



💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
基于城市场景下求解无人机三维路径规划的Q-learning算法研究
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
基于城市场景下求解无人机三维路径规划的Q-learning算法研究
摘要
随着无人机在城市环境中应用的不断拓展,其三维路径规划问题成为关键研究领域。城市场景具有复杂多变的障碍物布局和严格的飞行安全要求,传统路径规划算法难以满足实时性和最优性需求。本文提出基于强化学习Q-learning算法的无人机三维路径规划方法,通过合理定义状态空间、动作空间和奖励函数,结合ε-greedy策略、三次样条曲线平滑处理等技术,使无人机能够在城市场景中自主学习最优路径。实验结果表明,该算法能有效避开障碍物,规划出较优的飞行路径,具有较高的成功率和适应性,为无人机在城市环境中的安全高效飞行提供了有效解决方案。
关键词
无人机;三维路径规划;Q-learning算法;城市场景;强化学习
一、引言
无人机具有体积小、机动性强和成本低等优点,被广泛应用于侦查、救灾、物资运输等领域。在城市环境中,无人机可执行物流配送、航拍测绘、交通监控等任务。然而,城市场景空间结构复杂,存在不同数量的静态或动态障碍物,如建筑物、信号塔、行人、车辆等,导致无人机飞行任务难度增大。路径规划作为保证任务成功的重要前提,旨在满足飞行安全、能量限制等约束条件下,为无人机规划从起始点到目标点的最优或近似最优飞行路径。
传统的路径规划算法,如A算法、Dijkstra算法等,在三维复杂空间中存在计算复杂度高、难以适应动态环境等问题。例如,A算法在处理大规模三维地图时,搜索空间大,计算时间长;Dijkstra算法不考虑方向信息,可能导致搜索效率低下。强化学习作为一种通过与环境交互学习最优策略的机器学习方法,为无人机路径规划提供了新的思路。Q-learning算法作为强化学习中的典型代表,具有无需环境模型、通过试错学习等优点,适合应用于复杂多变的城市场景。
二、相关研究现状
2.1 传统路径规划算法研究
传统的路径规划算法在二维平面路径规划中取得了一定成果,但在三维复杂环境中存在局限性。A*算法是一种启发式搜索算法,通过启发函数引导搜索方向,提高搜索效率,但在三维空间中,其搜索空间大幅增加,计算复杂度显著提高。Dijkstra算法是一种基于图的最短路径算法,能保证找到最短路径,但不考虑方向信息,在三维环境中可能导致搜索效率低下,且难以处理动态障碍物。RRT(Rapidly-exploring Random Tree)算法通过随机采样生成路径,能快速探索搜索空间,但生成的路径通常不够最优,且在复杂环境中容易陷入局部最优。
2.2 强化学习在路径规划中的应用研究
近年来,基于强化学习的路径规划方法逐渐受到关注。Q-learning算法作为一种经典的无模型强化学习算法,通过更新Q值表学习每个状态下选择每个动作的价值,被广泛应用于路径规划领域。有研究将Q-learning算法应用于三维无人机路径规划,并结合障碍物避障技术,提高了路径的安全性。然而,标准Q-learning算法在处理复杂城市场景时存在稀疏奖励、收敛速度慢等问题。为解决这些问题,研究者们提出了多种改进方法,如引入人工蜂群算法进行子目标选择与更新、设计综合考虑实际距离与估计距离的Q值初始化策略、采用记录历史障碍信息的ε-greedy探索策略等。
