







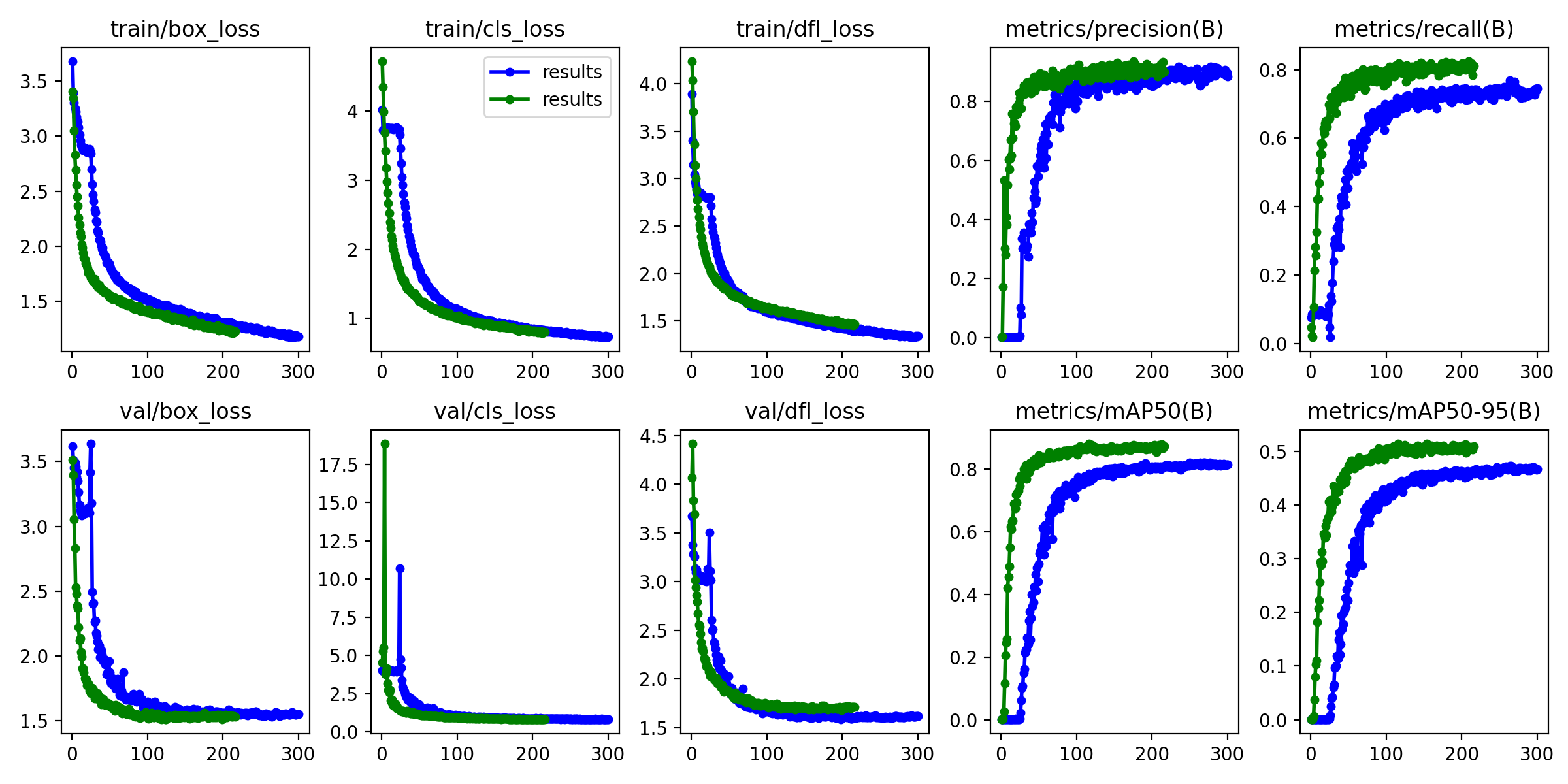
蓝色线条为原模型,绿色线条为优化后的小目标模型,map提升3.2!
