



Datawhale分享
测评结果:DeepSeek,编辑:量子位
DeepSeek-R1,正在接受全球网友真金白银的检验。
花30秒用manim代码制作解释勾股定理的动画,一次完成无错误。

为了玩上这样的模型,有人花上10多万元,组7台M4 Pro Mac mini+1台M4 Max Macbook Pro的家用超算。

总计496G显存(64*7+48),才能跑起个4bit量化版,但属实算得上“家用AGI”配置了。

另一个极端是选择R1数据蒸馏版Qwen 1.5B小模型,小到浏览器就能跑,每秒能输出60个tokens。
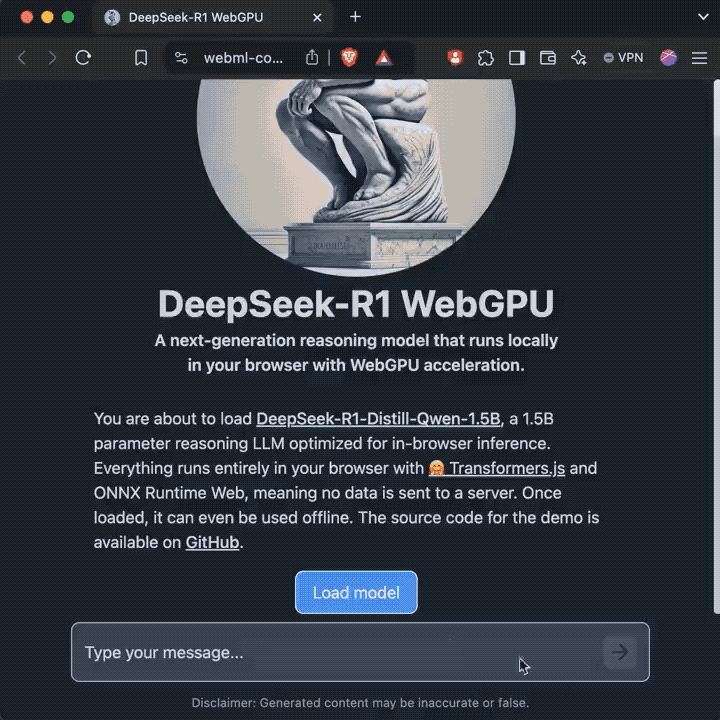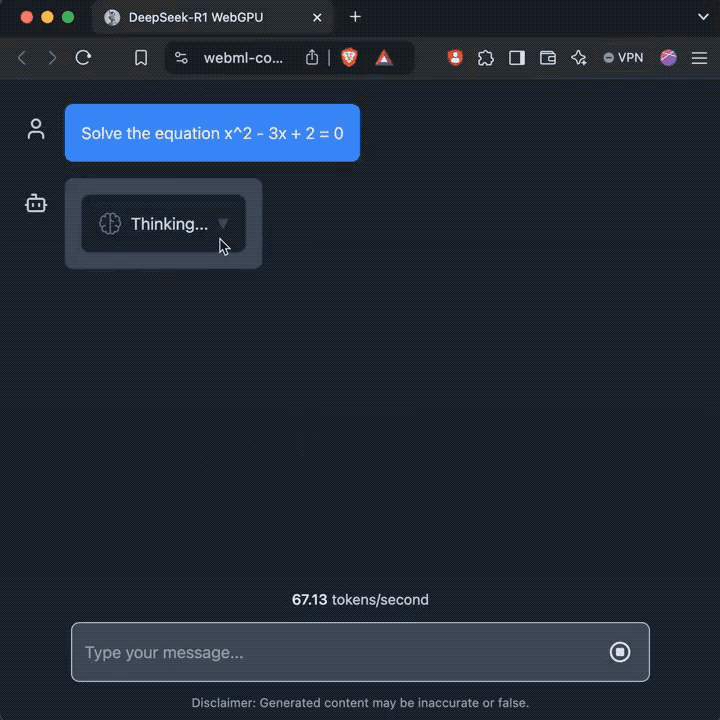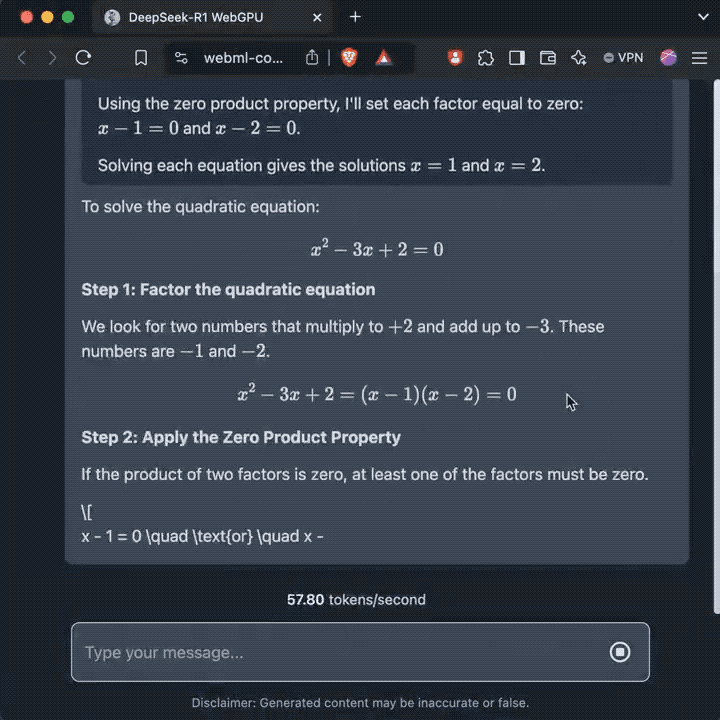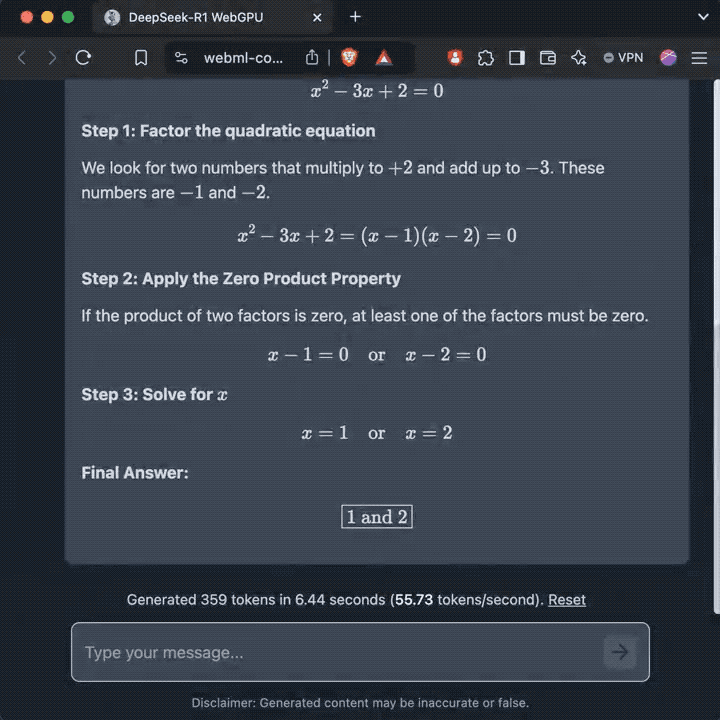
与此同时,各种榜单也在抓紧测试,纷纷跑出了结果。
R1横扫各大榜单
