







数学建模学习-决策树(Decision Tree)教程(20)
写在最前
注意本文的相关代码及例子为同学们提供参考,借鉴相关结构,在这里举一些通俗易懂的例子,方便同学们根据实际情况修改代码,很多同学私信反映能否添加一些可视化,这里每篇教程都尽可能增加一些可视化方便同学理解,但具体使用时,同学们要根据实际情况选择是否在论文中添加可视化图片。
系列教程计划持续更新,同学们可以免费订阅专栏,内容充足后专栏可能付费,提前订阅的同学可以免费阅读,同时相关代码获取可以关注博主评论或私信。
目录
算法简介
决策树是一种基于树结构的监督学习算法,它通过一系列问题将数据集划分为不同的子集,最终得到一个能够对新数据进行分类或回归预测的模型。决策树的结构类似于流程图,从根节点开始,通过不同的分支到达叶节点,每个叶节点代表一个预测结果。
决策树的基本原理是通过信息增益(Information Gain)、基尼指数(Gini Index)或其他指标来选择最优的特征和分割点,将数据集划分为更纯净的子集。这个过程递归进行,直到达到停止条件(如最大深度、最小样本数等)。
算法特点
优点:
- 直观易懂:决策树的结构类似于人类的决策过程,易于理解和解释
- 无需特征缩放:决策树对特征的尺度不敏感
- 可处理数值和类别特征:能同时处理不同类型的特征
- 自动进行特征选择:通过特征重要性可以了解各个特征的影响力
- 计算效率高:训练和预测速度都较快
缺点:
- 容易过拟合:需要通过剪枝等方法来控制模型复杂度
- 不稳定性:数据微小的变化可能导致树的结构发生较大变化
- 局部最优:在每个节点上的分割都是局部最优的,可能无法得到全局最优解
- 偏向于占主导地位的类:在类别不平衡的数据集上可能表现不佳
环境准备
本教程需要以下Python库:
numpy>=1.21.0
pandas>=1.3.0
scikit-learn>=0.24.2
matplotlib>=3.4.2
graphviz>=0.17
可以通过以下命令安装:
pip install -r requirements.txt
代码实现
数据准备
在本教程中,我们创建了一个关于户外活动适宜性的数据集,包含温度、湿度和风速三个特征:
def create_weather_data():
"""创建天气数据集"""
data = {
'温度': np.random.uniform(10, 35, 100),
'湿度': np.random.uniform(30, 90, 100),