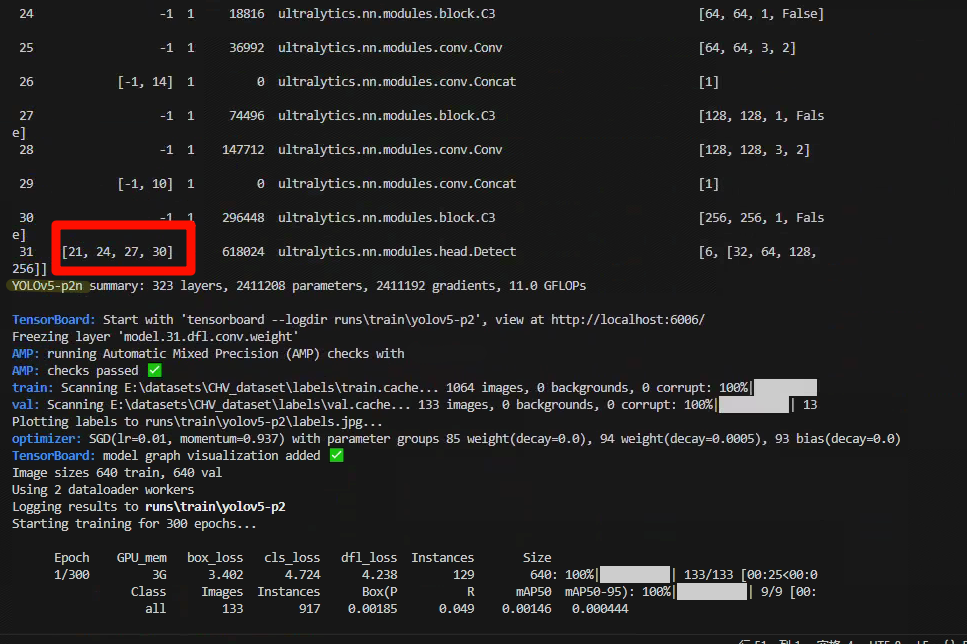
我们先理解什么叫做上下采样、再理解要选择哪一层作为检测头和分辨率越大检测目标越小等问题,然后再来添加小目标检测头就会容易理解很多!
原理介绍
一、上采样(Upsampling)
1. 定义
上采样是指将特征图的空间尺寸变大(例如从 20×20 → 80×80),用来提升图像的分辨率。常见于解码器结构或特征融合中。
2. YOLO 中的上采样
YOLO 使用 nn.Upsample 进行上采样,主要参数有:
nn.Upsample(scale_factor=4, mode='nearest')
scale_factor=4:将高宽放大 4 倍。mode='nearest':最近邻插值法,最简单、计算最少的上采样方法。
3. 最近邻插值(Nearest Neighbor)
这是最基础的上采样方式:
-
假设原图为:
1 2 3 4 -
上采样2倍后:
1 1 2 2 1 1 2 2 3 3 4 4 3 3 4 4
每个像素通过复制扩展到目标尺寸,是不涉及新像素计算的方式。
4. 其他插值方式(了解即可)
| 插值方法 | 描述 |
|---|---|
| Nearest(最近邻) | 复制最近的像素值 |
| Bilinear(双线性) | 插值周围4个像素的加权平均 |
| Bicubic(三次插值) | 更复杂的16邻域插值 |
YOLO 通常为了速度选择最近邻插值。
二、下采样(Downsampling)
1. 定义
下采样是指将特征图的空间尺寸缩小(例如从 256×256 → 128×128),通常用于减少计算量、提取更高级语义特征。
2. YOLO 中的下采样
YOLO 使用带有步长(stride)的卷积进行下采样:
Conv(in_channels, out_channels, kernel_size=3, stride=2)
