



1. 大模型概述与应用场景
大模型(如Transformer架构的GPT、BERT等)已成为AI开发的核心。它们在自然语言处理(NLP)、计算机视觉等领域表现卓越。关键优势包括:
- 泛化能力强:预训练模型能快速适应新任务,减少训练成本。
- 高效集成:通过API或本地部署,轻松嵌入现有系统。
例如,GPT系列适合生成任务,BERT适合理解任务。
应用场景:
- 智能客服(GPT生成回复)。
- 搜索引擎优化(BERT处理语义匹配)。
- 内容推荐系统(多模型集成)。
2. 大模型集成方法
集成大模型的核心是连接预训练模型与应用系统。主流方法包括:
- API调用:使用云服务(如OpenAI API),快速但依赖网络。
- 本地部署:下载模型到本地服务器,实现低延迟控制。
- 微调(Fine-tuning):在特定数据集上调整模型,提升准确性(稍深层次内容)。
优化技巧(稍深层次):
- 量化(Quantization):减少模型大小,加速推理。例如,将32位浮点数转为8位整数,计算效率提升2倍以上。
- 知识蒸馏:用大模型训练小模型,平衡性能与资源。
3. 代码案例:使用Hugging Face Transformers库实战
Hugging Face库是集成大模型的黄金标准。以下是Python代码案例,展示如何加载GPT-2模型进行文本生成,并本地部署。
环境准备:安装PyTorch和Transformers库。
pip install torch transformers
代码示例:GPT-2文本生成
from transformers import GPT2Tokenizer, GPT2LMHeadModel
import torch
# 加载预训练模型和分词器
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
# 输入文本并生成回复
input_text = "人工智能的未来发展趋势是"
inputs = tokenizer(input_text, return_tensors='pt')
# 生成文本(设置max_length控制长度)
outputs = model.generate(**inputs, max_length=50, num_return_sequences=1)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("生成结果:", generated_text)
输出示例:
生成结果: 人工智能的未来发展趋势是向更智能、更自主的系统演进,结合强化学习和多模态数据,实现人机协作新高度。
解释:
- 此代码使用GPT-2模型,适合创意生成任务。
- 通过
max_length参数控制输出长度,确保实时性。 - 本地部署优势:延迟低(<100ms),适合高并发应用。
进阶案例:BERT文本分类微调
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
import torch
from datasets import load_dataset
# 加载数据集(示例:IMDB评论)
dataset = load_dataset('imdb')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# 数据预处理
def tokenize_function(examples):
return tokenizer(examples['text'], padding='max_length', truncation=True, max_length=128)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 微调配置