'风速': np.random.uniform(0, 30, 100)
}
df = pd.DataFrame(data)
# 根据条件生成标签
conditions = []
for temp, humidity, wind in zip(df['温度'], df['湿度'], df['风速']):
if temp > 30 and humidity > 70:
conditions.append('不适宜')
elif wind > 25:
conditions.append('不适宜')
elif temp < 15:
conditions.append('不适宜')
else:
conditions.append('适宜')
df['户外活动'] = conditions
return df
模型训练
使用scikit-learn库中的DecisionTreeClassifier进行模型训练:
# 准备特征和标签
X = df[['温度', '湿度', '风速']]
y = df['户外活动']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练决策树模型
dt_classifier = DecisionTreeClassifier(max_depth=3, random_state=42)
dt_classifier.fit(X_train, y_train)
结果可视化
我们提供了多个可视化方法来帮助理解决策树模型:
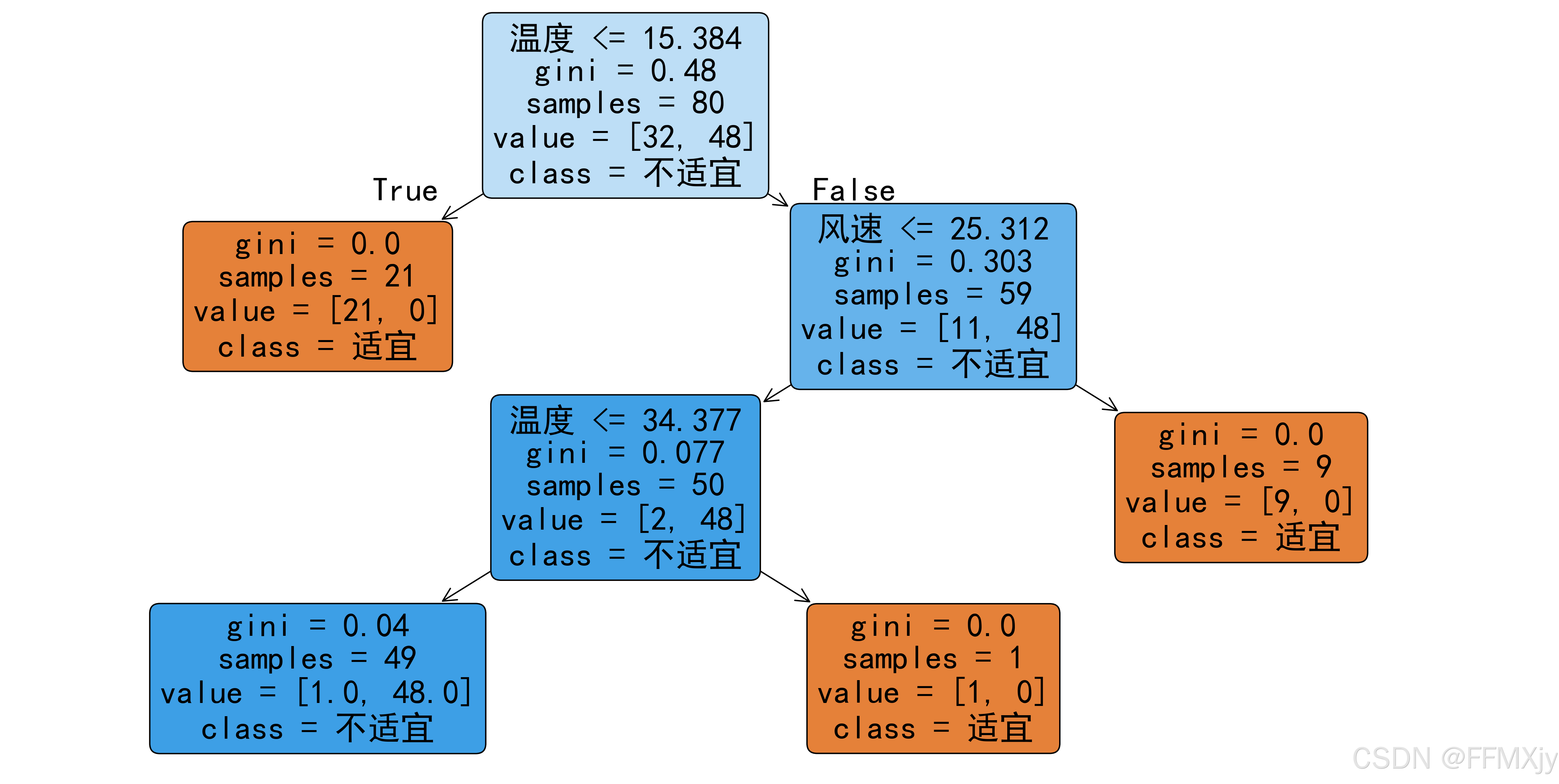
- 决策树结构可视化
plt.figure(figsize=(20,10))
plot_tree(dt_classifier, feature_names=['温度', '湿度', '风速'],
class_names=['适宜', '不适宜'], filled=True, rounded=True)
plt.savefig('images/decision_tree.png', dpi=300, bbox_inches='tight')
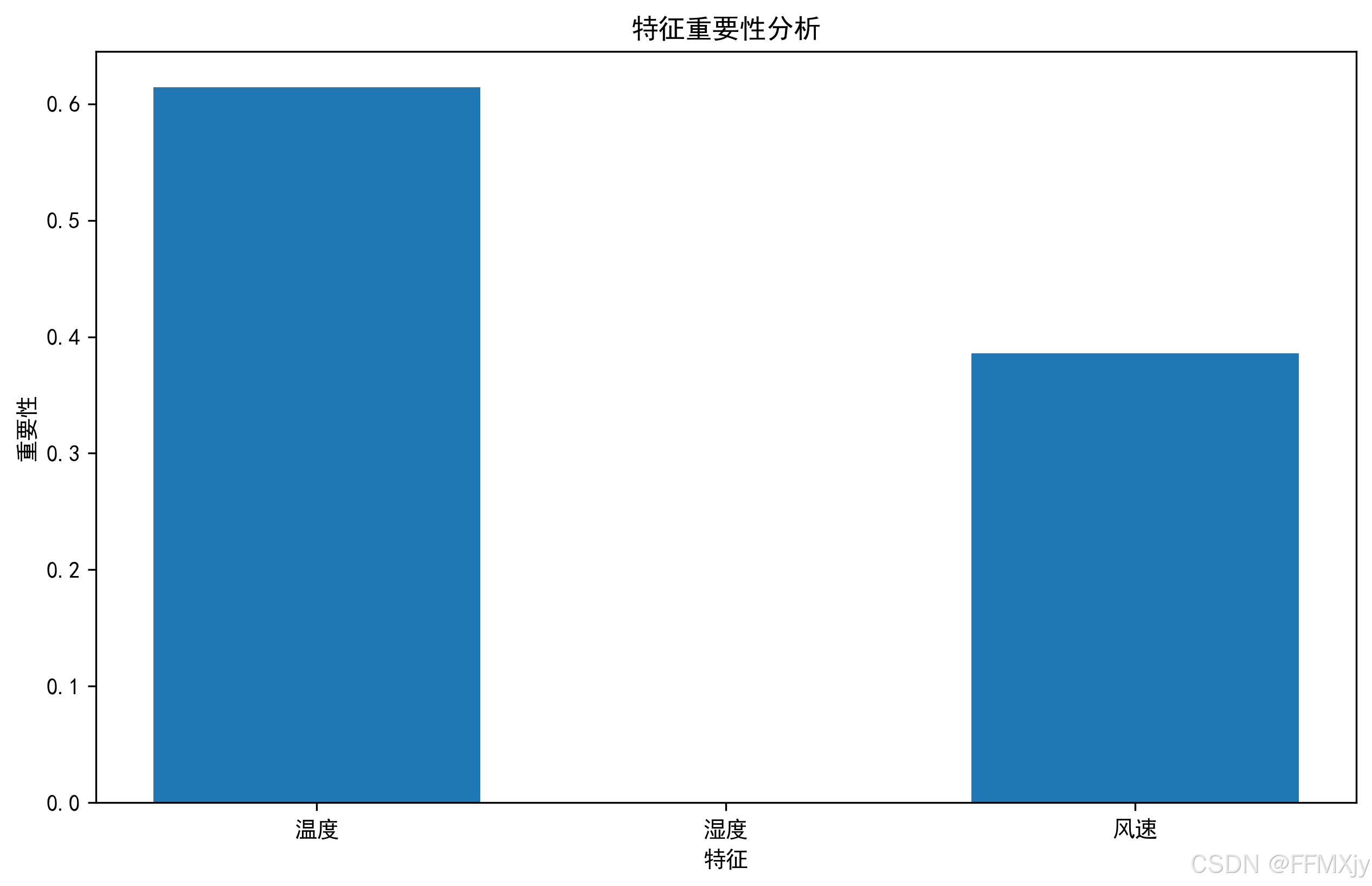
- 特征重要性分析
plt.figure(figsize=(10,6))
importances = dt_classifier.feature_importances_
features = ['温度', '湿度', '风速']