例如:
[-1, 1, Conv, [32, 3, 2]] # 输出通道数 32,卷积核大小3x3,步长为2
- 步长为 2 → 特征图的宽和高变为原来的一半。
- 卷积同时提取特征 + 缩小尺寸。
3. 原理示例
假设输入为 6×6 特征图:
-
卷积核大小为 3×3,步长 stride=2。
-
滑动窗口如下:
- 第一个卷积覆盖输入的 (0:3, 0:3)
- 下一个跳两个像素到 (0:3, 2:5)
- 最后输出为 2×2 特征图
输出尺寸计算公式:
output_size = (input_size - kernel_size + 2*padding) // stride + 1
三、上下采样在 YOLO 中的应用
用途
| 操作 | 应用场景 |
|---|---|
| 上采样 | 结合低层特征(细节丰富)与高层语义信息,常用于 PANet/FPN结构 |
| 下采样 | 提取深层语义信息,减小计算量,增强模型的感受野 |
结构示意
输入图像 → 多次下采样(卷积+步长) → 上采样(恢复空间信息) → 检测头输出
YOLOv5 中如:
[-1, 1, Conv, [64, 3, 2]] # 下采样
[-1, 1, nn.Upsample, [None, 2, 'nearest']] # 上采样
总结对比
| 操作 | 目的 | 方法 | 尺寸变化 |
|---|---|---|---|
| 上采样 | 放大特征图 | 插值算法 | 变大(如2×) |
| 下采样 | 压缩特征图、提取语义 | stride卷积等 | 变小(如1/2) |
四、模型结构汇总的对称性问题
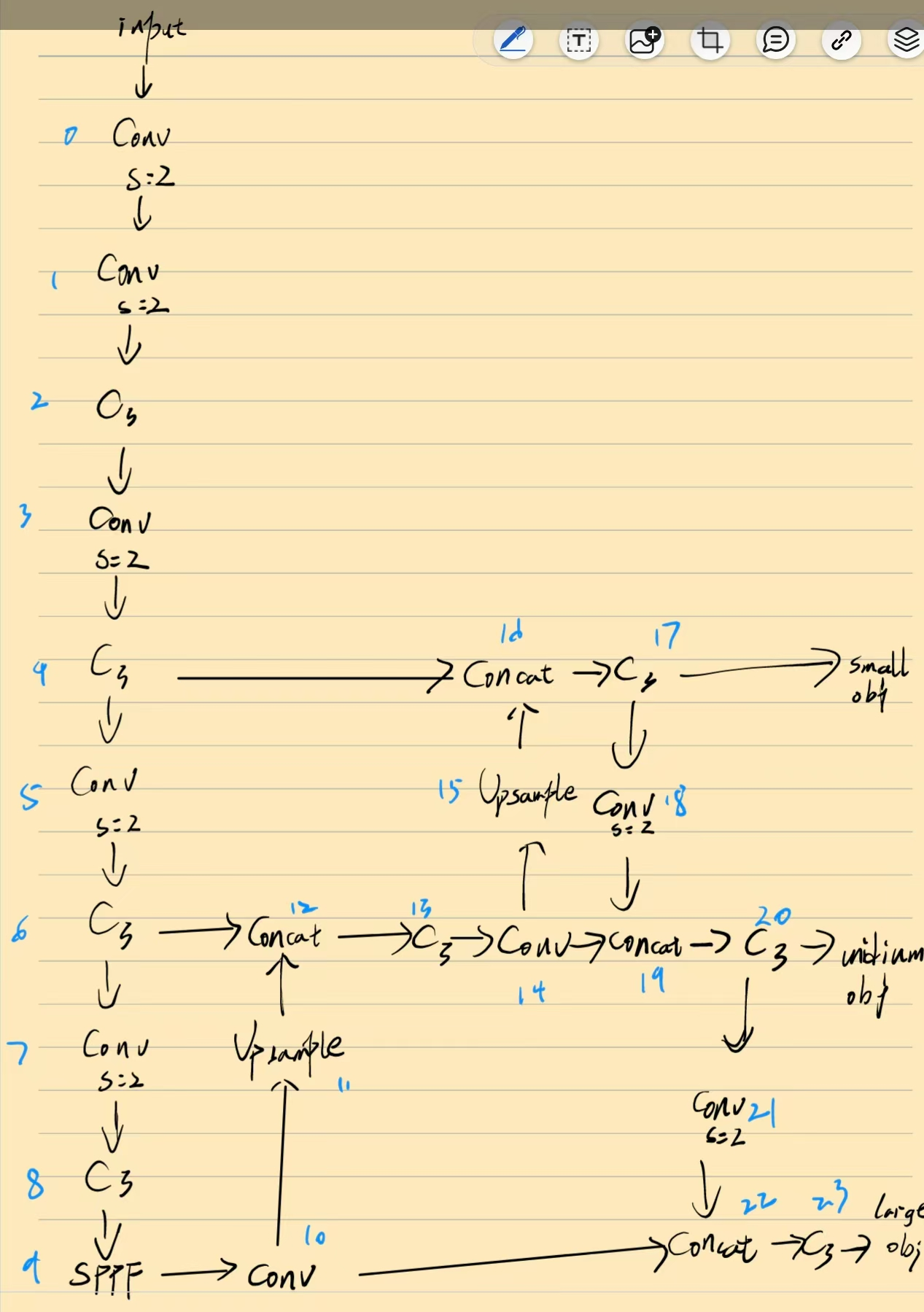
对称性问题主要是yolov5的包装性,比如conv(s=2)下采样后一定会用一个c3模块对特征进行更深层次的整合。