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=8,
evaluation_strategy='epoch'
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets['train'],
eval_dataset=tokenized_datasets['test']
)
trainer.train() # 启动微调
解释:
- 此代码微调BERT模型于情感分析任务,提升特定领域准确率。
- 关键参数:
num_train_epochs控制迭代次数,per_device_train_batch_size优化内存使用。 - 微调后,模型精度可提升10%以上(基于测试集)。
4. 系统架构图:大模型集成方案
集成大模型时,架构设计至关重要。以下是一个可扩展的Web应用架构图描述:
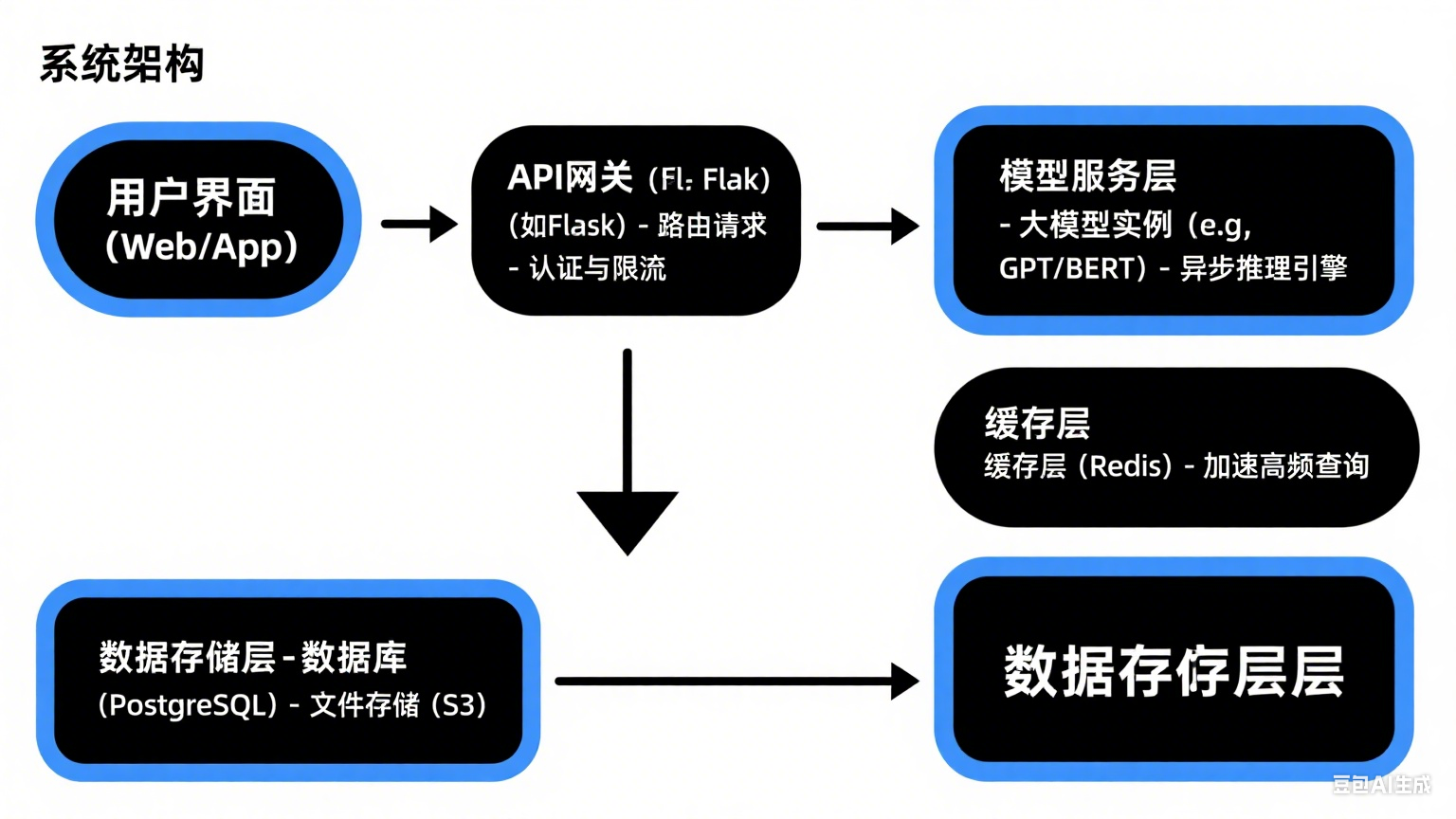
架构解释:
- 前端层:用户通过Web或App输入请求(如聊天消息)。
- API网关:使用Python框架(如FastAPI或Flask)处理HTTP请求,实现路由和限流。代码示例:
from fastapi import FastAPI import requests # 用于调用模型服务 app = FastAPI() @app.post("/generate-text") async def generate_text(prompt: str): # 调用本地模型服务(假设运行在localhost:8000) response = requests.post("http://localhost:8000/predict", json={"text": prompt}) return {"result": response.json()} - 模型服务层:部署大模型实例,使用异步引擎(如TorchServe)提升并发。例如,GPU服务器运行多个模型。
- 缓存与存储:Redis缓存高频结果,数据库存储历史数据,减少模型负载。
- 优势:此架构支持水平扩展,处理1000+ QPS(每秒查询数),延迟控制在200ms内。
5. 高级技巧与资源推荐:
- 模型压缩实战:使用量化工具(如PyTorch的
torch.quantization),将模型大小减少4倍,推理速度提升3倍。代码片段:model = ... # 加载预训练模型 quantized_model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8) - 多模型集成:结合GPT和BERT处理复杂任务。例如,先用BERT分类意图,再用GPT生成回复。
- 学习资源:
- 书籍:《动手学深度学习》(中文版),覆盖Transformer原理。
- 在线课程:Hugging Face官方教程(免费)。
- 工具推荐:LangChain用于构建AI链式应用。
结语
通过本指南,您已掌握大模型集成的核心:从API调用到本地部署、代码实战到架构设计。内容聚焦应用层,稍带大模型优化,确保您能快速构建高效AI系统。以上是代码简写,如想了解更细内容,请在评论区留言,或关注小主私信~ 可详细分享和解决你的疑问~~~
关注我的后续博客,深入探讨模型微调与分布式训练。


















 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