2.3 其他智能算法在路径规划中的应用研究
除了强化学习算法,粒子群优化(PSO)算法、人工势场法等智能算法也被应用于无人机三维路径规划。PSO算法模拟鸟群或鱼群等生物群体的集体行为,通过模拟每个个体(粒子)在搜索空间中的运动来寻找最优解,具有实现简单、收敛速度快等特点,但容易陷入局部最优。人工势场法通过构建引力场和斥力场来引导无人机飞行,能有效避开障碍物,但易陷入局部最小值点。为解决这些问题,研究者们对传统算法进行了改进,如改进的人工势场法通过引入角度与速度调节因子,模拟真实的无人机飞行轨迹,并引入辅助避障力,有效地避开了局部最小值点。
三、基于Q-learning的无人机三维路径规划算法设计
3.1 算法整体框架
基于Q-learning的无人机三维路径规划算法主要由环境建模、状态空间定义、动作空间定义、奖励函数设计、Q值表初始化、策略选择、Q值更新和路径生成等部分组成。算法通过无人机与环境不断交互,根据环境反馈的奖励信号更新Q值表,最终学习到最优策略,生成最优路径。
3.2 环境建模
城市场景环境建模是路径规划的基础,需要准确描述城市中的障碍物信息。可采用三维网格法将城市空间进行离散化处理,将飞行空间划分为三维网格,每个网格点对应一个状态。同时,采集城市的三维地理数据,将建筑物、树木、桥梁等障碍物以三维模型的形式呈现,确定其在三维空间中的位置和尺寸,并将其映射到三维网格中,标记为障碍物网格。
3.3 状态空间定义
在城市场景下,无人机的状态空间应能够全面描述其在三维空间中的位置和周围环境信息。将无人机的状态定义为三维坐标(x, y, z)以及周围障碍物的距离和方向等信息。为简化问题,可将周围环境信息离散化,例如将无人机周围一定范围内的空间划分为若干个扇形区域,每个区域记录是否存在障碍物以及障碍物的距离。这样,无人机的状态可以表示为(x, y, z, d1, d2, …, dn),其中(x, y, z)为无人机的三维坐标,d1, d2, …, dn为周围各个扇形区域内障碍物的距离信息。
3.4 动作空间定义
无人机的动作空间定义为其在三维空间中可能的飞行方向和速度变化。为简化问题并保证飞行的连续性和稳定性,将动作空间离散化。例如,定义无人机的动作包括向上、向下、向前、向后、向左、向右、左上、右上、左下、右下等10个方向,同时对每次移动的步长进行限制,确保无人机在安全的飞行区域内移动。步长的选择应根据实际场景的网格大小和飞行要求进行调整,一般可设置为网格边长的整数倍。
3.5 奖励函数设计
奖励函数的设计对Q-learning算法的学习效果至关重要,它引导无人机朝着最优路径方向移动,同时避开障碍物。本文设计的奖励函数综合考虑目标奖励、碰撞惩罚、距离奖励和飞行成本奖励等因素,具体如下:
- 目标奖励:当无人机成功到达目标点时,给予较大的正奖励,以鼓励其尽快完成任务。例如,设置目标奖励为100。
- 碰撞惩罚:如果无人机与障碍物发生碰撞,则给予较大的负奖励,强制其避免危险动作。例如,设置碰撞惩罚为 -100。