首先是LiveBench,与LiveCodeBench一样,题目是随时间更新的,所以相对受认可。
R1的表现在o1-preview到o1之间,其中只有数据一项超过o1。
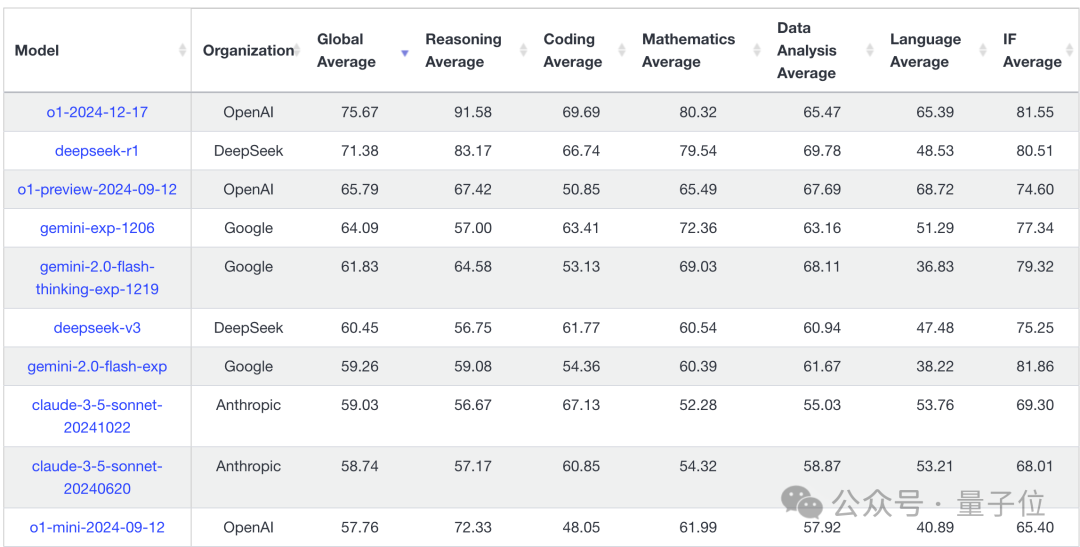
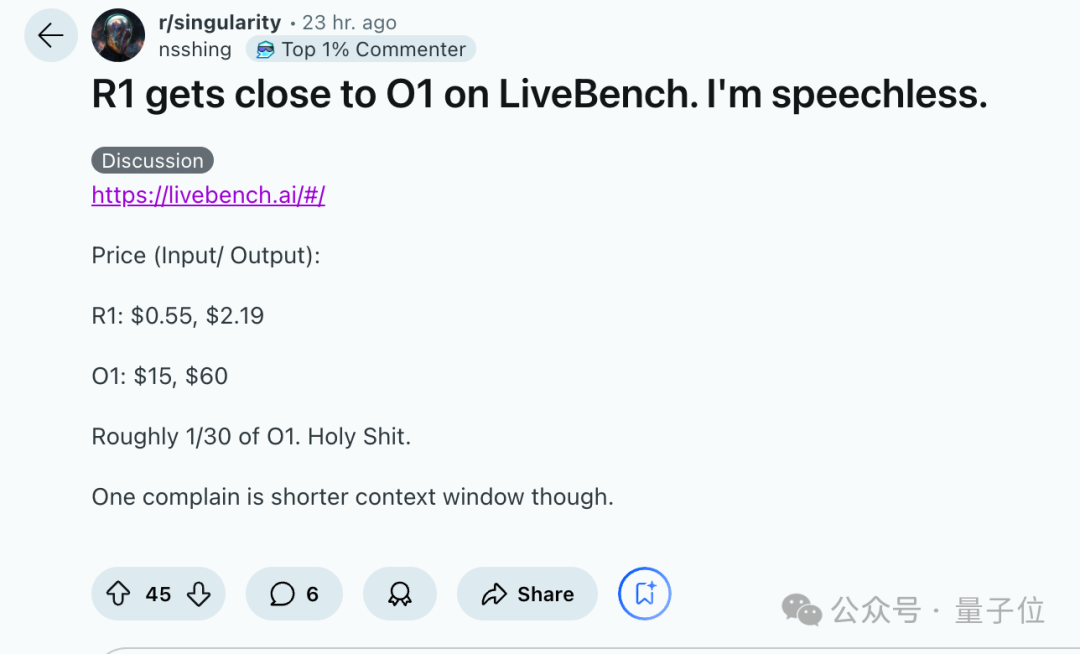
不过再带上成本成本约1/30这个条件看,又是不一样的感觉,给老哥整无语了。
唯一的抱怨是上下文窗口太短。
o1系列一战成名的ARC-AGI,测试结果分为公开数据和私有数据两部分。
