



现在 AI 越来越火,但很多在线 AI 服务受网络限制,还存在数据安全风险。这时候,AI 本地部署就派上用场了!把 AI 部署在自己的设备上,不仅用起来更流畅,数据也更安全。今天就给大家分享实用的AI软件,手把手教你轻松完成 AI 本地部署,让你也能成为 AI 应用小能手!
一、DS 本地部署大师
DS 本地部署大师堪称 AI 本地部署的 “全能管家”,对新手特别友好。它内置丰富的 AI 模型库,不管是用于文档阅读的 NLP 模型,还是图像识别模型,都能一键获取,无需你到处找资源。软件自带可视化部署界面,通过简单的拖拽、设置参数操作,就能完成复杂的 AI 部署流程,完全不用敲一堆代码。
软件下载链接:DS本地部署大师 - Deepseek本地部署工具_零基础安装在本地
操作步骤:
①打开软件,下载模型,进入主界面,在主界面找到 “立即体验”进入智能解答界面。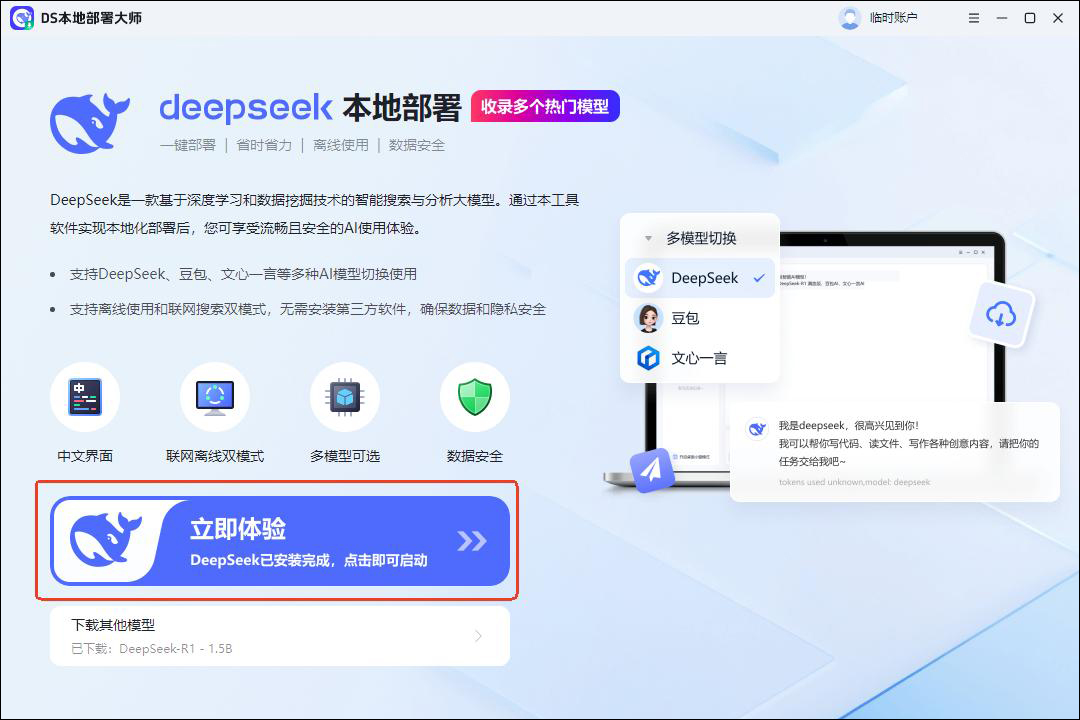
②随后,点击模型,选择合适的模型,支持快模式、deepseek、豆包、文心一言。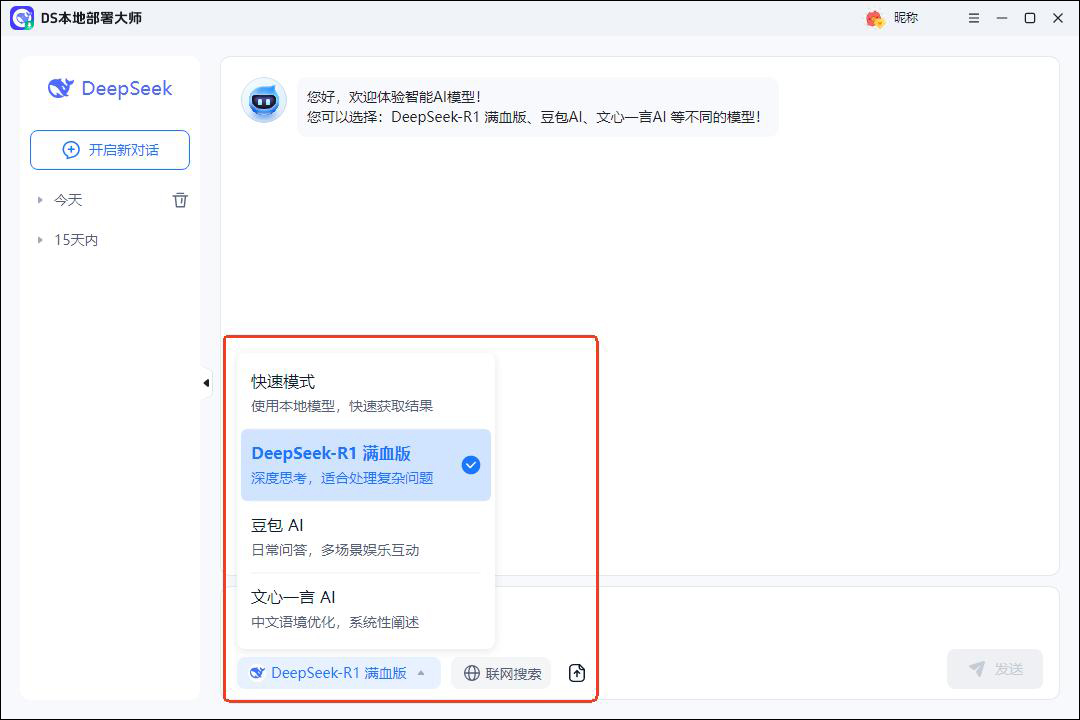
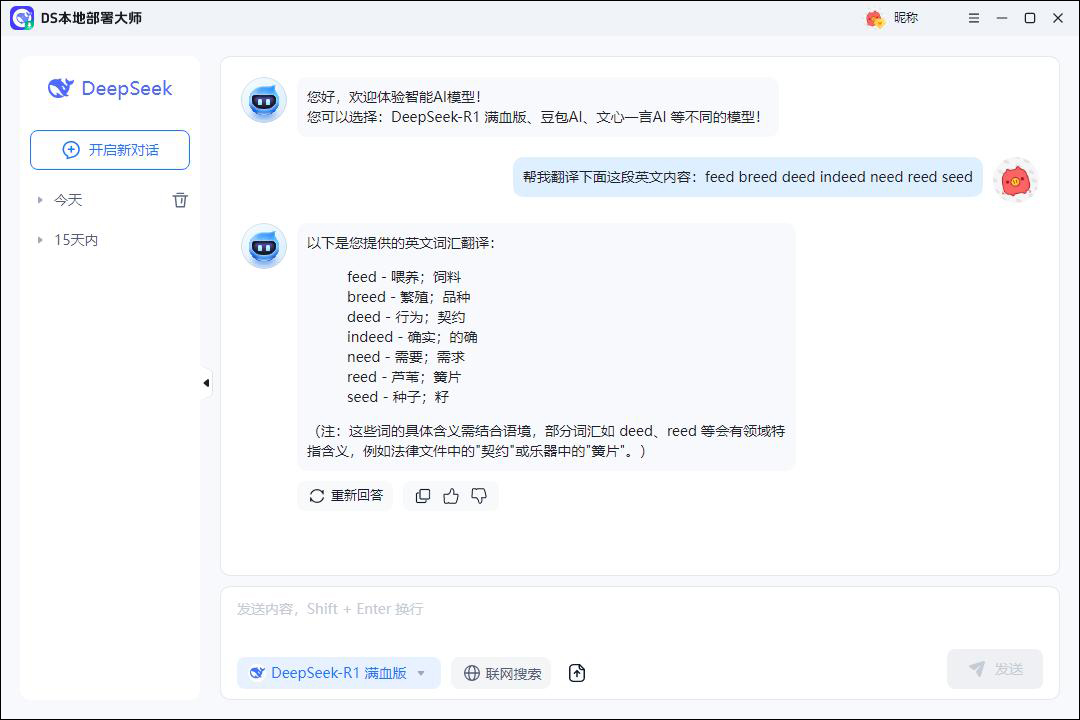
③进入之后,在软件中进行智能提问,如翻译、写文章、改文案等,完成后,复制内容即可。
二、Stable Diffusion
Stable Diffusion 原本是强大的图像生成模型,经过扩展,在文档理解方面也有不错表现。它能将文档中的文字信息转化为可视化图像,帮助你更直观地理解文档内容。比如阅读旅游攻略文档,它能生成景点地图、特色美食插画等。
操作步骤:
①安装好软件后,打开程序,在插件管理界面启用文档理解扩展功能。
②点击 “导入文档”,选择要阅读的文件,软件会自动分析文档内容。
③在输出设置里,选择你想要的可视化风格和总结语言风格。
