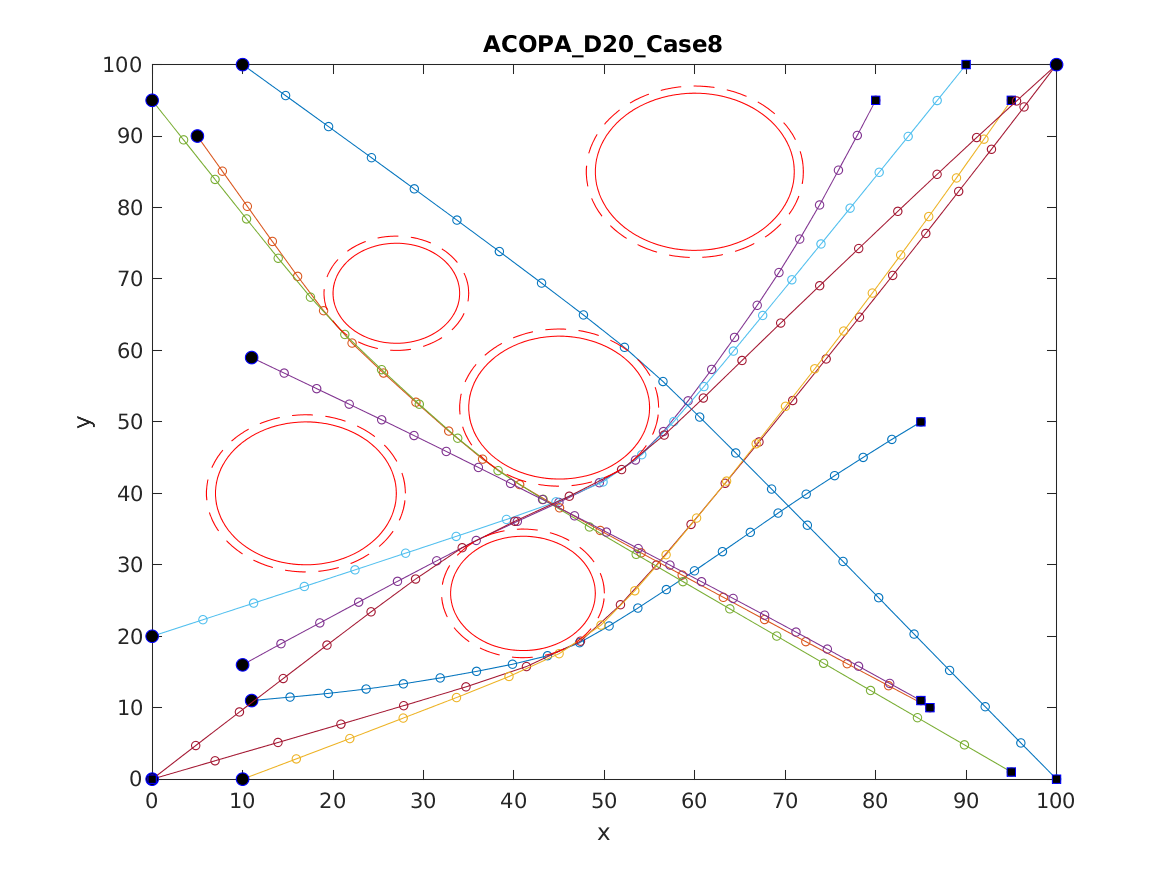
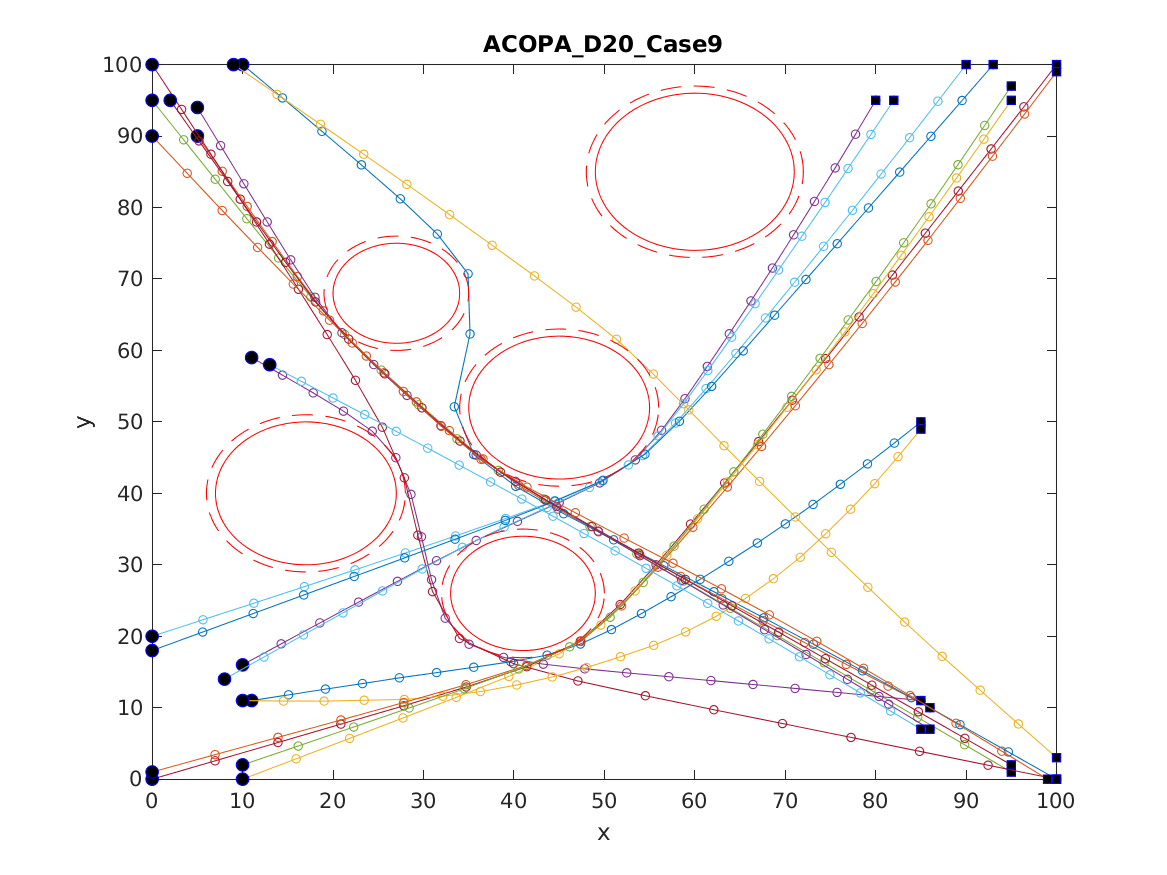
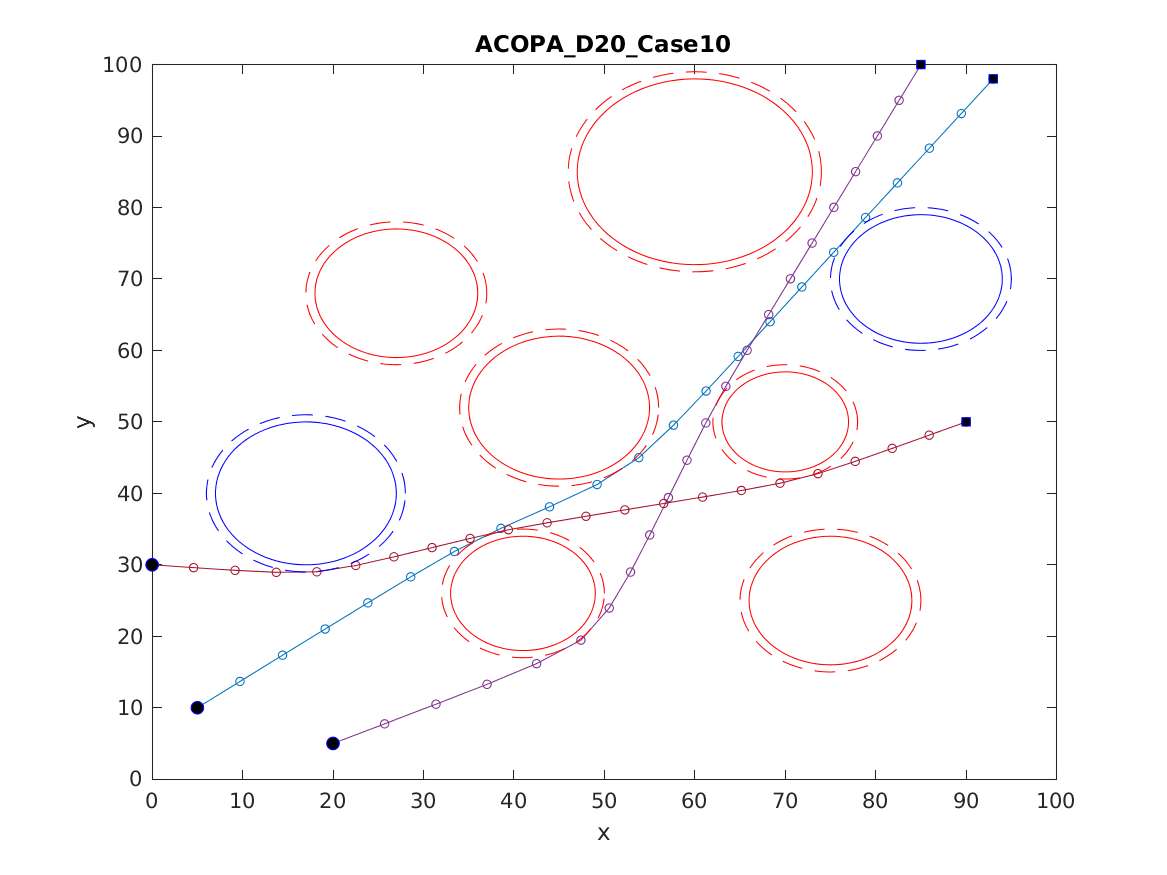
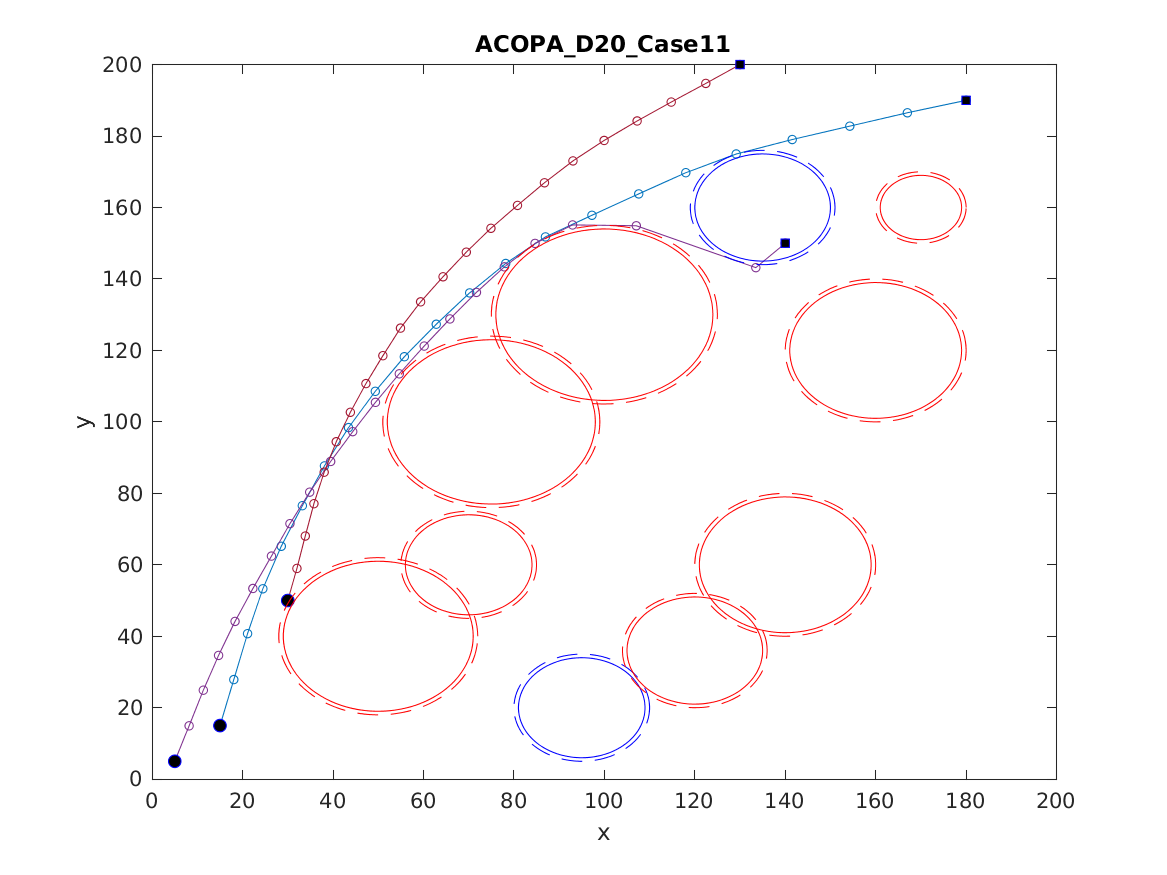
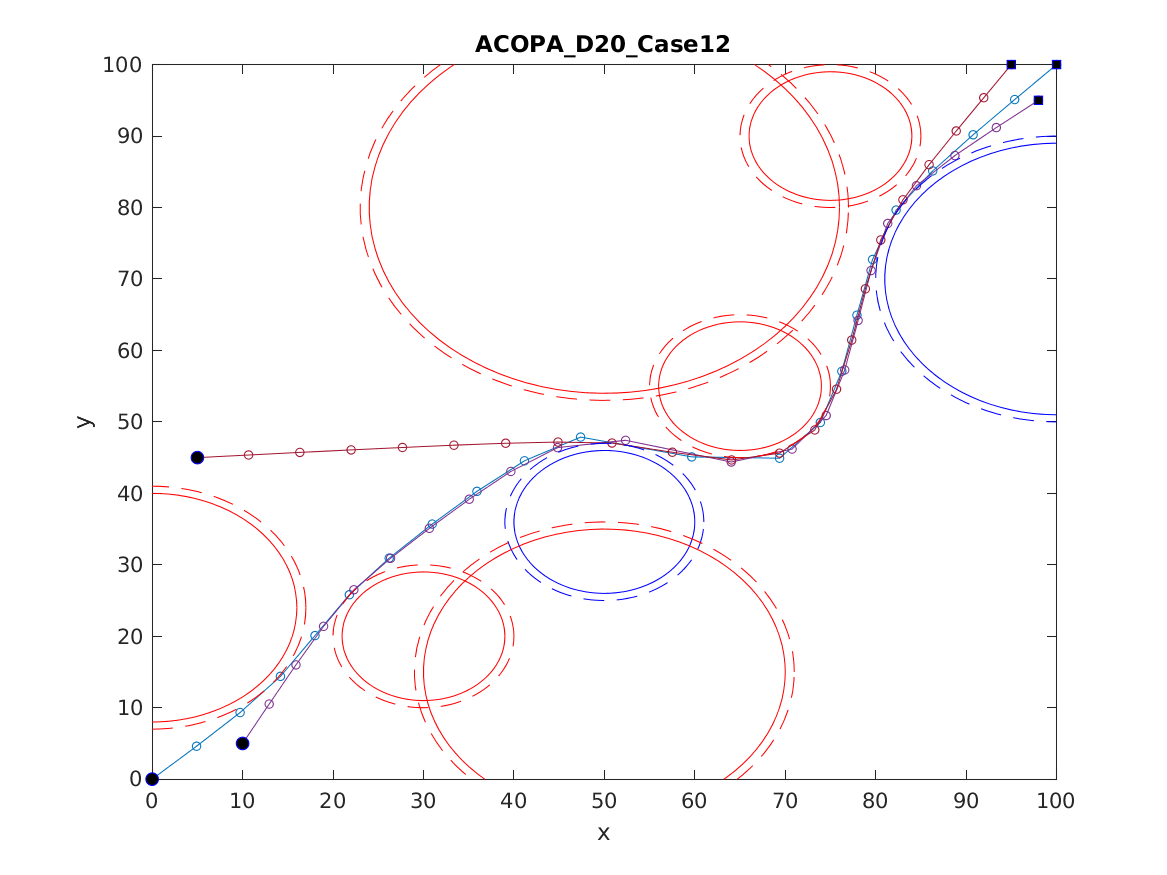
部分代码:
% ACOPA for path planning
function [TGbest, TGbestValue, FEvBestFitness]= ACOPA (MaximumFEs, SwarmSize, InitPos, ModelInfor, pRepair)
flag_restart=1;
zeta=0.6;
q=0.2;
win=10;
AgentIndex=1;
eval_agent(AgentIndex)=1; % fitness values evaluations (FEs) count for each robot(agent)
TModelInfor=CordinateTransformation(ModelInfor, AgentIndex); % thansfer the coordinate system
TaskNumber=TModelInfor.TaskNumber; % number of tasks/robots
...
for Dimension=[20 ] % the number of waypoints 20 30 40 60
for Task=1:12 % 1:12
%% Path plannning
mainPathPlanning (Dimension, Task)
%% Multi-agent coordination
mainMultiagentCoordination (Dimension, Task)
%% plot
pathplot (Dimension, Task)
end
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。


















 647
647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