DeepSeek R1在私有数据上解决了15.8%的问题,与DeepSeek-V3相比翻倍还多。
公开数据上更是解决了20.5%的问题,与DeepSeek-V3相比上涨约46%。
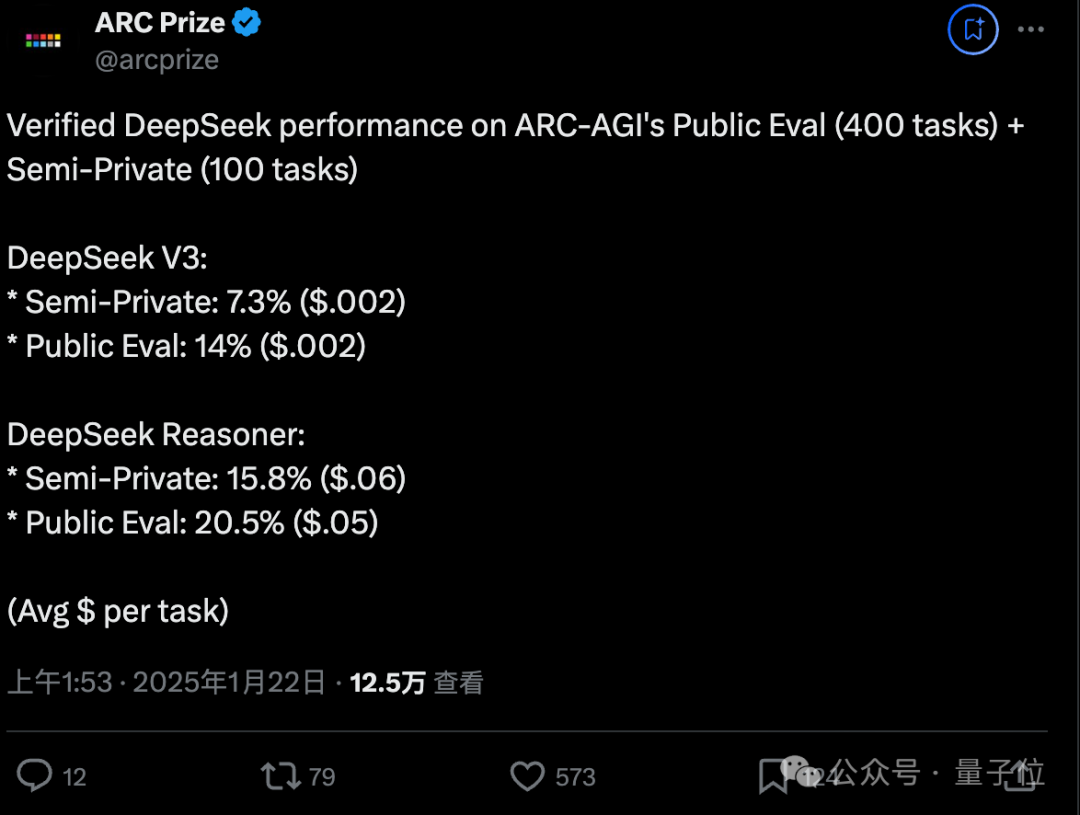
总的来看,DeepSeek-R1表现与o1-preview相近,但稍低。

但同样,带上几毛钱就能解决一道题,o1系列至少要10块钱这个背景来看,又是不一样的感觉。

考验任务规划能力的PlanBench,同样的剧本再次上演。