从yolov8中可以看出,主干网结构为conv(s=2)+4个下采样模块+sppf。
其次上采样的过程会和concat进行包装,因为单纯的上采样采用的是近邻采样,上采样后的图像具有分割感,通过concat引入同等分辨率的特征图,可以一定程度抑制这种分割感,也可以避免模型的过拟合。
上采样结束后同样会跟上一个c3对该特征图进行更深层次的整合。
也就是上下采样最后一定会跟上一个c3模块。
五、每个尺度下的输出选择问题
我们一般选择当前分辨率下,最后特征提取层作为检测头。
六、分辨率越大的检测小目标、分辨率越小的检测大目标
分辨率越大的保留的浅层信息更多,比如下采样8倍和下采样16倍的特征图,下采样8倍是分辨率大的图像,下采样16倍是分辨率小的图像。在大分辨率的图像中,一个像素相当于原始图像的8个像素,那么它一个像素的跨度不会太大,适合检测小目标;小分辨率的图像中,一个像素相当于原始图像的16个像素,一个像素的跨度太大,适合检测大目标。
当然一个像素等于多少个原始图像的像素并不是简单的倍率计算,这需要涉及到一些感受野的计算,但是从一个粗略的推导就能得出分辨率大的图像适合检测小目标,分辨率小的图像适合检测大目标。
构建思路
那我们在添加一个新的4倍小检测头同样可以用这样的思路
对8倍检测头的c3模块用上采样结构(upsample+concat),然后再用c3模块对4倍特征图进行特征整合。
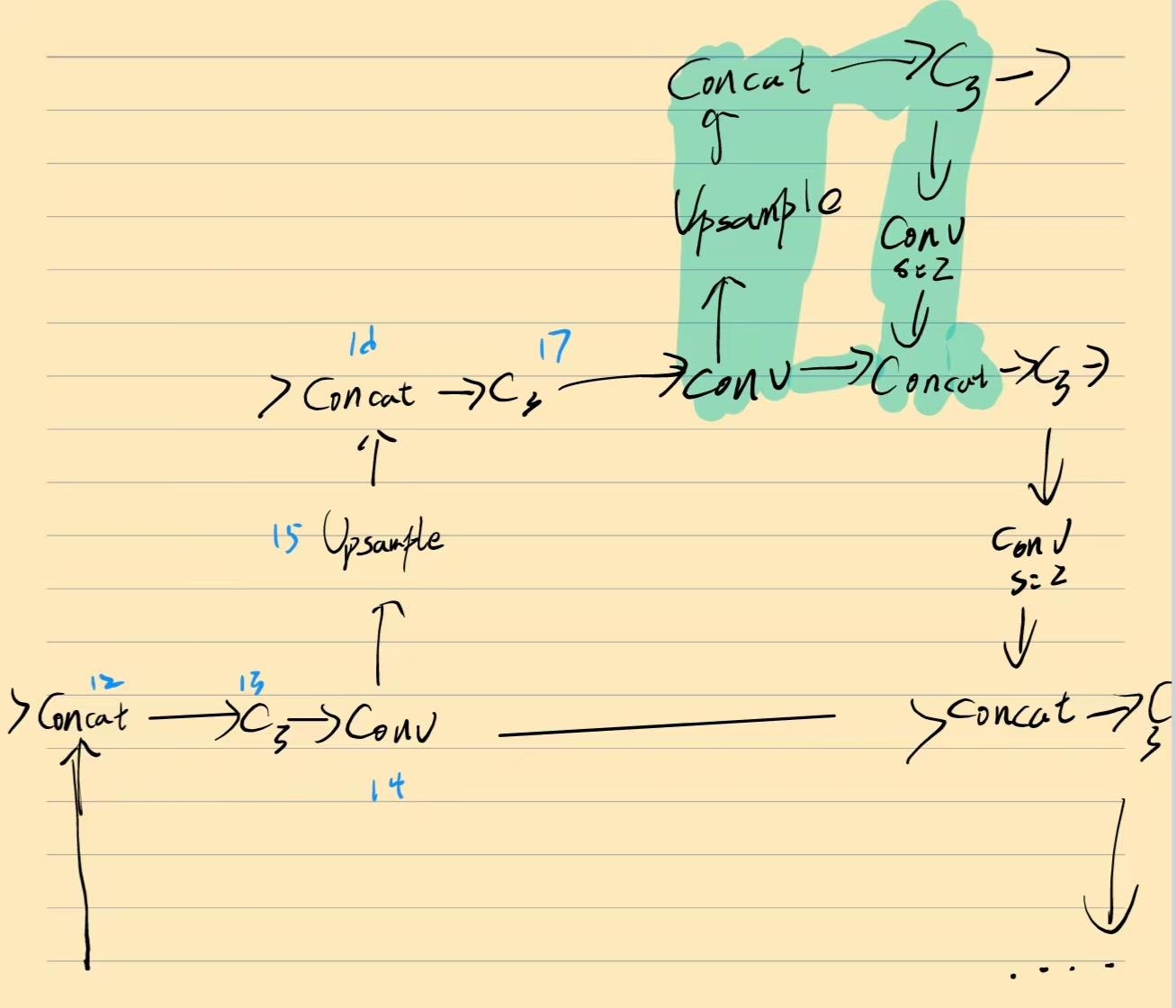
被我涂颜色的区域就是新增的p2小目标检测头。
也就是大概这样子,用upsample上采样后用concat进行通道融合,再用c3模块进行特征提取最后输出。
如果你想将x small检测头的特征引入到下层,那你就需要将xsmall的c3模块进行conv(s=2)下采样后再加个c3模块。
代码修改