④设置完成,点击“生成”看到生成的可视化图像和文字总结了,对生成的内容进行编辑和保存。
三、GPT-Neo
GPT-Neo 是一款超厉害的开源语言模型,本地部署后,在文档阅读领域那可是大显身手。它就像一个不知疲倦的 “阅读高手”,再长的文档在它面前也不在话下,能完整又准确地提取信息、总结要点。而且,它还特别 “听话”,支持个性化训练。
操作步骤:
①首先,得从 GitHub 上把 GPT-Neo 的代码仓库克隆到自己电脑上。
②这些准备工作做好后,去下载预训练的 GPT-Neo 模型权重文件,下载完放到指定目录。
③接下来,打开命令行,进入代码目录,运行训练和推理脚本。
④这时候,按照提示配置模型参数,设置好输出结果保存的路径。
四、ELECTRA
LECTRA 模型采用了独特的预训练方法,在理解文档语义方面有着独特的优势,就像一个 “语义侦探”。阅读文档时,它能快速精准地识别出重要信息,自动忽略那些无关紧要的内容,一下子就能提炼出核心要点。它的训练效率特别高,本地部署后运行速度飞快,处理起大量
文档也不费劲,能帮你节省超多时间。
操作步骤:
①首先,在GitHub上仔细找找 ELECTRA 的开源代码和预训练模型,找到后下载到电脑里。
②然后,安装 Python 和相关依赖库,像 PyTorch,安装过程跟着教程走就行。
③把预训练模型下载好后,放到指定位置,打开命令行,进入代码目录,运行训练脚本。
掌握AI本地部署后,再也不用眼巴巴等云端反应!写论文时,本地AI助手秒速帮你润色语句;设计海报,本地AI绘图工具能快速生成创意草稿。甚至在家DIY动漫头像,也能轻松让角色摆出你想要的姿势。以后用AI,就像随手打开电脑里的文档一样丝滑,这些宝藏部署方式,现在就动手试试,解锁你的专属AI使用体验!


















 1179
1179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









