




 本文详细介绍了二元交叉熵作为损失函数在二分类问题中的应用。通过公式解释,展示了当标签为1和0时,如何根据预测概率计算损失。二元交叉熵能够有效地衡量模型预测的准确性,当预测与实际标签一致时损失最小,不一致时损失增大。通过对所有样本损失的平均,得到模型的整体损失。
本文详细介绍了二元交叉熵作为损失函数在二分类问题中的应用。通过公式解释,展示了当标签为1和0时,如何根据预测概率计算损失。二元交叉熵能够有效地衡量模型预测的准确性,当预测与实际标签一致时损失最小,不一致时损失增大。通过对所有样本损失的平均,得到模型的整体损失。
Binary cross entropy 二元交叉熵是二分类问题中常用的一个Loss损失函数,在常见的机器学习模块中都有实现。本文就二元交叉熵这个损失函数的原理,简单地进行解释。
首先是二元交叉熵的公式 :
Loss=−1N∑i=1Nyi⋅log(p(yi))+(1−yi)⋅log(1−p(yi)) Loss = - \frac{1}{N}\sum_{i=1}^{N}y_i \cdot \log(p(y_i)) + (1 - y_i) \cdot log(1-p(y_i)) Loss=−N1i=1∑Nyi⋅log(p(yi))+(1−yi)⋅log(1−p(yi))
其中,yyy 是二元标签 0 或者 1, p(y)p(y)p(y) 是输出属于yyy 标签的概率。作为损失函数,二元交叉熵是用来评判一个二分类模型预测结果的好坏程度的,通俗的讲,即对于标签y为1的情况,如果预测值p(y)趋近于1,那么损失函数的值应当趋近于0。反之,如果此时预测值p(y)趋近于0,那么损失函数的值应当非常大,这非常符合log函数的性质。
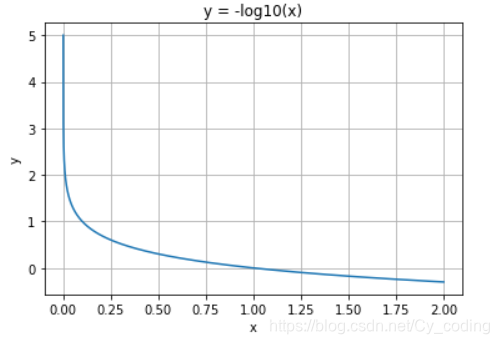
下面以单个输出为例子,在标签为 y=1y=1y=1 的情况下Loss=−log(p(y))Loss = -\log(p(y))Loss=−log(p(y)), 当预测值接近1时,Loss=0Loss = 0Loss=0, 反之 LossLossLoss 趋向于正无穷。
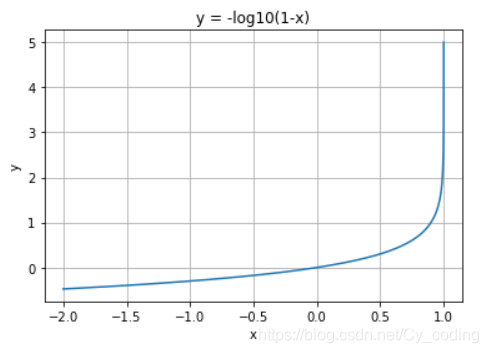
同样的单个输出为例,当标签 y=0y=0y=0时,损失函数 Loss=−log(1−p(y))Loss = -\log(1-p(y))Loss=−log(1−p(y)),当预测值接近0时,Loss=0Loss = 0Loss=0,反之LossLossLoss 趋向于正无穷。
之后,再对所有计算出的单个输出损失求和求平均,就可以求出模型针对一组大小为N的输出的Loss了。


















 2195
2195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









