



 本文介绍了如何借助CooVally平台快速实现多类型车辆检测。通过选择系统自带或上传的汽车检测数据,设置相关参数,进行模型训练和优化,最终实现高效准确的车辆检测。CooVally简化了模型筛选和部署过程,使得智能交通监控更加便捷。
本文介绍了如何借助CooVally平台快速实现多类型车辆检测。通过选择系统自带或上传的汽车检测数据,设置相关参数,进行模型训练和优化,最终实现高效准确的车辆检测。CooVally简化了模型筛选和部署过程,使得智能交通监控更加便捷。
如今,交通已经成为影响人们生活的重要因素之一。随着视频监控设备的发展,以及计算机图像处理技术,计算机视觉技术的不断提高,基于视觉的智能交通监控系统已经成为现代智能交通领域中的一项重要组成部分。
本文主要介绍了如何利用 CooVally快速实现多类型车辆检测。
CooVally限时特惠|花最少的时间,投最少的资金,开发最实用的AI系统
在开始之前,先说一下图像采集方法吧!图像采集方式分为静态与动态两种:
静态采集依靠地感线圈、红外或雷达等装置,当有车辆通过时这些装置时相机会接到一个触发信号,从而立刻抓拍一张图像,该方法的优点是触发率高,性能稳定,缺点是需要切割地面铺设线圈,施工量大。
动态采集则是在实时视频模式下进行,不需要其他感应装置给相机发送任何触发信号,完全依靠算法从实时的视频流图像中采集车辆信息,该方法的优点是施工方便,不需要安装其他感应装置或零部件。但其缺点也十分显著,由于算法的限制,动态采集的触发率与识别率较静态采集要稍低一些。
接下来就进入到我们的主题啦!肯定会有小伙伴发出疑问快速究竟是有多快?
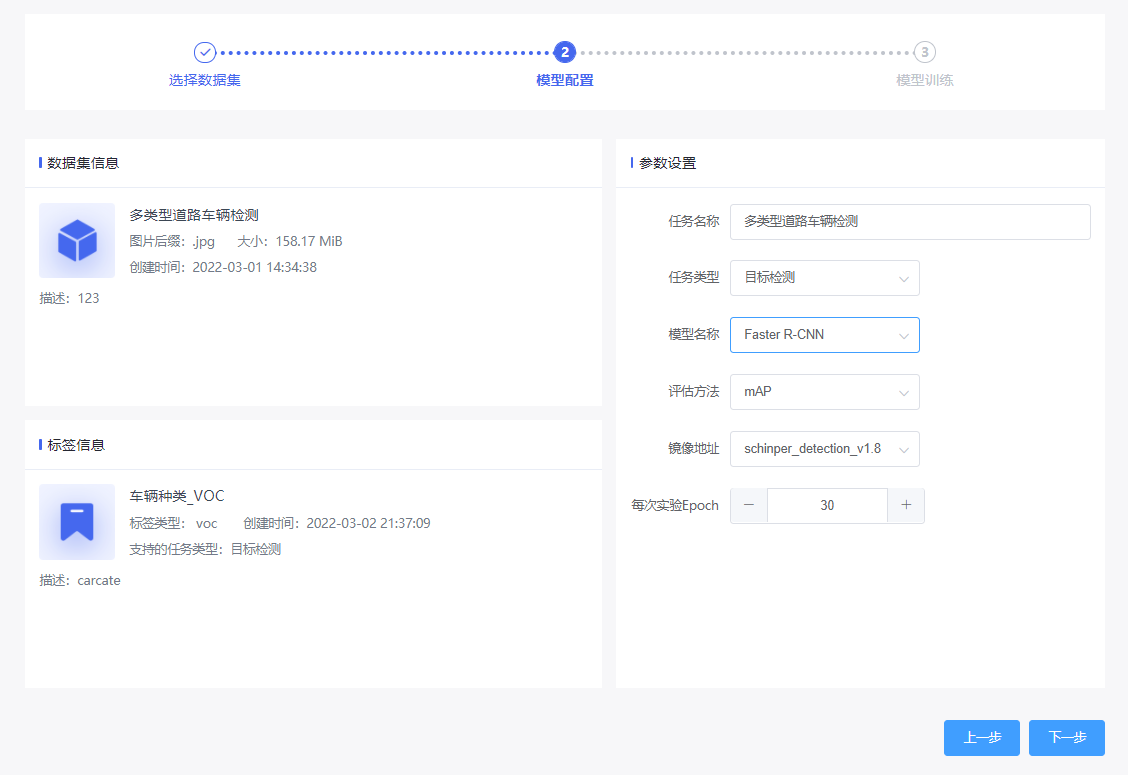
CooVally系统数据库中包含多种数据,我们可以选择系统自带的汽车检测数据,也可以上传自有数据。

点击需要使用的数据,然后根据需求选择对应的标签进行数据分析。

然后按照系统提示,一步一步设置参数。每次实验Epoch具体指代每一次实验中需要迭代的次数,根据自己需求设置。
接下来再设置好实验次数和并发次数就可以啦,并发次数具体指代需要几台服务器来训练。

当我们进入训练后,会跳转进入任务信息的详情页面,分为多个板块,每个板块都可以查看不同的信息,右上角还设置了网页自动刷新的时间,解放双手看数据!

在实验详情的页面,我们不仅可以查看实验结果,还有耗时等数据。
例如训练损失,训练损失越小,则会逐渐变为一条接近X轴的水平直线,那么训练的结果越好啦!

待训练结束,在训练列表中选择一个最好的训练结果进行部署并推理。(训练的次数越多,指标会越好哦~)

接下来,按照系统的提示进行模型部署,此时就已经进入尾声啦!

模型部署成功后,便可以上传图片,进行检测了。识别结果框框上面的数字,它的数值越接近1,准确率也就越高了。

简单快捷的多类型车辆检测模型就部署完成啦!
其检测原理是通过对大量的车辆图片模型的训练,然后可以检测出不同车辆的类型,而且训练的图片越多,检测结果越精准。
CooVally不仅内置了多种模型类型,而且还可以帮助用户快速筛选可用的AI模型,使用户不必浪费过多的时间在模型筛选上。
中奥智能工业研究院 https://www.sinoaus.net/CoovallyHome
https://www.sinoaus.net/CoovallyHome

1、邱玉。 智能交通中的视频车辆检测系统[D]。 吉林大学, 2014。

















 2999
2999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