原yolov5结构
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov5n.yaml' will call yolov5.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
s: [0.33, 0.50, 1024]
m: [0.67, 0.75, 1024]
l: [1.00, 1.00, 1024]
x: [1.33, 1.25, 1024]
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc]], # Detect(P3, P4, P5)
]
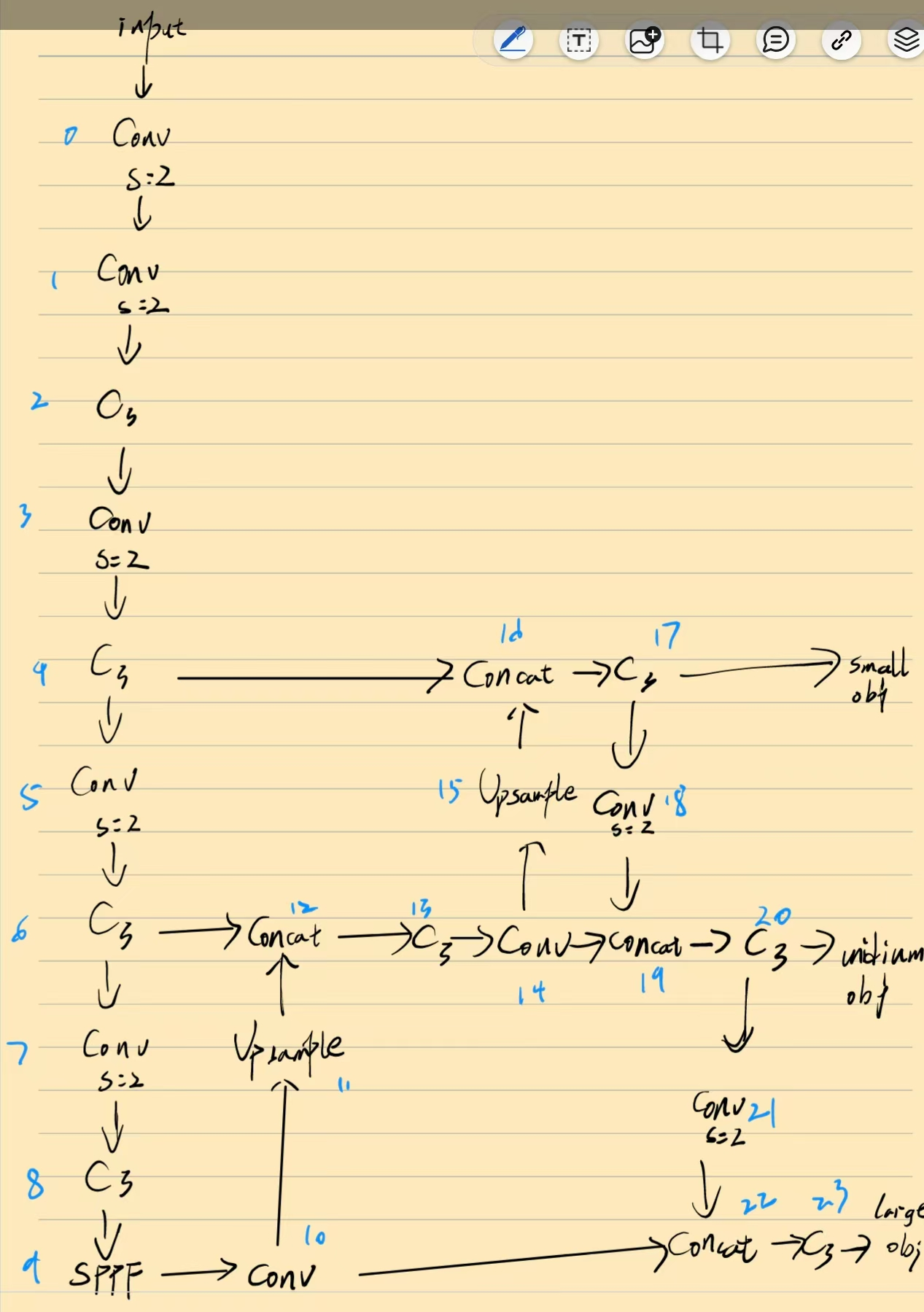
我为每一层加上了序号,这样会方便大家理解
还有这个P1、P2、P3代表不同的特征图分辨率,也就是主干网中每下采样一次,它的P就会变化
有些P后面还会加上P2/4,这里的4就是下采样相当于原图的4倍,也就是这一层的特征图分辨率是原图的1/4
加入4倍检测头后
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov5n.yaml' will call yolov5.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
s: [0.33, 0.50, 1024]
m: [0.67, 0.75, 1024]
l: [1.00, 1.00, 1024]
x: [1.33, 1.25, 1024]
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, Concat, [1]], # cat backbone P2
