




🌐 社群导航
🔗点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
最新论文解读系列

论文名:Token-Efficient Long Video Understanding for Multimodal LLMs
论文链接:https://arxiv.org/pdf/2503.04130
开源代码:https://research.nvidia.com/labs/lpr/storm

导读
基于视频的多模态大语言模型(Video-LLM)的最新进展显著提升了人工智能系统理解和生成视频内容描述的能力。这些模型中常用的一种策略是将视频视为一系列单独的图像帧,使用图像编码器和视觉语言投影器独立处理每一帧。然后将得到的帧级表示输入到大语言模型(LLM)中,该模型进行时间推理以理解视频中所描绘的事件序列。
简介
基于视频的多模态大语言模型(Video-LLMs)的最新进展,通过将视频处理为图像帧序列,显著提升了视频理解能力。然而,许多现有方法在视觉主干网络中独立处理帧,缺乏显式的时间建模,这限制了它们捕捉动态模式和有效处理长视频的能力。为解决这些局限性,我们引入了STORM(面向多模态大语言模型的时空令牌缩减,Spatiotemporal TOken Reduction for Multimodal LLMs),这是一种新颖的架构,在图像编码器和大语言模型之间融入了一个专门的时间编码器。我们的时间编码器利用曼巴状态空间模型(Mamba State Space Model)将时间信息整合到图像令牌中,生成丰富的表示,这些表示能保留整个视频序列中的帧间动态。这种丰富的编码不仅增强了视频推理能力,还能实现有效的令牌缩减策略,包括测试时采样以及基于训练的时间和空间池化,在不损失关键时间信息的情况下,大幅降低了大语言模型的计算需求。通过整合这些技术,我们的方法在提高性能的同时,还能同时减少训练和推理延迟,实现了在长时间上下文下高效且稳健的视频理解。大量评估表明,STORM在各种长视频理解基准测试中取得了最先进的成果(在MLVU和LongVideoBench上提升超过5%),同时对于固定数量的输入帧,计算成本最多降低,解码延迟降低。
方法与模型
本节介绍基于曼巴(Mamba)的时间投影器架构,并引入几种用于高效长视频处理的令牌压缩技术。我们提出了两种令牌压缩方法:时间压缩和空间压缩。我们首先详细介绍我们的时间和空间池化策略,这些策略能在训练期间有效减少令牌数量。此外,我们提出了一种测试时的时间令牌采样方法,该方法无需额外的训练步骤即可保持模型性能。我们方法的概述如图2所示。
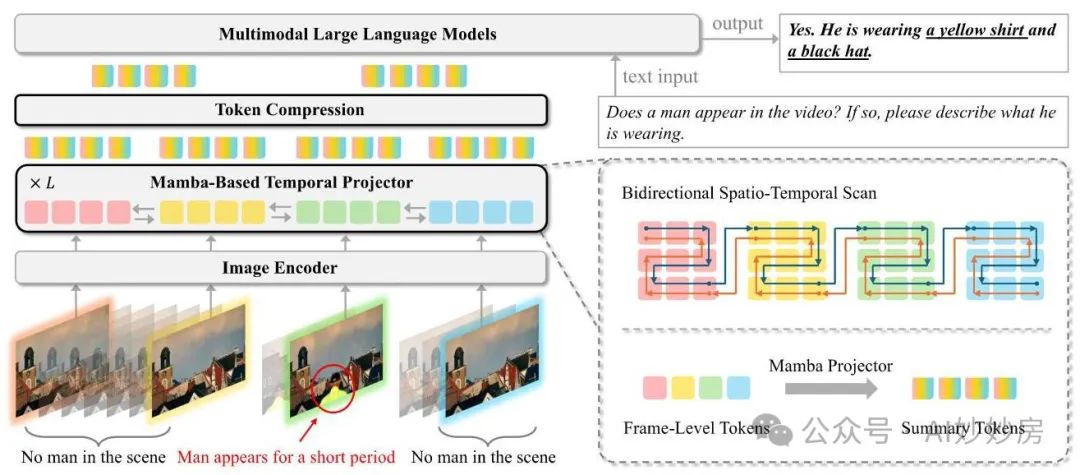
图 2 | STORM 流程概述。我们在图像编码器和大语言模型(LLM)之间提出了一个基于曼巴(Mamba)的时间投影器。该投影器弥合了视觉表示和语言表示之间的差距,同时将时间信息注入到标记中。处理后的标记(在图中表示为摘要标记)自然地捕捉了时间历史,有效地总结了视频的时间动态。这种能力使我们能够在不损失关键信息的情况下,减少用于大语言模型处理的视觉标记数量。
1. 预备知识
状态空间模型(SSMs
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