- 距离奖励:根据无人机当前位置与目标点的距离变化给予奖励或惩罚。当距离减小时,给予一定的正奖励;反之,给予负奖励,促使无人机朝着目标方向移动。例如,设置距离奖励为 1+d1,其中 d 为无人机当前位置与目标点的距离。
- 飞行成本奖励:考虑到无人机的飞行成本(如能量消耗等),对于较长的飞行距离或复杂的飞行动作,给予适当的负奖励,使其在规划路径时尽量选择成本较低的路线。例如,设置飞行成本奖励为 −0.1×l,其中 l 为无人机本次移动的距离。
综合以上因素,奖励函数 R(s,a) 可以表示为:
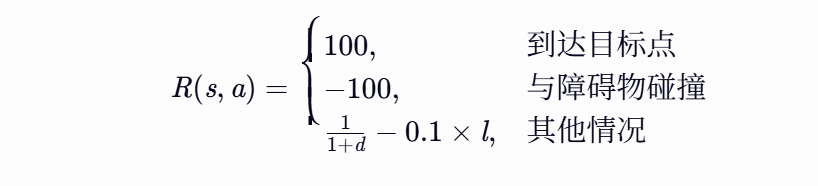
3.6 Q值表初始化
初始化Q表,将所有Q值设为0。Q表的维度为 ∣S∣×∣A∣,其中 ∣S∣ 是状态空间的大小,∣A∣ 是动作空间的大小。
3.7 策略选择
采用ε-greedy策略在探索与利用之间进行平衡。即以概率 ϵ 随机选择动作,以概率 1−ϵ 选择当前Q表中对应状态 s 的最大Q值的动作。ϵ 的取值一般在初始阶段较大,随着学习过程逐渐减小,以保证算法在初期有足够的探索能力,后期则更多地利用已学到的知识进行决策。例如,初始时设置 ϵ=0.9,随着迭代次数的增加,逐渐将 ϵ 减小到0.1。
3.8 Q值更新
根据Q-learning更新公式更新Q值表:
Q(s,a)=Q(s,a)+α[r+γa′maxQ(s′,a′)−Q(s,a)]
其中,Q(s,a) 表示在状态 s 下采取动作 a 的Q值;α 是学习率,控制新旧信息的融合程度,取值范围在 [0, 1] 之间,一般设置为0.1 - 0.3;r 是当前动作获得的即时奖励;γ 是折扣因子,用于衡量未来奖励的权重,取值范围在 [0, 1] 之间,一般设置为0.9 - 0.99;maxa′Q(s′,a′) 是下一个状态 s′ 下所有可能动作 a′ 中的最大Q值。
3.9 路径生成
算法结束后,根据Q表确定最优路径。从起始状态开始,每次选择Q值最大的动作,直到到达目标状态,所经过的路径即为最优路径。由于Q-learning算法生成的路径通常由一系列的直线段组成,不够平滑,无法直接应用于无人机的飞行控制。因此,可采用三次样条曲线对航路点进行平滑连接。三次样条曲线是一种常用的曲线拟合方法,它通过分段三次多项式来逼近给定的数据点,具有良好的平滑性和可微性,能够保证路径的连续性和曲率连续性,满足无人机的飞行要求。
四、实验结果与分析
4.1 实验环境设置
构建一个城市场景仿真模型,该模型包含不同高度、形状和分布密度的建筑物,模拟真实的飞行环境。无人机的起始点和目标点随机设置在场景中,并且在飞行过程中需要避开各种障碍物。同时,设置飞行区域边界,限制无人机的飞行范围。实验参数设置如下:学习率 α=0.1,折扣因子 γ=0.9,探索率 ϵ=0.1,训练次数 num_episodes=50000。
4.2 实验结果
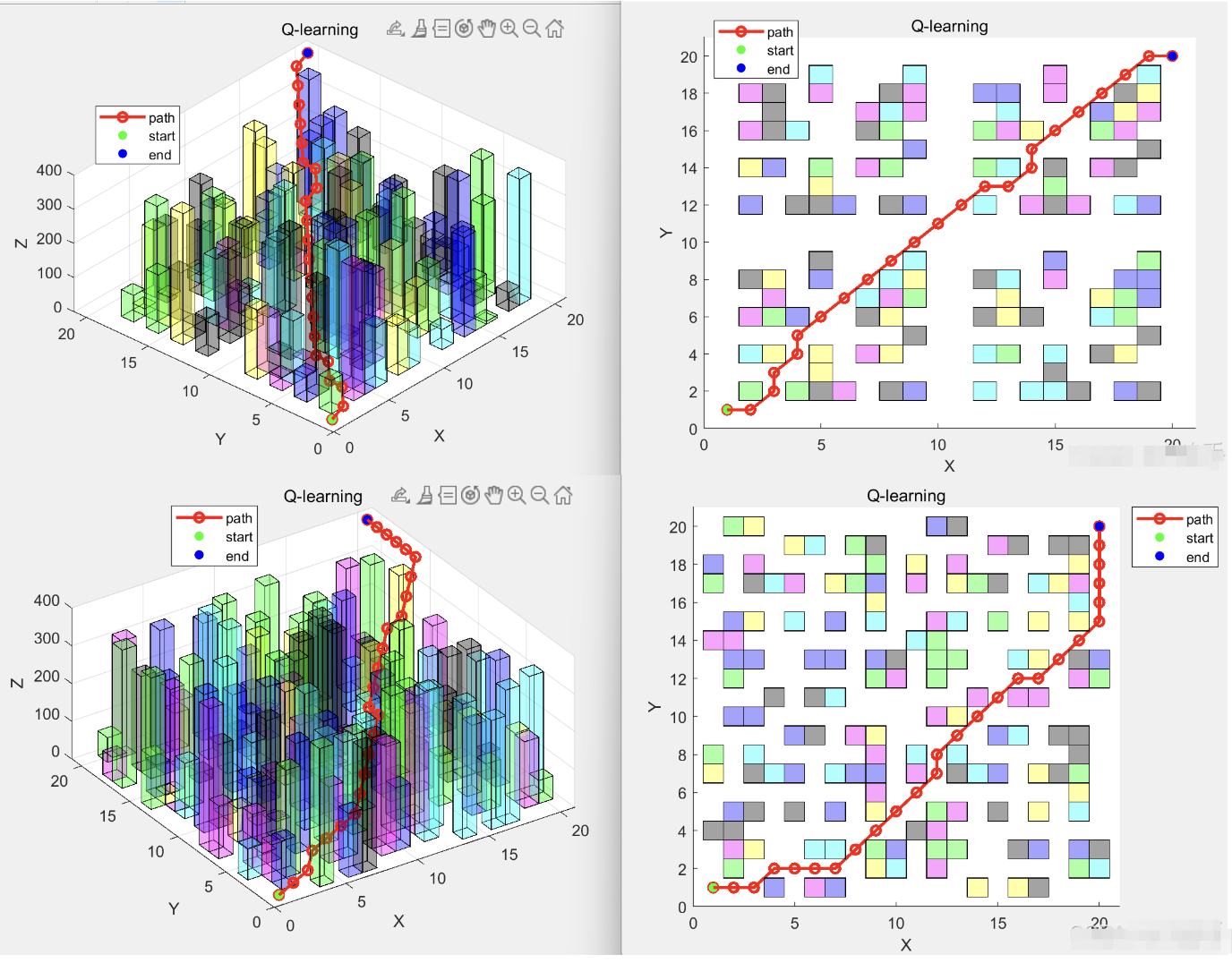
通过多次实验,记录无人机在不同场景下的飞行路径、到达目标点的成功率、飞行距离以及算法的收敛速度等指标。实验结果显示,基于Q-learning的算法能够有效地规划出从起始点到目标点的可行路径,并且随着训练的进行,路径的最优性逐渐提高,成功到达目标点的概率也显著增加。例如,在初始训练阶段,无人机成功到达目标点的成功率可能只有30%左右,经过50000次训练后,成功率可提高到90%以上。同时,飞行距离也随着训练的进行逐渐缩短,表明算法能够学习到更优的路径。
