




【全文大纲】 : https://blog.youkuaiyun.com/Engineer_LU/article/details/135149485
1 . 前言总结
一般来说,C语言有符号与无符号比较,编译器默认情况下,如果有符号的值在无符号类型的范围内,则比较将基于该值转换到无符号类型中的表示,如果值超出无符号类型的范围,则行为是超纲的,以下便详解此类
2 . 有符号类型与8,16,32位无符号类型比较问题
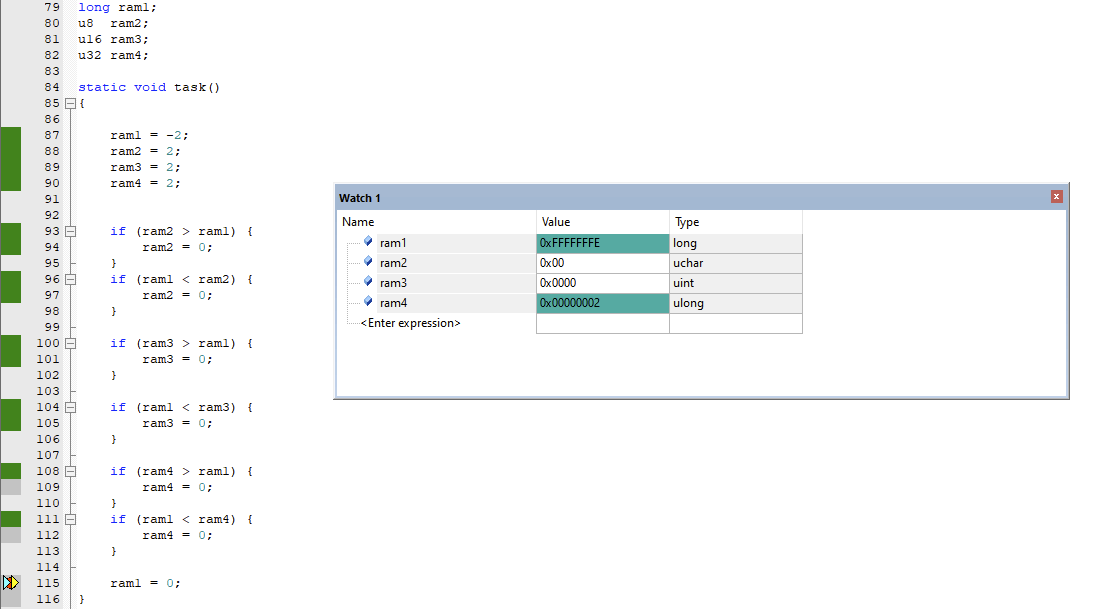
下图程序运行过后可看到ram1,ram2,ram3的结果为0,但是ram4的结果为2,理论上全部都是0,为什么ram的结果是2,这里就抛出有符号和无符号比较的问题了,当有符号的值在无符号范围内会把有符号转换成无符号比较 ,因此转换成十六进制后ram1为0xFFFFFFFF,而ram4是0x00000002,0xFFFFFFFF>0x00000002,所以造成了2<-1,那么ram2和ram3呢,为什么看起来正常的,因为有符号的值已经大于无符号的范围了,编译器就不知道该怎么判断,此时行为是不确定的,虽然看起来正常,但不可相信这个结果。
3 . 有符号类型与8,16,32位无符号类型比较验证
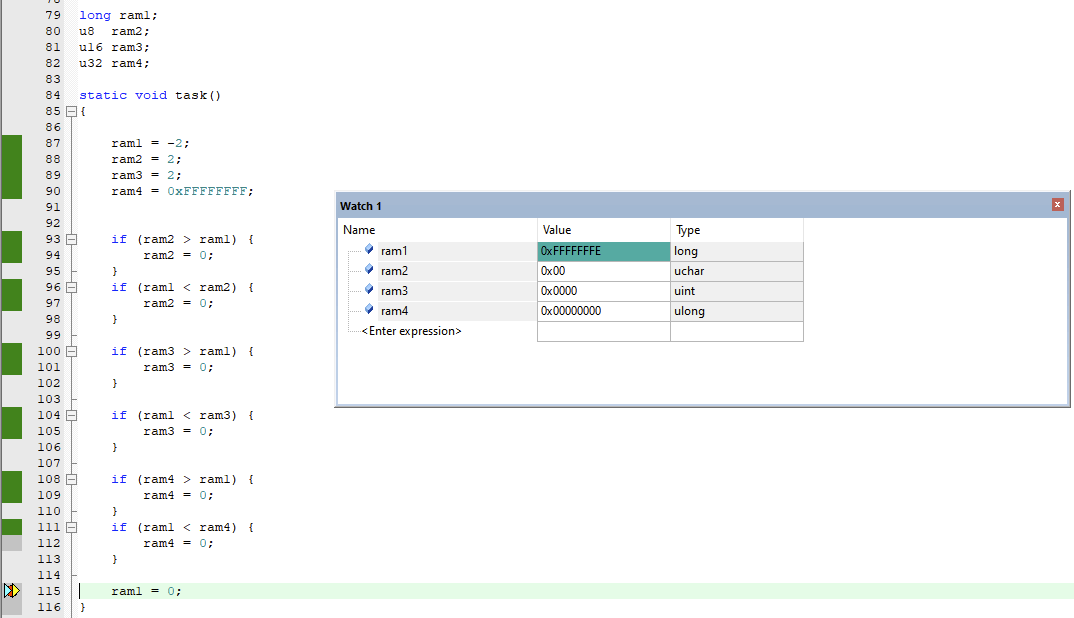
验证是否如上图所说的逻辑,可看到下图当ram4设成0xFFFFFFFF与ram1的值-1比较时,是大于-1的,是因为都转换到无符号后,0xFFFFFFFF>0xFFFFFFFE
4 . 细节扩展
为了深入贯彻以上的逻辑,思考一下编译器为什么这么做,这就要回归计算机补码,反码,正码的概念,计算器为了让负数与正数循环方便计算,因此当32位平台long有符号类型从0改成-1后,-1的存储值为0xFFFFFFFF,最高位为1时为负数,当0xFFFFFFFF+1时就回到0,方便计算机运算,但也因此导致有符号与无符号比较时产生了歧义,这里可能有疑问,编译器为什么不识别到用户写的是负数,那就完全按现实里的负数与正数比较,这里又产生了一个问题,计算机里的判断逻辑是编译器赋予的,有些编译器目前是不聪明的,它只知道按照二进制判断,所谓的正数负数判断也是编译器识别用户行为在二进制判断的基础上加入二次判断逻辑,这样一来,各平台各编译器的标准差异性就体现出来了,所以为了程序的稳定性,移植性,在写这种逻辑的程序时尽量兼顾 当有符号的值在无符号范围内会把有符号转换成无符号比较 这个逻辑,避免不同类型比较,如果确实需要不同类型的有符号/无符号之间比较,那么就人为强制转换比较。
5 . 总结
C语言的编译器百花齐放,了解编译器的编译行为有助于对程序稳定性的加固,上述情况在实际开发中尽量避免不同类型的有/无符号之间比较,再次抛出比较的概念 当有符号的值在无符号范围内会把有符号转换成无符号比较,有符号的值超出无符号范围会让编译器无所适从 ,根据这段语意编写的程序从稳定性,移植性上是让人放心的,谢谢观看
技术交流群 : 745662457
群内专注 - 问题答疑,技术研究



















 3500
3500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











