 深度学习分布式训练详解:数据并行与模型并行
深度学习分布式训练详解:数据并行与模型并行





 本文总结了深度学习的分布式训练,包括数据并行和模型并行两种策略。数据并行通过将不同batch的数据分配给多个GPU,实现参数平均或异步随机梯度下降,加速训练。模型并行则是将复杂模型拆分,每个部分在独立GPU上运算,最后合并结果。这两种方法有效提升训练速度和模型收敛。
本文总结了深度学习的分布式训练,包括数据并行和模型并行两种策略。数据并行通过将不同batch的数据分配给多个GPU,实现参数平均或异步随机梯度下降,加速训练。模型并行则是将复杂模型拆分,每个部分在独立GPU上运算,最后合并结果。这两种方法有效提升训练速度和模型收敛。
分布式训练本质上是为了加快模型的训练速度,面对较为复杂的深度学习模型以及大量的数据。单机单GPU很难在有限的时间内达成模型的收敛。这时候就需要用到分布式训练。
分布式训练又分为模型并行和数据并行两大类。
1. 数据并行
数据并行在于将不同batch的数据分别交给不同的GPU来运算。如下图所示,灰色部分表示数据,蓝色表示模型。
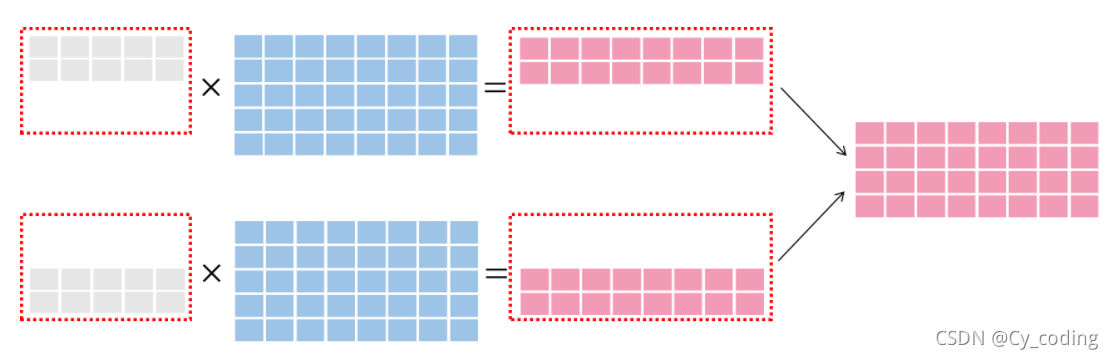
数据并行中的一类就是参数平均,比如将第一个Batch的256个数据交给第一个U
第二个batch的256个数据交给第二个U
参数平均就是在他们分别通过整个神经网络计算出结果后取平均值,再修改模型中的参数。这样实现实际上在不考虑多GPU与CPU的通信成本上,与单GPU以batchsize为512来进行训练是一样的,但因为同时进行了两个batch的运算,运算速度在理想情况下是线性增加的。参数平均同时也是一个同步更新的过程,多个GPU的运算结果会统一结束并计算平均参数,这在我们使用同算力GPU的时候可以做到效率最大化。
除了同步更新,我们还有异步随机梯度下降。这意味着不同的GPU不需要等待每一个epoch中所有GPU的运算完毕就可以直接更新参数。这很显然进一步提升了多个U的效率,因为我们不再需要保证多个GPU的同步性,更大加快了模型的收敛。但不可避免地是,由于异步的特点,当某一个GPU完成运算并更新参数的时候,可能这时候模型中的全局参数已经经过了多次的改变,这可能会导致绝对误差的放大,优化过程可能不稳定。
2. 模型并行
说完了数据并行,我们来看一下专门用于优化非常复杂的深度学习网络的模型并行。与数据并行不同的是,这次我们通过将模型拆分为几个小的部分,分别交给多个GPU来进行运算。每次仍然给每个模型一个batch的数据来进行计算,将多个GPU作为节点。最后将运算结果进行合并。实际上是一种将模型切割为几个子模型按顺序计算的过程。
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 36万+
36万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