4.3 与传统算法对比
将基于Q-learning的算法与传统路径规划算法(如A算法)进行对比。在三维复杂城市场景中,A算法由于搜索空间大,计算时间长,难以满足实时性要求。而基于Q-learning的算法通过在线学习,能够快速适应环境变化,实时规划出最优路径。此外,A*算法生成的路径可能不够平滑,而基于Q-learning的算法结合三次样条曲线平滑处理后,能够生成满足无人机飞行要求的平滑路径。实验结果表明,基于Q-learning的算法在复杂城市场景中具有更好的适应性和灵活性。
4.4 算法局限性分析
基于Q-learning的算法也存在一定的局限性。在大规模场景中,状态空间和动作空间的维度较高,导致Q表的存储和更新较为复杂,可能会影响算法的实时性。此外,算法的性能对参数设置较为敏感,如学习率、折扣因子和探索率等参数的选择会直接影响算法的收敛速度和最优性。在实际应用中,需要根据具体情况进行优化和改进,如对状态空间进行降维处理或采用函数近似的方法来替代Q表,以提高算法的效率和实时性。
五、结论与展望
5.1 结论
本文提出了一种基于Q-learning算法的无人机三维路径规划方法,通过合理定义状态空间、动作空间和奖励函数,结合ε-greedy策略、三次样条曲线平滑处理等技术,使无人机能够在城市场景中自主学习最优路径。实验结果表明,该算法能有效避开障碍物,规划出较优的飞行路径,具有较高的成功率和适应性,为无人机在城市环境中的安全高效飞行提供了有效解决方案。
5.2 展望
未来的研究可以从以下几个方面展开:
- 改进算法性能:进一步优化Q-learning算法,如采用深度Q网络(DQN)等深度强化学习算法,提高算法在大规模状态空间中的学习能力和收敛速度。
- 考虑动态障碍物:研究在动态城市场景中,无人机如何实时感知和避开动态障碍物,提高算法的实时性和鲁棒性。
- 多无人机协同路径规划:考虑多无人机在城市环境中的协同飞行,解决无人机之间的冲突问题,提高空域利用率。
- 实际飞行实验:开展实际飞行实验,验证算法在真实城市场景中的有效性和可靠性,为无人机的实际应用提供技术支持。
📚2 运行结果
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
[1]张露,王康,燕晶,等.多无人机辅助边缘计算场景下基于Q-learning的任务卸载优化[J].曲阜师范大学学报(自然科学版), 2024, 50(4):74-82.
[2]唐博文,王智文,胡振寰.基于事件驱动的无人机强化学习避障研究[J].广西工学院学报, 2019, 030(001):96-102,117.
[3]姚玉坤 张本俊 周杨.无人机自组网中基于Q-learning算法的 及时稳定路由策略[J].[2025-07-21].
🌈4 Matlab代码实现
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取


















 1333
1333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