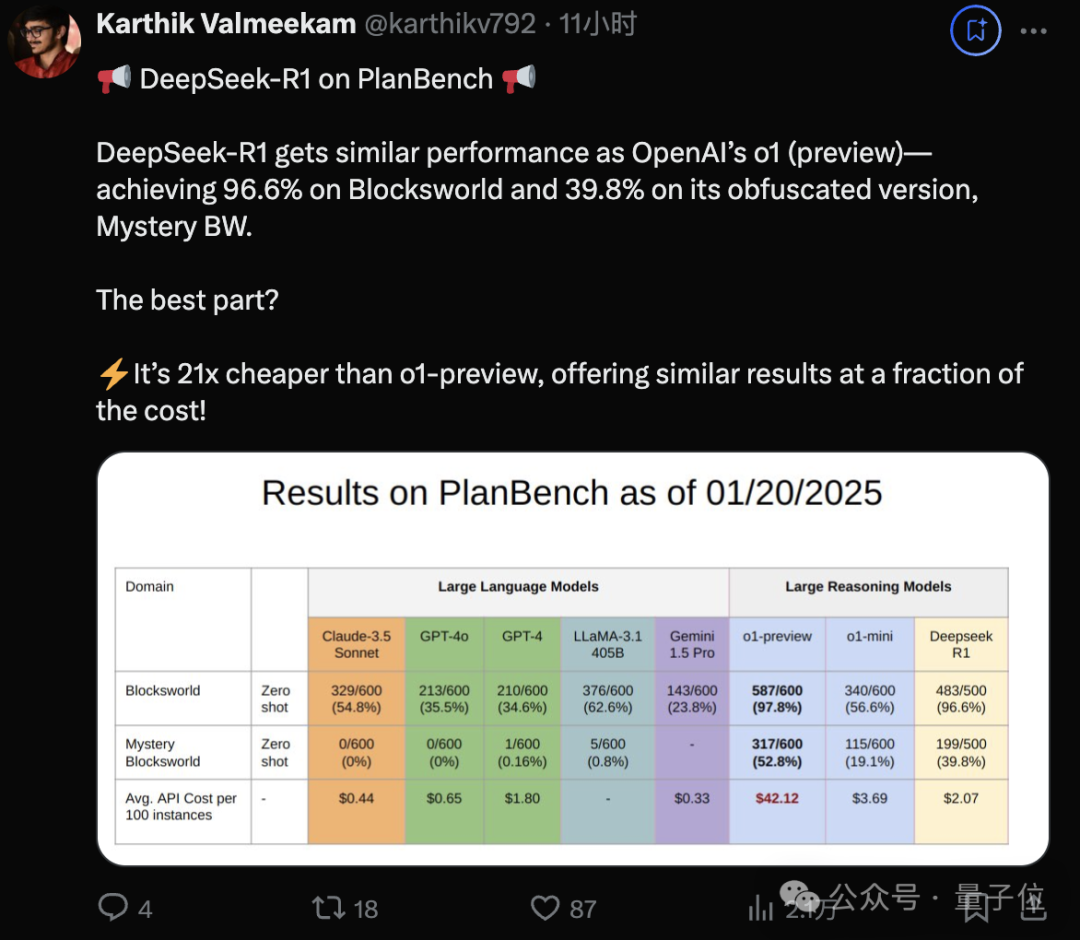
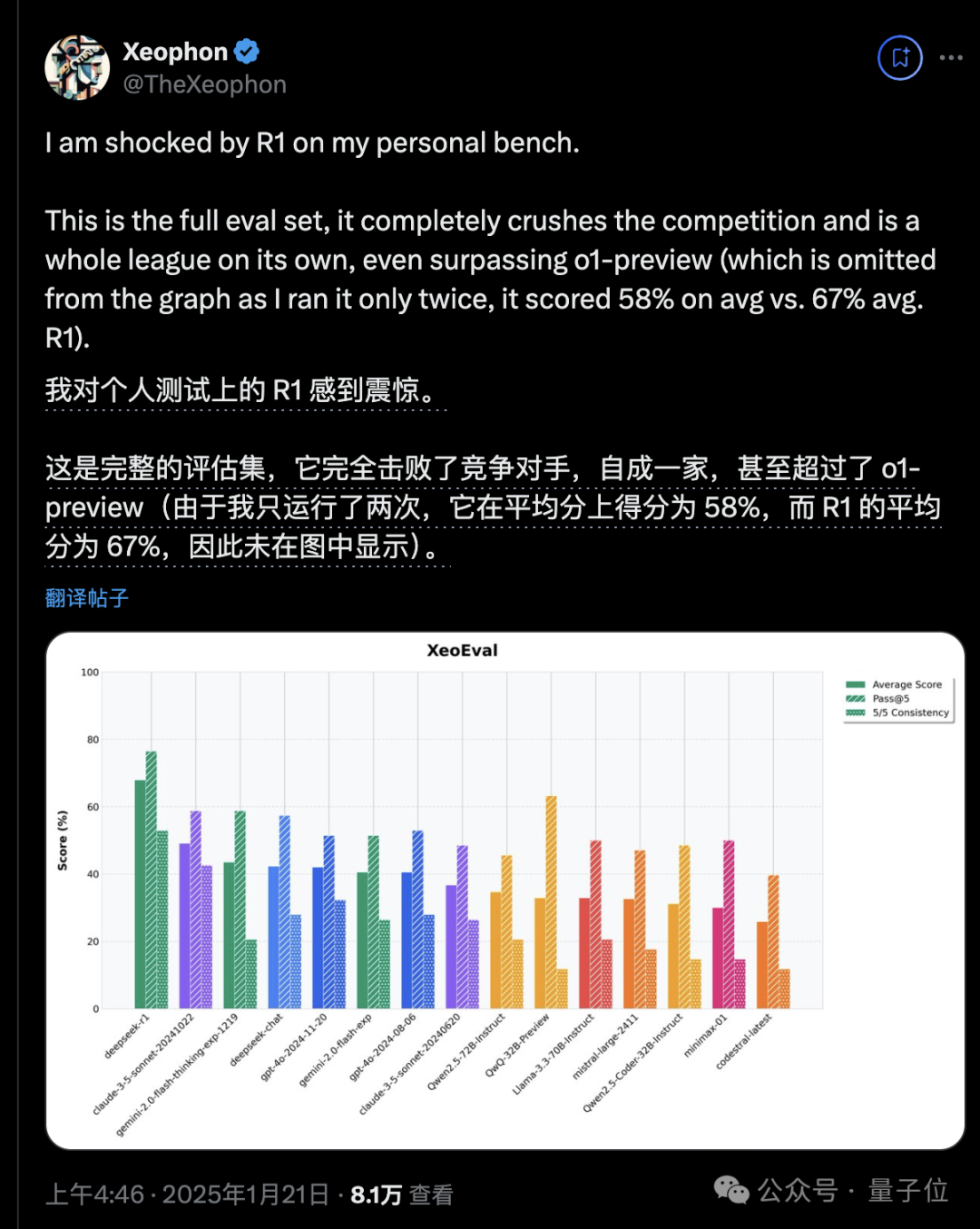
在开发者Xeophon自己的个人测试上,甚至超过了o1-preview。
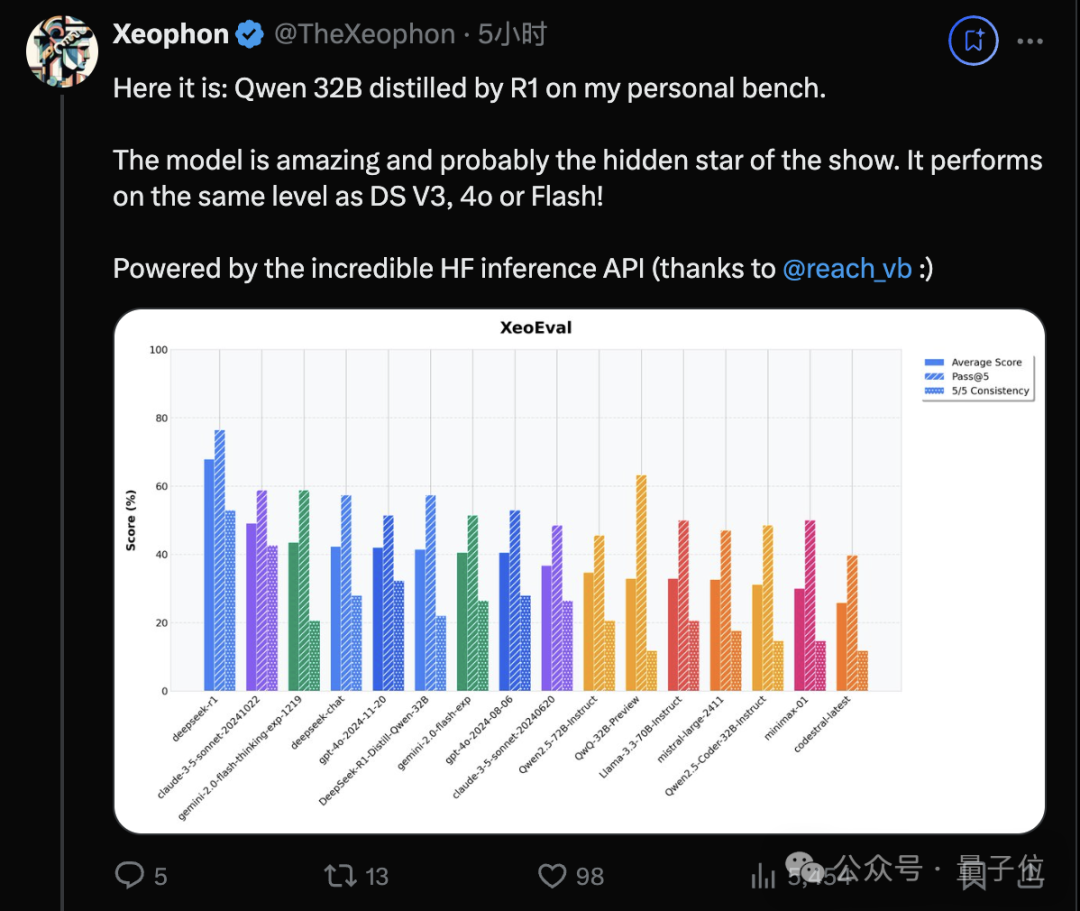
同一个测试上,R1数据蒸馏的Qwen 32B,与DeepSeek-V3,GPT-4o和Gemini Flash处于同一水平。