[-1, 3, C3, [128, False]], # 21 (P2/4-x small)
[-1, 1, Conv, [128, 3, 2]],
[[-1, 18], 1, Concat, [1]], # cat head P3
[-1, 3, C3, [256, False]], # 24 (P3/8-medium)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 27 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 30 (P5/32-large)
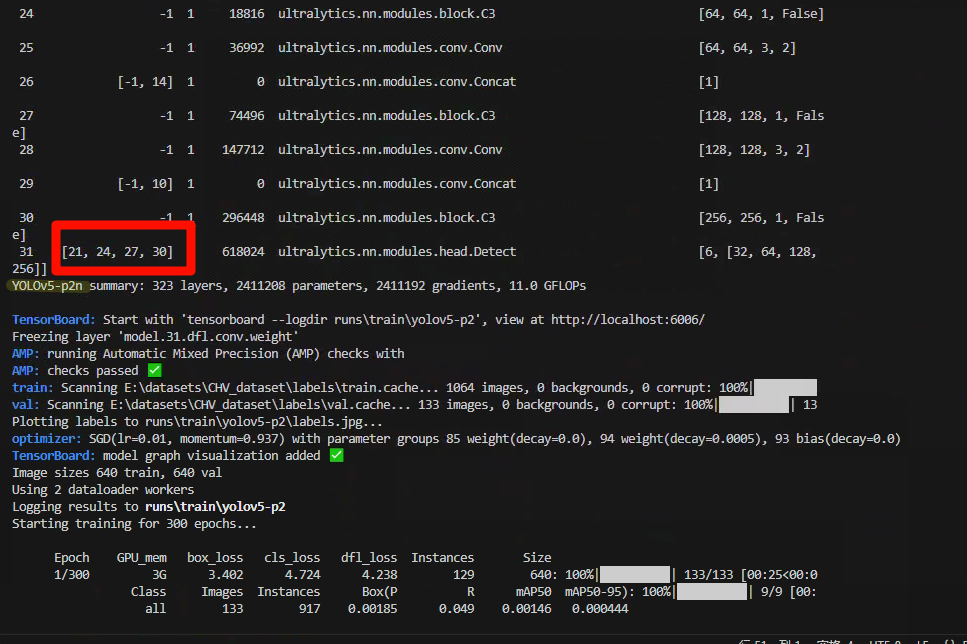
[[21,24,27,30], 1, Detect, [nc]], # Detect(P3, P4, P5)
]
加入P6检测头
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov5n-p6.yaml' will call yolov5-p6.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
s: [0.33, 0.50, 1024]
m: [0.67, 0.75, 1024]
l: [1.00, 1.00, 1024]
x: [1.33, 1.25, 1024]
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [768, 3, 2]], # 7-P5/32
[-1, 3, C3, [768]],
[-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 11
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [768, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 8], 1, Concat, [1]], # cat backbone P5
[-1, 3, C3, [768, False]], # 15
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 19
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 23 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 20], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 26 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 16], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [768, False]], # 29 (P5/32-large)
[-1, 1, Conv, [768, 3, 2]],
[[-1, 12], 1, Concat, [1]], # cat head P6
[-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
[[23, 26, 29, 32], 1, Detect, [nc]], # Detect(P3, P4, P5, P6)
]


















 9
9

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