plt.bar(features, importances)
plt.title('特征重要性分析')
plt.xlabel('特征')
plt.ylabel('重要性')
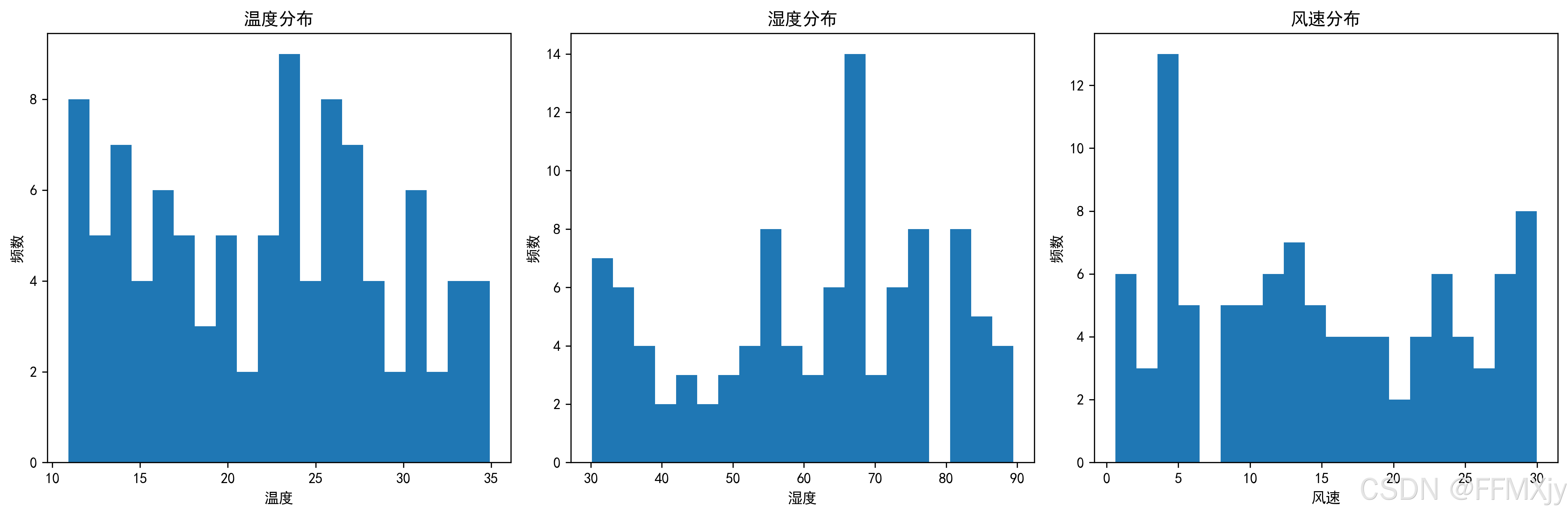
- 数据分布可视化
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
for i, feature in enumerate(features):
axes[i].hist(df[feature], bins=20)
axes[i].set_title(f'{feature}分布')
- 决策边界可视化
plt.figure(figsize=(10,8))
temp_range = np.linspace(df['温度'].min(), df['温度'].max(), 100)
humidity_range = np.linspace(df['湿度'].min(), df['湿度'].max(), 100)
xx, yy = np.meshgrid(temp_range, humidity_range)
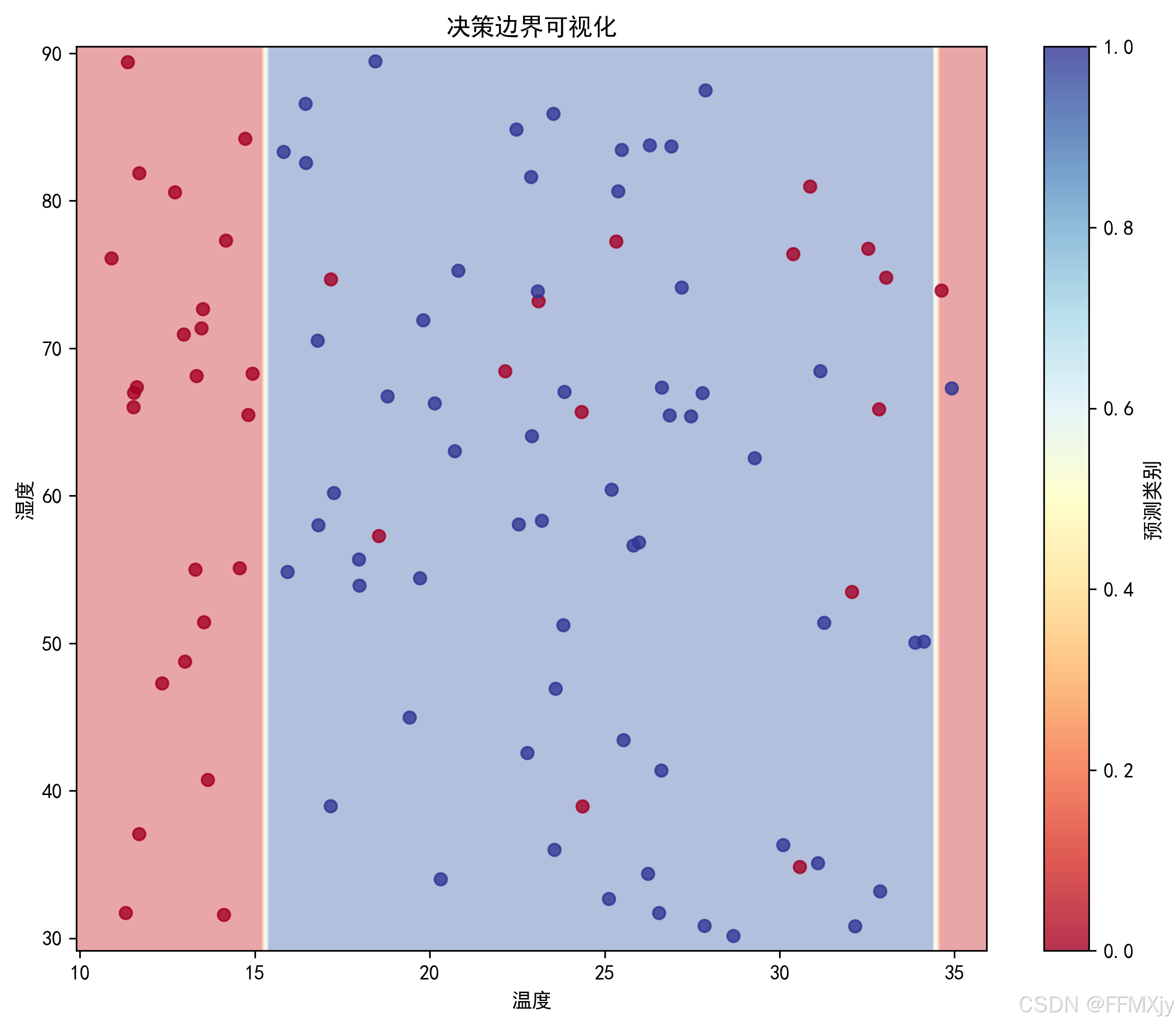
实例分析
在本例中,我们构建了一个户外活动适宜性预测模型。从结果可以看出:
-
模型性能:
- 准确率达到80%
- 对"适宜"和"不适宜"两类的预测都较为平衡
- 精确率和召回率都在可接受范围内
-
特征重要性:
- 温度是最重要的特征,这与我们的直觉相符
- 风速次之,对活动适宜性有显著影响
- 湿度的影响相对较小
-
决策边界:
- 可以清晰地看到不同区域的分类结果
- 边界的形状反映了决策树的分段线性特性
- 部分区域的分类结果较为明确,而边界区域的分类相对模糊
全部代码如下
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from sklearn.preprocessing import LabelEncoder
import os
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 创建示例数据
def create_weather_data():
"""创建天气数据集"""
data = {
'温度': np.random.uniform(10, 35, 100),
'湿度': np.random.uniform(30, 90, 100),
