




💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文内容如下:🎁🎁🎁
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 题目

- 背景
在如今各类通用神经网络加速处理器(Neural Processing Unit,NPU)中,基于单指令多数据流(Single Instruction Multiple Data,SIMD)架构的处理器硬件设计简单,面效高,成为边缘推理任务的首选,但其软件模型适配的复杂性成为其大规模商用的关键瓶颈。在神经网络推理过程中,算子(如矩阵乘Matmul、卷积Conv、注意力Attention等)是最小任务单元,其执行效率直接影响模型在平台上端到端的推理性能。我们将算子在SIMD架构硬件平台上的完整计算过程拆解为由硬件单元操作构成的细粒度计算图,并通过手工或自动的方式编排成可在SIMD平台上执行的任务。由于这类计算图具有高度异构性(算子类型多样、输入形状动态变化、拓扑结构复杂),人工编排方式难度大,缺乏通用性,且效率低下,无法在如今日益复杂的计算场景下大规模推广。
因此,亟需设计一种通用调度算法,自动地将计算图中各原子操作编排调度到各硬件单元上执行,取代低效的人工编排计算单元流水的过程。该算法需面向SIMD平台的硬件限制,给出由硬件单元操作组成的计算图的优化调度顺序,使得多个不同单元能并行执行,缩短流水线延迟。同时,调度算法还需考虑内存与计算协同,动态管理多级缓存,自动决定缓存数据换入换出,减少数据搬运开销。
- 核内调度算法
- 任务
计算图为有向无环图(DAG),本题开始给出的图,其节点分为两类:在特定硬件单元上执行的操作节点,以及用于缓存资源分配的缓存管理节点。给定的一个计算图,需要通过调度算法提供一个包含计算图所有节点的有序列表作为调度顺序,以及为所有缓存管理节点中的申请节点分配相应类型的地址。在本核内调度问题中,处理核心由多个执行单元和多级缓存共同组成(参考附录A)。
计算图中的每个操作节点具有如下关键属性:
- Id:从0开始的节点唯一标识符。
- Op:操作指令名。可以是除ALLOC/FREE以外的任意操作名(例如数据搬运类操作COPY_IN,COPY_OUT等,计算类操作ADD,MUL等)。
- Pipe:指定该操作在哪个执行单元上运行。如附录A图3中,Cube、Vector为计算单元,MTE1/2/3/FIXP为数据搬运单元。
- Cycles:表示在该执行单元上操作运行所需的时钟周期数。
- Bufs:表示该操作所需输入和输出数据缓冲区的唯一标识符(BufId)组成的列表。
计算图中的每个缓存管理节点具有如下关键属性:
- Id:从0开始的节点唯一标识符。
- Op:ALLOC或FREE,分别代表申请或释放数据缓冲区。
- BufId:所申请或释放的数据缓冲区的唯一标识符。
- Size:申请或释放的数据缓冲区长度。
- Type:该数据缓冲区所处的缓存类型(如附录A图3中L1/UB/L0A/L0B/L0C等)。
计算图中的每条有向边(下文中也称之为依赖边)表示源节点和目的节点之间的执行依赖关系,节点必须严格按照依赖边约束的前后顺序执行。
图1为一个示例Exp计算图,其表现出计算图如下基本规则:
- 首先,忽略缓存管理节点后,所有的计算图都以COPY_IN节点开始(将数据从核外内存搬入核内缓存),经过一系列核内基本运算,最终以COPY_OUT节点结束(将计算结果从核内缓存搬出至核外内存)。
