




🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
数源AI 最新论文解读系列

论文名:SEE WHATYOUARETOLD: VISUALATTENTIONSINK IN LARGE MULTIMODAL MODELS
论文链接:https://arxiv.org/pdf/2503.03321
导读
大型多模态模型(LMMs)一直在积极拓展大语言模型在多模态任务中的能力。特别是,大型多模态模型利用预训练的视觉编码器处理图像数据,并使用大语言模型的Transformer解码器生成文本响应。这种简单而强大的架构已被证明在视觉问答、图像描述和视觉推理等视觉 - 语言任务中,利用图像中的视觉信息非常有效。
简介
大型多模态模型(LMMs)通过利用Transformer解码器中文本和视觉标记之间的注意力机制来“查看”图像。理想情况下,这些模型应聚焦于与文本标记相关的关键视觉信息。然而,近期研究发现,大型多模态模型有一种异常的倾向,即持续为特定视觉标记分配高注意力权重,即便这些标记与相应文本无关。在本研究中,我们探究了这些无关视觉标记出现背后的特性,并考察了它们的特征。我们的研究结果表明,这种行为是由于某些隐藏状态维度的大规模激活所致,这与语言模型中发现的注意力陷阱类似。因此,我们将这一现象称为视觉注意力陷阱。特别地,我们的分析显示,去除这些无关的视觉陷阱标记并不会影响模型性能,尽管它们获得了高注意力权重。因此,我们将分配给这些标记的注意力作为剩余资源进行回收,重新分配注意力预算以增强对图像的聚焦。为实现这一目标,我们引入了视觉注意力再分配(VAR)方法,该方法可在以图像为中心的头中重新分配注意力,我们发现这些头天生就聚焦于视觉信息。VAR可以无缝应用于不同的大型多模态模型,以提高其在广泛任务中的性能,包括通用视觉 - 语言任务、视觉幻觉任务和以视觉为中心的任务,且无需额外的训练、模型或推理步骤。实验结果表明,VAR通过调整大型多模态模型的内部注意力机制,使其能够更有效地处理视觉信息,为提升大型多模态模型的多模态能力提供了新方向。
方法与模型
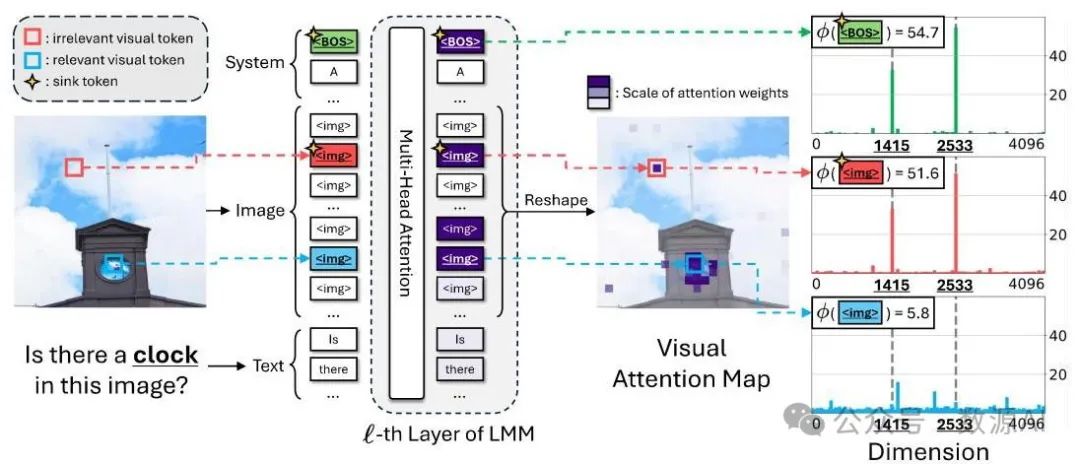
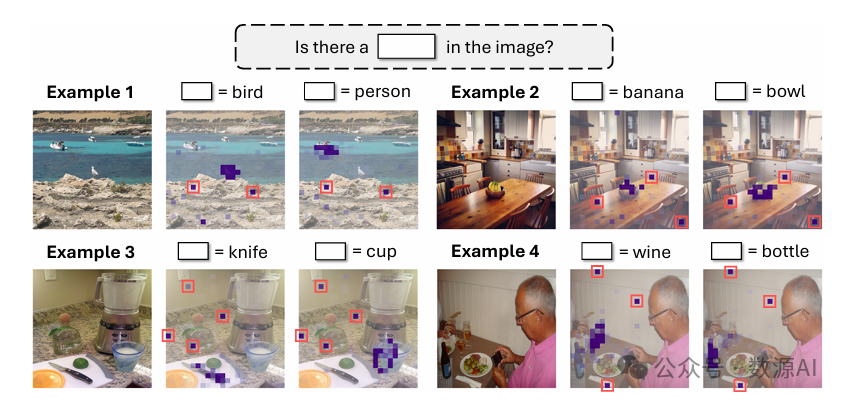
图2:大语言多模态模型(LMMs)典型架构及视觉注意力汇聚点研究示意图。一个大型多模态模型接收图像和文本作为输入。每个文本标记通过Transformer解码器中的注意力机制与视觉标记进行交互。我们可以以注意力图的形式将这种交互可视化。我们发现,注意力图中不相关的视觉标记(标记为红色框)在隐藏状态的特定维度上有大
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1821
1821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