'风速': np.random.uniform(0, 30, 100)
}
df = pd.DataFrame(data)
# 根据条件生成标签
conditions = []
for temp, humidity, wind in zip(df['温度'], df['湿度'], df['风速']):
if temp > 30 and humidity > 70:
conditions.append('不适宜')
elif wind > 25:
conditions.append('不适宜')
elif temp < 15:
conditions.append('不适宜')
else:
conditions.append('适宜')
df['户外活动'] = conditions
return df
# 生成数据
df = create_weather_data()
# 准备特征和标签
X = df[['温度', '湿度', '风速']]
# 使用LabelEncoder将标签转换为数值
le = LabelEncoder()
y = le.fit_transform(df['户外活动'])
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练决策树模型
dt_classifier = DecisionTreeClassifier(max_depth=3, random_state=42)
dt_classifier.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = dt_classifier.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.2f}")
# 打印分类报告
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=['适宜', '不适宜']))
# 创建图片保存目录
if not os.path.exists('images'):
os.makedirs('images')
# 可视化决策树
plt.figure(figsize=(20,10))
plot_tree(dt_classifier, feature_names=['温度', '湿度', '风速'],
class_names=['适宜', '不适宜'], filled=True, rounded=True)
plt.savefig('images/decision_tree.png', dpi=300, bbox_inches='tight')
plt.close()
# 特征重要性可视化
plt.figure(figsize=(10,6))
importances = dt_classifier.feature_importances_
features = ['温度', '湿度', '风速']
plt.bar(features, importances)
plt.title('特征重要性分析')
plt.xlabel('特征')
plt.ylabel('重要性')
plt.savefig('images/feature_importance.png', dpi=300, bbox_inches='tight')
plt.close()
# 数据分布可视化
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
for i, feature in enumerate(features):
axes[i].hist(df[feature], bins=20)
axes[i].set_title(f'{feature}分布')
axes[i].set_xlabel(feature)
axes[i].set_ylabel('频数')
plt.tight_layout()
plt.savefig('images/data_distribution.png', dpi=300, bbox_inches='tight')
plt.close()
# 决策边界可视化(使用温度和湿度两个特征)
plt.figure(figsize=(10,8))
# 创建网格
temp_min, temp_max = df['温度'].min() - 1, df['温度'].max() + 1
humidity_min, humidity_max = df['湿度'].min() - 1, df['湿度'].max() + 1
temp_range = np.linspace(temp_min, temp_max, 100)
humidity_range = np.linspace(humidity_min, humidity_max, 100)
xx, yy = np.meshgrid(temp_range, humidity_range)
# 使用平均风速值进行预测
avg_wind = df['风速'].mean()