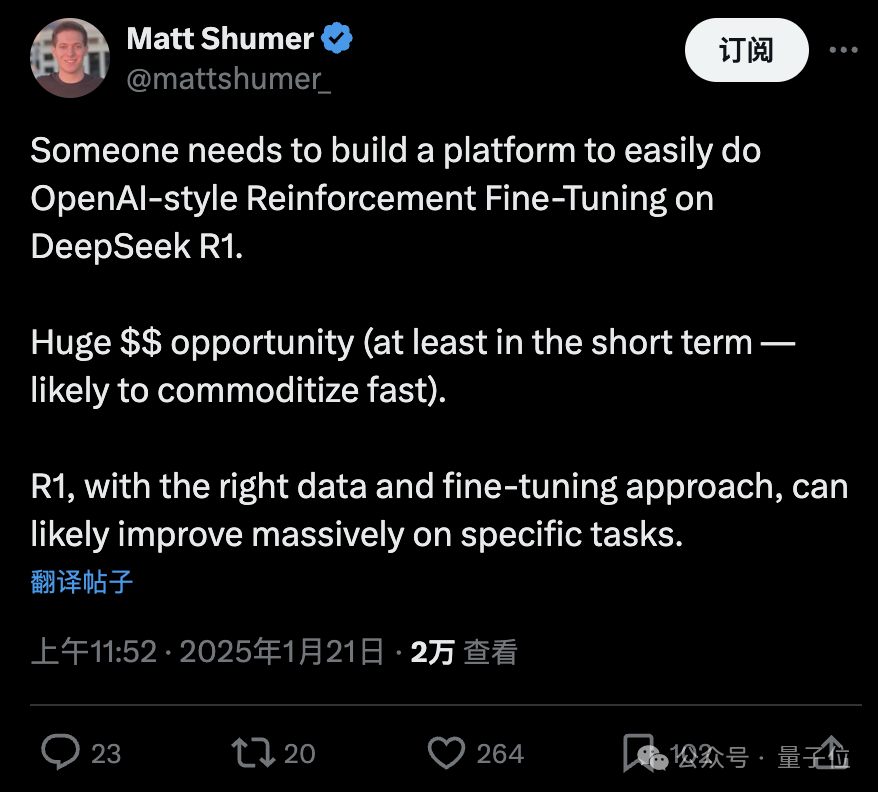
最后,还有人从中看到新的创业机会。
谁来构建一个平台,能轻松地在DeepSeek R1上进行OpenAI风格的强化微调。
至少在短期内,是一个巨大的机会。
R1在正确数据和微调方法下,可能在特定任务上大幅提升。
参考链接:
[1]https://x.com/alexocheema/status/1881561143736664180
[2]https://x.com/reach_vb/status/1881809400995934640
[3]https://livebench.ai/#/
[2]https://x.com/arcprize/status/1881761987090325517
[3]https://x.com/TheXeophon/status/1881443117787984265

一起点赞三连↓

















 1708
1708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