- 其次,所有操作节点的执行都受事先分配好的缓存资源限制。因此,计算图中所有根节点均为ALLOC节点,所有叶子节点均为FREE节点,反之亦然。
- 最后,ALLOC节点发出的有向边通常指向对应缓冲区数据的生产者(例如,Id为0的ALLOC节点指向COPY_IN节点);而该缓冲区内数据的消费者则通过有向边指向FREE节点(例如,EXP节点指向Id为4的FREE节点);生产者和消费者之间也通过有向边相连。
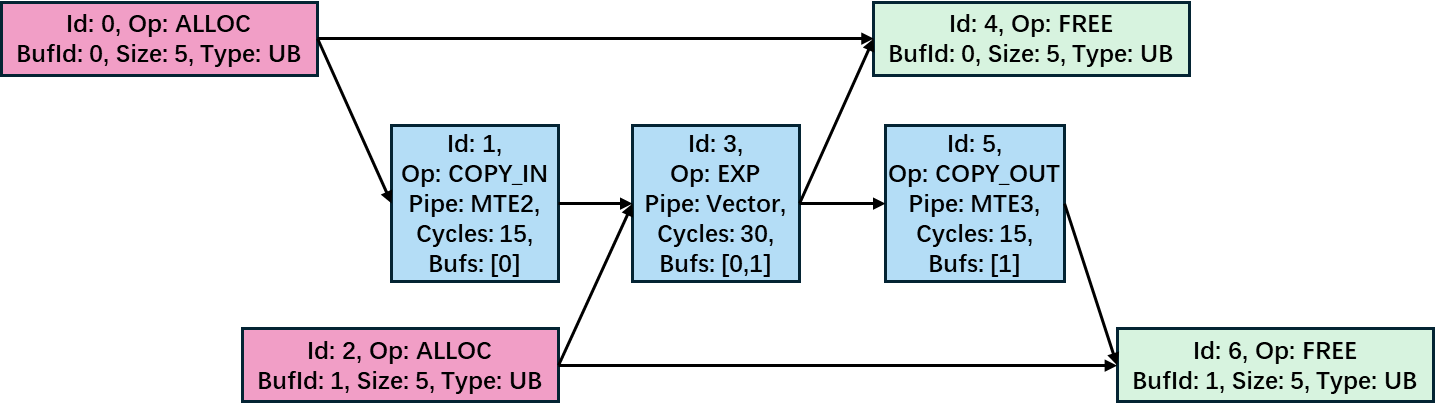
调度算法的首要任务是给出一个满足计算图拓扑序的节点执行序列
,该序列应该包含计算图中所有节点(该序列由节点Id组成)。以图1所示的示例Exp计算图为例,调度序列(0 ® 1 ® 2 ® 3 ® 4 ® 5 ® 6)为一个有效的调度序列,因为该序列包含了所有节点,且满足拓扑序。
调度算法需要为计算图中每个数据缓冲区(即每个BufId)分配一个起始地址偏移(Offset),以确定其在硬件缓存中所占的位置。硬件上的各类缓存均为有限长度的连续地址空间,每个缓冲区需在指定缓存空间中占据一片连续的地址区间,其区间长度由Size字段指定。不同数据缓冲区可以分时复用同一片区间,但同一时刻存在的缓冲区,必须分配在不重叠地址区间。
对于图1中的示例计算图,Buf0(BufId为0的缓冲区)和Buf1在给出的调度序列上生命周期重叠,因此需分配至不重叠的地址区间。Buf0和Buf1的长度都为5,若UB类型缓存容量为10,则可为Buf0分配[0-4]的地址区间,为Buf1分配[5-9]的地址区间,因此缓存地址分配方案{Buf0:Offset=0,Buf1:Offset=5}是可行的。
这样就得到了一个包括节点调度顺序和缓存地址分配在内的完整调度方案,其在实际硬件上的执行过程如图2所示。
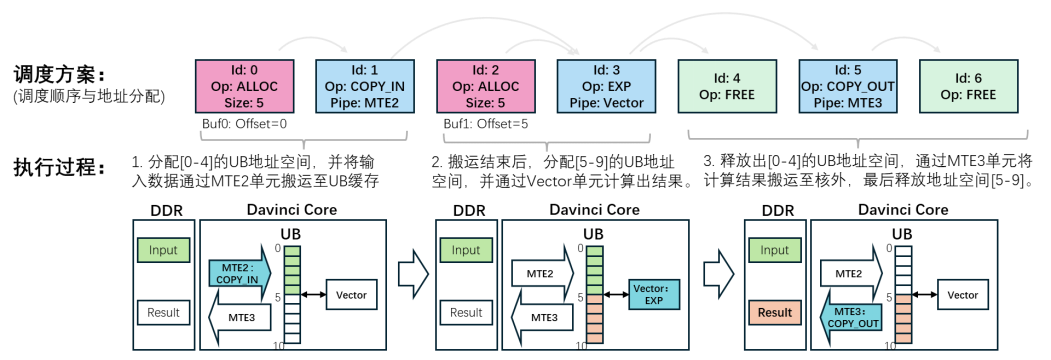
由于硬件缓存大小有限,调度算法可能会遇到空间不足的问题:在执行中的某一个时刻,需要驻留数个缓冲区,然而硬件空间大小可能不满足这些数据缓冲区的需要,无法生成可行的调度方案。此时,调度算法需要在计算图中加入数据搬运操作节点,将部分核内缓冲区数据临时移出至核外内存(Double Data Rate SDRAM,简称DDR)上,释放出硬件缓存空间,并在后续计算需要时,重新载入至核内缓存。上述操作称为缓存换入换出操作(简称SPILL操作),具体给出方式见附录B。
-
- 算法评估指标
评估调度算法的性能主要依据两个关键指标:任务的总执行时间和总额外数据搬运量。
-
-
- 总执行时间
-
总执行时间表示在硬件上执行完计算图需要的总时钟周期数,用于衡量调度方案在硬件上的实际运行效率。硬件上各个不同单元虽然可以同时工作,但由于指令间存在依赖关系,某条指令要能在某个单元上执行,必须等待其前序指令(在其他单元上)执行完毕。两种依赖关系可能导致节点执行时需要等待:一是计算图中节点间已有的依赖边,二是缓存物理地址复用带来的执行依赖。调度方案下的总执行时间根据调度顺序与依赖关系确定(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1288
1288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