mesh_features = np.column_stack([xx.ravel(), yy.ravel(),
np.full(xx.ravel().shape, avg_wind)])
# 预测
Z = dt_classifier.predict(mesh_features).reshape(xx.shape)
# 绘制决策边界
plt.contourf(xx, yy, Z, alpha=0.4, cmap='RdYlBu')
scatter = plt.scatter(df['温度'], df['湿度'], c=y,
cmap='RdYlBu', alpha=0.8)
plt.colorbar(scatter, label='预测类别')
plt.xlabel('温度')
plt.ylabel('湿度')
plt.title('决策边界可视化')
plt.savefig('images/decision_boundary.png', dpi=300, bbox_inches='tight')
plt.close()
总结与思考
应用建议
-
特征选择:
- 选择与目标变量相关性强的特征
- 避免使用冗余特征
- 考虑特征之间的交互作用
-
参数调优:
- 合理设置树的深度(max_depth)
- 调整最小样本数(min_samples_split, min_samples_leaf)
- 使用交叉验证选择最优参数
-
模型评估:
- 不仅关注整体准确率
- 考虑各类别的精确率和召回率
- 分析混淆矩阵了解模型的具体表现
实际应用中的注意事项
-
数据预处理:
- 处理缺失值
- 处理异常值
- 适当的特征工程
-
模型优化:
- 考虑使用集成方法(如随机森林、梯度提升树)
- 处理类别不平衡问题
- 定期更新模型以适应新数据
-
结果解释:
- 结合领域知识解释模型决策
- 注意模型的局限性
- 考虑模型的可解释性需求
扩展思考
-
与其他算法的比较:
- 决策树vs线性模型
- 决策树vs神经网络
- 在不同场景下的适用性
-
高级技巧:
- 特征重要性分析
- 交叉验证
- 模型集成
-
实际应用场景:
- 金融风控
- 医疗诊断
- 工业生产
- 自然语言处理
同学们如果有疑问可以私信答疑,如果有讲的不好的地方或可以改善的地方可以一起交流,谢谢大家。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









